python爬虫三(bs4,xpath解析)
数据解析器:
我们前面都是爬的整个页面。全是处理的后台偷偷ajax请求而来的数据包,因为是ajax请求,返回数据基本都是json格式,可以直接用json()拿:
像这样:
requetss.get('https://www.sogou.com/websearch/api/getcity').json()
如果想要的不是json数据,而是整个页面的数据,就用content.decode(),所以要讲如何提取数据,目前只知道通过正则来提取页面中想要的值,比如前面拿src2(很多图片网站都是用的伪属性懒加载)。
为什么需要在爬虫中使用数据解析器?其实就是为了实现聚焦爬虫,说白了正则也是为了实现聚焦爬虫。
常见的解析器就是:正则,bs4,xpath(用的最多),pyquery(基于jquery的选择器,用的很少)
它们的通用原理可以总结为八个字:
“标签定位,数据提取”
一、bs4数据解析原理
pip install bs4
pip install lxml
1、实例化一个BeautifulSoup的对象,且将等待被解析的数据(str_html)加载到该对象中。
# 方式一: 解析本地存储的htnl文件
BeautifulSoup(f,'lxml')
# 方式二:解析互联网上请求的数据
BeautifulSoup(str_html,'lxml')
2、调用这个对象中的相关方法和属性进行标签定位和数据提取。
取属性,string和text的区别就是string只能拿到p标签中的字符串,而text可以拿到p标签中及p的子标签中的字符串。
from bs4 import BeautifulSoup
f = open(r"./python.html","r",encoding="utf8")
soup = BeautifulSoup(f,'lxml')
# 只能返回第一个出现的p标签
soup.p
# 1、soup.find('p',id=1)
soup.find('p',class_='a') # 加_是为了防止class转义,不加_会报错
# 2、和find用法一样,只不过findAll是定位所有满足条件的标签组成的列表,find是第一个
soup.findAll('p',class_='a')
# 3、选择器select(只看id和class,选择器规则跟jquery一样)
soup.select('.a') # soup.select('#1')
# 层级选择器,大于号表示一个层级(class等于a下的ul标签下的li下的a标签)
soup.select('.a > ul > li > a')
# 空格表示多个层级,这个跟上一行的差别就是精确性
soup.select('.a a')
# 取属性,string和text的区别就是string只能拿到p标签中的字符串,
# 而text可以拿到p标签中及p的子标签中的字符串
soup.p.string
soup.a.text
# 取属性值,class等于"a"的p标签的href属性对应值
soup.find('p',class_="a")['href']
案例:使用bs4解析爬取三国演义整篇小说内容。
http://shicimingju.com/book/sanguoyanyi.html
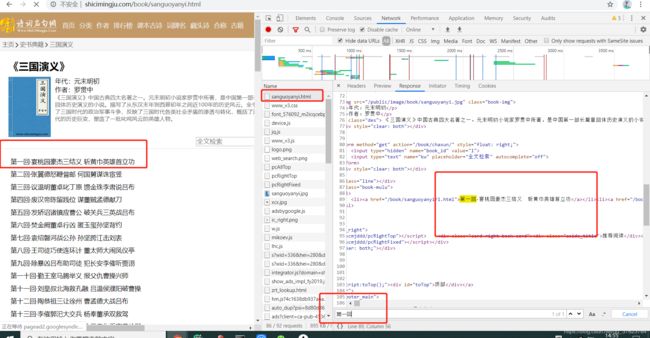
一样的,先判断该页面是否是动态加载的数据,发现不管是三国首页还是详情页都不是ajax生成,直接爬该页和对应详情页来解析即可拿到章节名和对应内容,不需要像前面一样全局找ajax动态请求的包。
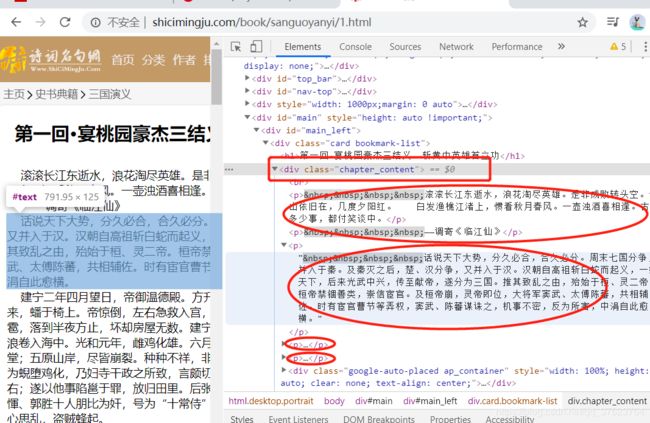
url = 'http://shicimingju.com/book/sanguoyanyi.html'
str_html = requests.get(url,headers=headers).content.decode()
soup = BeautifulSoup(str_html,'lxml')
a_list = soup.select('.book-mulu > ul > li > a')
for a in a_list:
title = a.text
detail_url = "http://shicimingju.com" + a['href']
detail_str = requests.get(url=detail_url,headers=headers).content.decode()
# 对详情页进行解析
soup = BeautifulSoup(detail_str,'lxml')
content = soup.find('div',class_='chapter_content').text
# 保存
path = r"../三国演义/{}.txt".format(title)
with open(path,'w',encoding="utf8") as f:
f.write(content)
print("下载{}成功".format(title))
结果:

xpath解析:
pip install lxml
1、实例化一个etree对象,且将待解析的数据加载进对象。
# 方式一:解析本地html
etree.parse('filePath')
# 方式二:解析网上爬取的html
etree.HTML(page_text)
2、使用etree对象中的xpath方法结合着xpath表达式实现定位和提取功能:
首先xapth解析简单,然后浏览器上可以直接copy某个标签的xpath表达式,所以我就不说了,但是注意xpath的/text()和//text(),跟bs4的string和text同理
实战:抓该网站的妹子图加每张图的名称
http://pic.netbian.com/4kmeinv/
先判断:发现该网站图片没有ajax动态加载,更没有懒加载(判断方法是elements中往下有点,看图片属性是不是src):
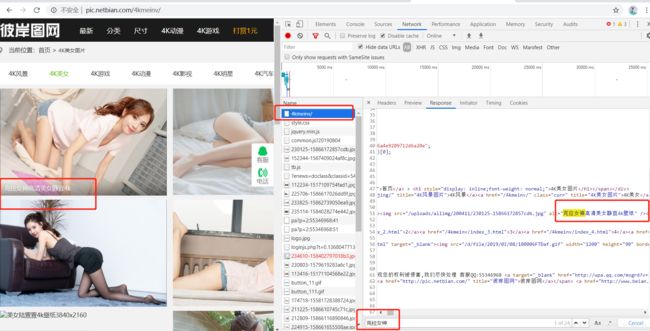
代码:
import os
dir = "../妹子图"
if not os.path.exists(dir):
os.mkdir(dir)
# 只抓取的前两页的妹子
for page in range(1,3):
if page == 1:
url = "http://pic.netbian.com/4kmeinv/"
else:
url = 'http://pic.netbian.com/4kmeinv/index_{}.html'.format(page)
res_str = requests.get(url,headers=headers).content.decode('gbk')
tree = etree.HTML(res_str)
# 全局解析
li_list = tree.xpath('//ul[@class="clearfix"]/li')
for li in li_list:
# ./局部的数据解析,因为li也是elements对象
img_url = 'http://pic.netbian.com/'+li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
# 向图片url发起请求
img = requests.get(url=img_url,headers=headers).content
path = r'{}/{}'.format(dir,img_name)
with open(path,'wb') as f:
f.write(img)
print(img_name + '下载成功')
结果:
只要页数上了五页,都要等个20秒左右,如果业务量上来爬一万张图片的话可能要等很久,后面会跟着介绍异步爬取的方法(一是手写asyncio实现协程二是scrapy实现多线程,甚至后面还会用到分布式更快),提升爬取效率。
xpath表达式的合并:
https://www.aqistudy.cn/historydata/
老规矩,先看是否有ajax动态加载:直接锁XHR,发现别说动态加载,开启抓包点击刷新页面连ajax请求都没有:
代码:
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url,headers=headers).content.decode()
tree = etree.HTML(response)
# 热门城市名
hot_city_list = tree.xpath('//div[@class="bottom"]/ul[@class="unstyled"]/li/a/text()')
# 全部城市名
all_city_list = tree.xpath('//div[@class="bottom"]/ul[@class="unstyled"]/div[2]/li/a/text()')
print("热门城市:\n{}".format(hot_city_list))
print("全部城市城市:\n{}".format(all_city_list))
上面写了两个xpath的表达式,一个是拿热门城市一个是拿全部城市,那这两个xpath可以合并吗?好处是什么?
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url,headers=headers).content.decode()
tree = etree.HTML(response)
hot_and_all_city_list = tree.xpath('//div[@class="bottom"]/ul[@class="unstyled"]/li/a/text() | //div[@class="bottom"]/ul[@class="unstyled"]/div[2]/li/a/text()')
print("热门城市和全部城市:\n{}".format(hot_and_all_city_list))
当你想在同一个页面爬不同类型的数据时,合并两个xpath的好处就是,让xpath具有通用性(管道符表示或),这个不行再来这个,合并xpath是不会提升解析速度的哈。当然结果跟不合并是一样的:

面试题:
如何解析出页面上指定的带标签的数据。题意首先你要明白,我要拿页面上这样的数据:
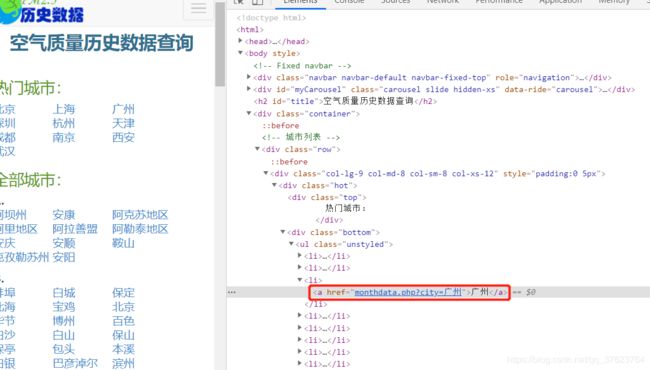
很显然,你要拿整个标签,肯定用bs4啊,bs4就是返回整个标签,如下图:用findAll方法,还可以指定获取哪个属性(class_=xxx 或者id=xxx)的a标签,另外我又用xpath做了个对比,xpath只要你不定位到确切属性(/text,@src,@href),返回的永远是个elements列表。
