计算机视觉--算法与应用 笔记(实时更新)
这么厚的一本书急功近利肯定是不行的,从今天开始每天看一部分,不要畏难不要畏难不要畏难!!!今天是4月16日
每天看的部分记录一下笔记。
4_16
光学字符识别ORC(Optical Character Recognition)
数学概念
半正定矩阵:
设A是n阶方阵,如果对任何非零向量X,都有X’AX≥0,其中X‘'表示X的转置,就称A为半正定矩阵。
性质:
1.半正定矩阵的行列式是非负的。
2.两个半正定矩阵的和是半正定的。
3.非负实数与半正定矩阵的数乘矩阵是半正定的
特征分解:特征分解(Eigendecomposition),又称谱分解(Spectral decomposition)是将矩阵分解为由其特征值和特征向量表示的矩阵之积的方法。需要注意只有对可对角化矩阵才可以施以特征分解。
A = QΛQ^T
其中A是N*N方阵,Q是特征向量组成的N * N方阵,Λ是对角元是特征值的对角矩阵
理解:特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
奇异值分解(SVD):相对于特征分解,奇异值分解不要求矩阵是方阵,奇异值分解是一个能适用于任意的矩阵的一种分解的方法

这里贴一下大佬关于特征分解和奇异值分解的讲解,mark
https://blog.csdn.net/ningyaliuhebei/article/details/7104951
**理解:**总的来说利用三角分解可以把一个高维度的复杂的矩阵分成简单的矩阵,特征向量就是某一个变化的方向,理解为特征(这样特征向量都是正交的也好理解了,就是他们代表不同的变化方向,然后一同组成了整个特征空间),然后特征值则表示伸缩的长度,就是说可以理解为每个特征值对应的影响程度。所以一个矩阵的分解就可以看作是提取重要特征的方法(感觉就像是求出了一个线性空间的一组正交基?)
齐次坐标怎么感觉好难理解
但是只考虑成极坐标的时候又感觉没什么问题… mark一下
http://www.doc88.com/p-7157359295783.html
规范化齐次直线方程 看起来就像极坐标方程了
2D变换
数学基础差伤不起啊…看了好久才弄明白 x-是增广向量,x~是齐次向量,然后前面乘上变换矩阵就能实现向量的变换了,具体看计算机视觉课本30页
还有齐次坐标这点真是一脸懵逼啊。。
坐标轴平移思路
首先找到移动后的坐标原点在原坐标轴的坐标(w,h),然后根据公式
x’ = x-w
y’ = y-h
进行平移,得到的就是原坐标轴上的点在移动后坐标轴的坐标了,如果还发生了x轴或者y轴的反向
那么就对整体乘上-1即可 比如y轴变为原来的反向
就变成了
y’ = -(y-h) = -y+h
远心镜头
远心镜头(Telecentric),主要是为纠正传统工业镜头视差而设计,它可以在一定的物距范围内,使得到的图像放大倍率不会变化,这对被测物不在同一物面上的情况是非常重要的应用。
视差
视差就是从有一定距离的两个点上观察同一个目标所产生的方向差异。从目标看两个点之间的夹角,叫做这两个点的视差角,两点之间的连线称作基线。只要知道视差角度和基线长度,就可以计算出目标和观测者之间的距离。
发现第二章各种推导看不懂。。。然后各种去查,后来发现需要补一下《计算机图形学》的相关知识,涉及齐次坐标,坐标转换,投影等。
顺便Mark一下相机的世界坐标系、图像坐标系、像素坐标系、相机坐标系的关系
https://blog.csdn.net/chentravelling/article/details/53558096
镜头畸变
书里主要涉及了径向畸变,就是图像坐标按照其径向距离的一定比例偏离(桶形失真)或朝向(枕形失真)
这里主要记一下畸变参数
终于要进入正题了,心累啊
今日份的笔记 4_19
彩色空间
颜色模型 RGB YUV YCbCr BAYer
Gamma 效应,是指图像亮度和电压非线性,所以需要gamma校正
上面是第二章的内容,全是数学表达有点头疼,偶尔看看吧
下面开始进入 数字图像处理部分?
1)点处理(对每个点单独处理,不依赖临域,那就是只能改变一下图像的亮度 对比度了)
像素变换常用点算子 增益参数和偏差参数(对比度和亮度) 线性混合算子
合成与扣图
直方图
直方图均衡化(找一个映射,让映射完的直方图是平坦的)
局部自适应直方图均衡化(会产生区块效应,块的边界处亮度不连续)
消除人为区块效应,移动窗口方法(对每个点为中心的M*M的方框重新做直方图均衡化,然后重新赋值,沃日这个时间复杂度。。。但是可以加速,只考虑每次移动的增减,不用从头计算)
自适应直方图均衡化
数字图像处理形态学图像处理部分
发现数字图像处理的部分知识忘的差不多了,这两天赶快补了一下,记一些常见的理论和方法,主要是形态学图像处理部分
腐蚀:让原本位于图像原点的结构元素S在整个Z^2平面上移动,如果当S的原点平移至z点时S能够完全包含于A中,则所有这样的z点构成的集合即为S对A的腐蚀图像
膨胀:设想有原本位于图像原点的结构元素S,让S在整个Z^2平面上移动,当其自身原点平移至Z点时S相对于其自身的原点的映像 S ^和A有公共的交集,即S ^和A至少有1个像素是重叠的,则所有这样的Z点构成的集合为S对A的膨胀图像(这个地方注意是自身原点的映像,不是自己,我刚开始就搞错了)
开运算:先腐蚀后膨胀,可以使图像的轮廓变得光滑,还能使狭窄的连接断开和消除毛刺
闭运算:先膨胀后腐蚀,也可以使图像的轮廓变得光滑,他能弥合狭窄的间断,填充小的孔洞
边界提取:先用33的结构元素腐蚀,然后用原图像减去腐蚀后的图像就得到了边界
边界跟踪:按照从左到右,从上到下的顺序扫描图像,就能找到目标物体最上方的边界点P0,然后从左下方开始探查,如果遇到物体点直接跟踪,否则探查方向沿逆时针旋转45度,直到找到目标点,然后跟踪此边界点。找到边界点后,在当前探查方向的基础上顺时针回转90度,继续用上述方法搜索下一个边界点,直到回到P0,就完成了整条边界的跟踪
区域填充:边界提取的反过程,它是在边界已知的情况下得到边界包围的整个区域的形态学技术,首先要知道4连通区域围成的内部区域是8连通的,8连通区域围成的内部区域是4连通的。对4连通区域使用33结构元素,8连通区域使用十字结构元素进行膨胀,并且保持中心在图像内部(不包含边界点),每次膨胀的结果和边界的补 相交,最后得到的图像和原图的并集就是结果。
提取连通分量:设A有两个连通分量A1,A2,用3*3的结构元素进行膨胀,保证它在A1内,最后膨胀的结果和原图A1求交,就得到了连通分量A1
细化算法:细化算法讲解:这里用到的是zhang细化算法,感觉网上关于它的信息好少并且总结的不到位,又是原图像又是临时图像的讲的莫名其妙。还是要看伪码才能明白。
zhang细化算法的思路是,遍历每一个像素点,并且考虑这是奇数次还是偶数次迭代,奇数次和偶数次的满足条件是不一样的,都是四个条件(分为奇偶的原因有人说是防止同时删除导致连通区域断开),比如首先第一次迭代,对应奇数的条件,满足条件的点被标记为删除点(注意这里不能删除,而是标记出来,等到该次遍历完成再删除),直到遍历完成,删掉这些点。然后开始新的迭代,这时是第二次迭代,是偶数次,因此对应偶数次的4个条件,同样标记出来,遍历完成,删除这些点,然后继续奇数、偶数、奇数、偶数迭代,最后输出的结果就是细化的结果。
这是zhang细化算法的伪码
Zhang-Suen thinning steps:
While points are deleted do
For all pixels p(i,j) do
if (a)2 ≤ B(P1) ≤ 6
(b) A(P1) = 1
(c) Apply oneof the following:
1. P2 x P4 x P6 = 0 in odd iterations
2. P2 x P4 x P8 = 0 in even iterations
(d) Apply oneof the following:
1. P4 x P6 x P8 = 0 in odd iterations
2. P2 x P6 x P8 = 0 in even iterations
then
Deletepixel p(i,j)
endif
end for
end while
像素化算法
凸壳算法
数字图像处理图像分割部分
边缘检测步骤:平滑滤波(去除噪声)、锐化滤波、边缘判定(二值化、过零检测)、边缘连接(Hough变换)
边缘检测算法:(给予查找的算法、基于零穿越的算法、canny边缘检测算法、统计判别方法等)
常用边缘检测算子:
梯度算子(Roberts):利用局部查分算子寻找边缘,边缘定位精度较高,但是容易丢失一部分边缘,由于没有经过平滑处理,因此不具备抑制噪声的能力,该算子对具有陡峭边缘且含噪声小的图像效果好
是一维偏导数的边缘算子,令gx ,gy 表示偏导数,例如:gx = f(x+1,y)-f(x,y), gy = f(x,y+1) - f(x,y)

或者是二维的 这种是 gx = f(x+1,y+1) - f(x,y) gy = f(x+1,y) - f(x,y+1)
也就是左上角是f(x,y),离散值的偏导数就用差分

Sobel算子、Prewitt算子
这些也是一阶导数边缘算子,但是它们考虑的临域信息,相当于对图像先做了加权平滑,再做微分运算,对噪声有一定的抑制能力,但是不能完全排除检测结果中的虚假边缘,这两个算子边缘定位效果不错,但是检测出的边缘容易出现多像素宽度。
sobel算子

Prewitt算子

高斯-拉普拉斯算子(LoG):二阶微分算子,也称Marr边缘检测算子,形如草帽也叫墨西哥草帽滤波器,在使用拉普拉斯算子之前先进行了高斯低通滤波,克服了拉普拉斯算子抗噪声能力比较差的缺点,但在抑制噪声的同时也可能将原有的比较尖锐的边缘也平滑掉了,造成这些尖锐边缘无法被检测到。
LoG算子,考虑物理含义是先进行高斯滤波,然后求二阶偏导数(就是拉普拉斯算子),由于线性系统中微分和卷积的次序可交换,就等价于先对高斯滤波器求二阶偏导,然后再与图像卷积(这是具体计算过程),所以LoG算子就是高斯滤波的二阶导数形式,常用的LoG算子是5*5的模板,长这样

提到这就顺便提一下高斯滤波,它就是高斯公式,均值为0,方差在matlab里默认取0.5,一般常用的有3 * 3高斯模板,方差一般取0.8
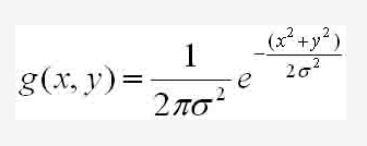
对于图像,像素点是离散的,构造高斯模板的方法是下图公式,对于建立(2k+1)(2k+1)的矩形模板,那么中心点是(0,0),第(i,j)个点的值通过下式算出。
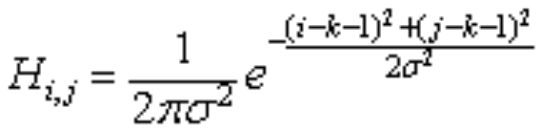
Canny边缘检测算子:首先对图像选择一定的高斯滤波器进行平滑滤波,然后采用非极值抑制技术进行处理得到最后的边缘图像
提出了边缘检测的标准:
1)以低的错误率检测边缘,也即意味着需要尽可能准确的捕获图像中尽可能多的边缘。
2)检测到的边缘应精确定位在真实边缘的中心。
3)图像中给定的边缘应只被标记一次,并且在可能的情况下,图像的噪声不应产生假的边缘。
canny边缘检测步骤为:
1)用高斯滤波平滑图像
2) 用一阶偏导的有限差分来计算梯度值和方向
3)对梯度幅值进行非极大值抑制
4)用双阈值算法检测和连接边缘
canny边缘检测详解
霍夫变换:是一个非常重要的检测间断点边界形状的方法,他通过将图像坐标空间变换到参数空间,实现直线和曲线的拟合
我自己的理解就是,对于笛卡尔坐标空间的某点(x0,y0)和通过它的直线y=ax+b,那么在这条直线上的所有点(x,y)都可以看作是参数(a,b)对应的点,就想象成参数(a,b)对应的所有点在笛卡尔空间上画出来是条直线,那么反过来,考虑a,b所在的参数空间,每一个(x,y)都对应了许多的(a,b),画出来就是另一条曲线(如果是y=ax+b画出来是一条直线,如果是y=acos +b*sin这种形式,画出来是一条曲线)这些(x,y)如果在笛卡尔空间上在一条直线上,那么肯定有一个(a,b)满足参数空间上所有线同时成立的条件,就是参数空间这些线的交点处。那么可能有很多个交点,因为边缘线是杂乱的不会正好是完美的直线,所以会有很多个相近的交点,这个时候就把这些交点拿来投票,投票最多的(就是交点最多的)对应的那个(a,b)就是笛卡尔空间上直线的参数了。
这是参考大神的霍夫变换详解,贴一下
阈值分割:利用灰度阈值变换分割图像
阈值分割方法:
1)实验法
2)根据直方图谷底确定阈值
3)迭代选择阈值法:先确定一个初始阈值T,把图像分为两个区域,然后分别计算两个区域的平均灰度u1,u2,再计算新的阈值
T=1/2(u1+u2),然后迭代上面的过程,直到所得的T值小雨事先定义的参数T
4)最小均方误差法
5)最大类间方差法(大津算法OTSU)最常用,最稳定的方法,思路也很简单,遍历找到使得被阈值T分开的区域的平均灰度的方差最大的T
区域分裂
特征提取
区域描绘子:周长、面积、致密性、区域的质心、灰度均值、灰度中值、包含区域的最小矩形、最小或最大灰度级、大于或小于均值的像素数、欧拉数
直方图及其统计特征:描绘纹理
常用的直方图统计特征:均值、标准方差、平滑度、三阶矩、一致性、熵
灰度共现矩阵:描述某种空间位置关系的两个像素的联合分布
特征降维:两种方法 特征选择和特征抽取
主成分分析法(PCA):找到了一个特别好的讲PCA的博文,浅显易懂。
协方差、相关系数讲解:
想掌握PCA,不懂协方差、相关系数怎么行,这有一篇大神讲解的超好懂的协方差、相关系数的讲解,mark一下
PCA同时也要掌握以下如何进行理论论推导再附上PCA推导
对于推导过程,看到了物理含义和数学求解的统一性,对于特征降维,思想是用低维特征表示最多的信息,那么不同维度之间的协方差为0的时候说明它们不相关,意味着表述的信息没有冗余,而在PCA最优化问题求解的时候(目标函数为散度,约束条件为相似变换矩阵为单位矩阵即模为1),通过拉格朗日乘子法,求得了导数为0时,相似变换矩阵取得了一组特征向量,物理含义和数学求解高度统一。
局部二进制模式(LBP):一种有效的纹理描述算子,对图像局部纹理特征有卓越的描绘能力,并且对于单调的灰度变化具有不变性
图像特征提取三大法宝:HOG特征,LBP特征,Haar特征
之前一直感觉做模式识别一直云里雾里的不知道什么意思,学了一些基本的机器学习方法也不知道怎么用,比如svm之类的,最近感觉越来越有体会了,感觉模式是别主要就是两个部分,一个特征提取和一个分类器的分类,分类器有很多(详见机器学习,如SVM、感知机等),特征提取也很多方法,甚至可以自己提取,比如最简单的图章识别,就是自己手动点的一些点取了RGB就是特征,也可以用一些别人用了都说好的特征,比如HOG、LBP等等,最后得到的无非就是一些矢量(特征向量),然后扔给分类器拿去分类就好,道理就这么简单,剩下的就是如何编程实现的问题,当然深度学习不太一样,相当于分类器还帮你做了特征提取的工作