从零学习数据结构与算法---三、数组(Array)与链表
目录
一、 数组
1.1 优秀的随机查询或者下标访问
1.2 低效的插入和删除
1.3 删除优化方案
1.4 容器能否完全替代数组?ArrayList
二 、链表(Linked list)
2.1、简介
2.2、链表的特点
2.3、单向链表
2.4、循环链表
2.5、双向链表
三、链表 VS 数组性能大比拼
四、简单总结
数组和链表属于数据结构中的基础,是物理结构(数据结构的基础)。
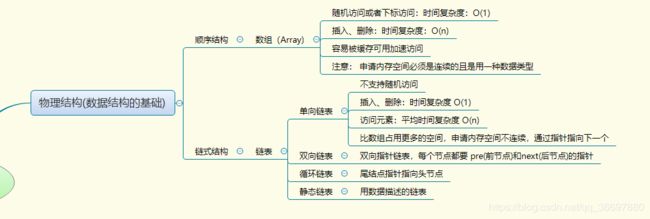
在学习前了解两个概念:线性表和非线性表
第一是线性表(Linear List)。顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。

第二是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。

一、 数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
1.1 优秀的随机查询或者下标访问
因是连续的内存空间、相同的数据,所以数组可以随机访问,但对数组进行删除插入,为了保证数组的连续性,就要做大量的数据搬移工作。
纠正数组和链表的错误认识。数组的查找操作时间复杂度并不是O(1)。即便是排好的数组,用二分查找,时间复杂度也是O(logn)。
正确表述:数组支持随机访问,根据下标随机访问的时间复杂度为O(1)
1.2 低效的插入和删除
1) 插入:从最好O(1) 最坏O(n) 平均O(n)
2) 插入:数组若无序,插入新的元素时,可以将第K个位置元素移动到数组末尾,把心的元素,插入到第k个位置,此处复杂度为O(1)。作者举例说明
3) 删除:从最好O(1) 最坏O(n) 平均O(n)
1.3 删除优化方案
多次删除集中在一起,提高删除效率
记录下已经被删除的数据,每次的删除操作并不是搬移数据,只是记录数据已经被删除,当数组没有更多的存储空间时,再触发一次真正的删除操作。即JVM标记清除垃圾回收算法。
1.4 容器能否完全替代数组?ArrayList
相比于数字,java中的ArrayList封装了数组的很多操作,并支持动态扩容。一旦超过村塾容量,扩容时比较耗内存,因为涉及到内存申请和数据搬移。
那ArrayList与数组相比,到底有哪些优势呢?
ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容。数组本身在定义的时候需要预先指定大小,因为需要分配连续的内存空间。如果我们申请了大小为 10 的数组,当第 11 个数据需要存储到数组中时,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入。如果使用 ArrayList,我们就完全不需要关心底层的扩容逻辑,ArrayList 已经帮我们实现好了。每次存储空间不够的时候,它都会将空间自动扩容为 1.5 倍大小。不过,这里需要注意一点,因为扩容操作涉及内存申请和数据搬移,是比较耗时的。所以,如果事先能确定需要存储的数据大小,最好在创建 ArrayList 的时候事先指定数据大小。
数组适合的场景:
- 1) Java ArrayList 的使用涉及装箱拆箱,有一定的性能损耗,如果特别管柱性能,可以考虑数组
- 2) 若数据大小事先已知,并且涉及的数据操作非常简单,可以使用数组
- 3) 表示多维数组时,数组往往更加直观。
- 4) 业务开发容器即可,底层开发,如网络框架,性能优化。选择数组。
二 、链表(Linked list)
2.1、简介
1.和数组一样,链表也是一种线性表。
2.从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构。
3.链表中的每一个内存块被称为节点Node。节点除了存储数据外,还需记录链上下一个节点的地址,即后继指针next。
2.2、链表的特点
1.插入、删除数据效率高,时间复杂度为O(1)级别(只需更改指针指向即可),随机访问效率低,时间复杂度O(n)级别(需要从链头至链尾进行遍历)。
2.和数组相比,内存空间消耗更大,因为每个存储数据的节点都需要额外的空间存储后继指针。
从图中我们可以看出,针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。
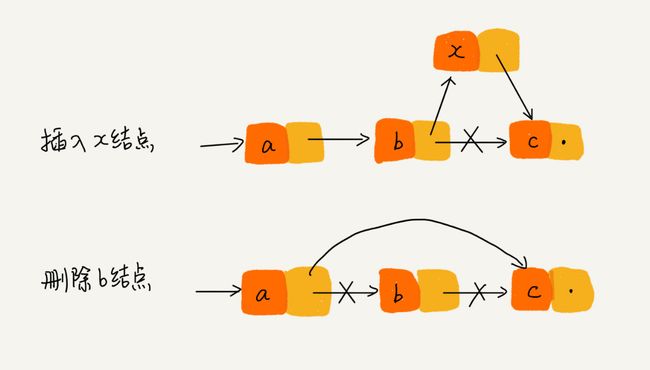
访问数据我们就需要从第一个人开始,一个一个地往下数。所以,链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
2.3、单向链表
链表结构五花八门,今天我重点给你介绍三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。我们首先来看最简单、最常用的单链表。
链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,我们把这个记录下个结点地址的指针叫作后继指针 next。
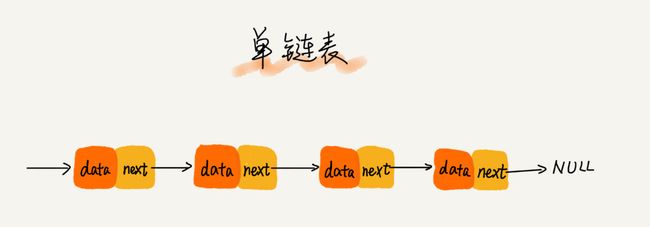
有两个结点是比较特殊的,它们分别是第一个结点和最后一个结点。我们习惯性地把第一个结点叫作头结点,把最后一个结点叫作尾结点。其中,头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。而尾结点特殊的地方是:指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
2.4、循环链表
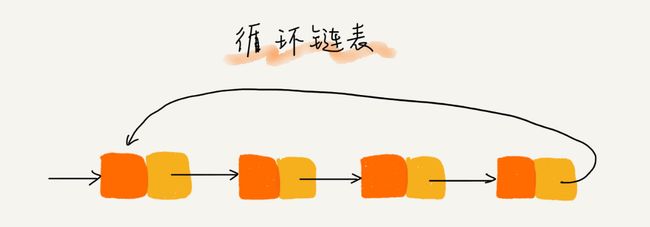
循环链表是一种特殊的单链表。实际上,循环链表也很简单。它跟单链表唯一的区别就在尾结点。我们知道,单链表的尾结点指针指向空地址,表示这就是最后的结点了。而循环链表的尾结点指针是指向链表的头结点。从我画的循环链表图中,你应该可以看出来,它像一个环一样首尾相连,所以叫作“循环”链表。
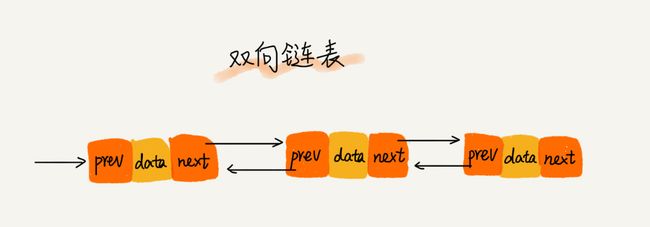
2.5、双向链表
在实际的软件开发中,也更加常用的链表结构:双向链表。
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表,顾名思义,它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
首节点的前驱指针prev和尾节点的后继指针均指向空地址。
性能特点:
和单链表相比,存储相同的数据,需要消耗更多的存储空间。
插入、删除操作比单链表效率更高O(1)级别。以删除操作为例,删除操作分为2种情况:给定数据值删除对应节点和给定节点地址删除节点。对于前一种情况,单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。对于第二种情况,要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
对于一个有序链表,双向链表的按值查询效率要比单链表高一些。因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
java中的双向链表LinkedHashMap 这个容器。如果你深入研究 LinkedHashMap 的实现原理,就会发现其中就用到了双向链表这种数据结构。
实际上,这里有一个更加重要的知识点需要你掌握,那就是用空间换时间的设计思想。当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
三、链表 VS 数组性能大比拼
数组和链表是两种截然不同的内存组织方式。正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。

数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。
四、简单总结
数组和链表是两种常见的线性数据结构。他们各自的优缺点如下:
链表:
- 插入删除速度快
- 内存利用率高,不会浪费内存
- 大小没有固定,拓展很灵活
- 不能随机查找,必须从第一个开始遍历,查找效率低
数组:
- 随机访问性强,查找速度快
- 插入和删除效率低
- 内存空间要求高,必须有足够的连续内存空间,可能浪费内存
- 数组大小固定,不能动态拓展