kafka全操作精讲
kafka基本操作
如下是在${KAFKA_HOME}/bin/目录下所有kafka自带脚本

启动关闭kafka集群
我用的Ambari进行管理,如果是自己搭建的全分布集群,则可以用如下kafka-cluster-start.sh或kafka-cluster-stop.sh脚本进行所有brokers启动关闭,实际上就是循环所有broker执行kafka-server-start/stop.sh脚本
#启动 Kafka 集群的脚本代码 kafka-cluster-start.sh
#!/bin/bash
brokers="server-1 server-2 server-3"
KAFKA_HOME="/usr/local/software/kafka/kafka_2.11-1.1.0"
echo "INFO:Begin to start kafka cluster..."
for broker in $brokers
do
echo "INFO:Start kafka on ${broker} ..."
ssh ${broker} -C "source /etc/profile; sh ${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties"
if [ $? -eq 0 ]; then
echo "INFO:[${broker}] Start successfully"
fi
done
echo "INFO:Kafka cluster starts successfully"
#关闭 Kafka 集群的脚本代码 kafka-cluster-stop.sh
#!/bin/bash
brokers="server-1 server-2 server-3"
KAFKA_HOME="/usr/local/software/kafka/kafka_2.11-1.1.0"
echo "INFO:Begin to shutdown kafka cluster..."
for broker in $brokers
do
echo "INFO:Shutdown kafka on ${broker} ..."
ssh ${broker} -C "${KAFKA_HOME}/bin/kafka-server-stop.sh"
if [ $? -eq 0 ]; then
echo "INFO:[${broker}] Shutdown completed"
fi
done
echo "INFO:Kafka cluster Shutdown completed"
解析:ssh登陆$brokers中的所有节点,并执行每一个节点中的${KAFKA_HOME}/bin/kafka-server-start.sh脚本或者${KAFKA_HOME}/bin/kafka-server-stop.sh
注意:将此脚本(kafka-cluster-start.sh或者kafka-cluster-stop.sh)放在任意一个节点。并给该文件赋权
chmod +x kafka-cluster-start.sh #授予可执行权限
chmod +x kafka-cluster-stop.sh #授予可执行权限
当然你也可以一个一个节点的启动
注意:可以看到,启动时必须注意后面要加上server.properties配置文件的路径
kafka-server-start.sh -daemon ../conifg/server.properties
查看KafkaServer启动日志
kafka首次启动成功后会在${KAFKA_HOME}/logs目录下创建相应的日志文件,如下表所示。
同时会在$log.dir目录下创建相应的文件
| logs name | introduction | default log level |
|---|---|---|
| controller.log | KafkaController运行时日志 | TRACE |
| kafka-authorizer.log | Kafka权限认证相应操作日志 | WARN |
| kafka-request.log | Kafka相应网络请求日志 | WARN |
| kafkaServer-gc.log | Kafka运行过程中,进行GC操作时的日志 | INFO |
| log-cleaner…log | Kakfa日志清理操作相关统计信息 | INFO |
| server.log | KafkaServer运行日志 | INFO |
| state-change.log | Kafka分区角色切换等状态转换日志 | TRACE |
cd $KAFKA_HOME/logs
tailf server.log
登陆ZK客户端查看目录结构
$ZOOKEEPER_HOME/bin/zkCli.sh -server
ls /
ls /brokers
ls /brokers/ids ##查看全部的Kafka代理节点 broker_id
在kafka启动前只有一个zookeeper目录节点,Kafka启动后目录节点如下

查看Kafka的日志存放目录及格式
Segment 是kafka文件存储的最小单位
segment日志存放目录查看方法如下
cat ${KAFAK_HOME}/config/server.properties
搜索log.dirs参数

进入到日志目录查看
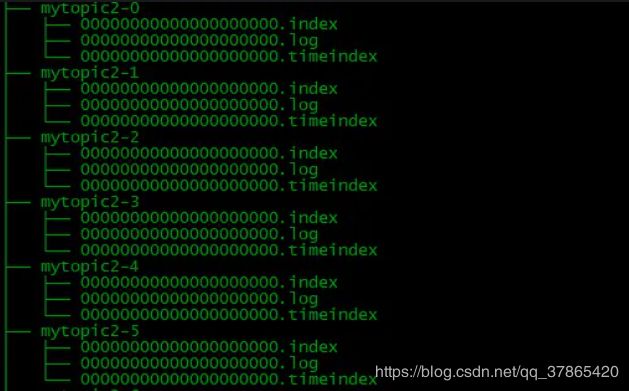
可以看到,在当前kafka broker的文件存储中,一个topic下有多个不同的Partition文件mytopic2-0,mytopic2-1等6个分区对应副本在此broker中,每个partition文件都为一个目录,而每一个目录又被平均分配成多个大小相等的Segment File(其实就是index,log,timeindex)中,Segment File 包括一个日志数据文件和两个索引文件(偏移量索引文件和消息时间戳索引文件)。
Segment文件命名的规则如下:
Partition全局的第一个Segment从0开始,后续每个Segment文件名为上一个Segment文件最后一条消息的offset值。数值最大为64位long型,19位数字字符长度,没有数字用0填充。
- log文件相关
可以用kafka-run-class.sh脚本(底下有说)查看log文件
-
index文件存储
index 文件是二进制存储的,每条索引都记录了消息的相对offset和在文件中的物理位置。这里的相对offset和log文件里的offset不同,相对offset是每个segment都从1开始的,而绝对offset在整个partition中都是唯一的。查看index文件也看底下kafka-run-class.sh脚本使用里有说,2.0版本后支持查看index文件
-
segment分段策略
| 属性名 | 含义 | 默认值 |
|---|---|---|
| log.roll.{hours,ms} | 日志滚动的周期时间,到达指定周期时间时,强制生成一个新的segment | 168(7 day) |
| log.segment.bytes | 每个segment的最大容量。到达指定容量时,将强制生成一个新的segment | 1G(-1 为不限制) |
| log.retention.check.interval.ms | 日志片段文件检查的周期时间 | 60000 |
- 日志刷新策略
Kafka的日志实际上是开始是在缓存中的(linux页缓存),然后根据一定策略定期一批一批写入到日志文件中去,以提高吞吐量.
| 属性名 | 含义 | 默认值 |
|---|---|---|
| log.flush.interval.messages | 消息达到多少条时将数据写入到日志文件 | 10000 |
| log.flush.interval.ms | 当达到该时间时,强制执行一次flush | null |
| log.flush.shceduler.interval.ms | 周期性检查,是否需要将信息flush |
kafka-topic.sh --help
bin/kafka-topics.sh --help
查看帮助信息,所有参数列举
kafka-topic.sh --create
kafka-topic.sh --create
创建Topic有两种方式
第一种:不指定topic
如果设置了auto.create.topic.enable=true,那么当生产者向一个未创建的主题发送消息时,会自动创建一个拥有${num.partitions}个分区和${default.replication.factor}个副本的主题
第二种:脚本命令创建,指定zookeeper的namespace,主题名称,副本数,分区数
bin/kafka-topic.sh --create \
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 --topic name --replication-factor 2 \
--partitions 3
bin/kafka-topics.sh --create --topic test0 \
--zookeeper 192.168.187.146:2181 \
--config max.message.bytes=12800000 --config flush.messages=1 \
--partitions 5 --replication-factor 1
--create: 指定创建topic动作
--topic:指定新建topic的名称
–zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样,这里并不要求传递所有的连接地址,为了容错,建议多个Zookeeper节点的集群至少传递两个Zookeeper的连接配置
–config:指定当前topic上有效的参数值,参数列表参考文档为:
http://kafka.apachecn.org/documentation.html#topicconfigs
--partitions:指定当前创建的kafka分区数量,默认为1个。分区时Kafka并行处理的基本单位,分区越多一定程度上会提升消息处理的吞吐量,然而Kafka消息是以追加的方式存储在文件中的,分区越多,打开的文件句柄也就更多,会带来一定开销
--replication-factor:指定每个分区的复制因子个数,默认1个。副本数<=节点数
注意:创建过后会在${log.dir}目录下生成相应的分区文件目录,形式为主题名称+分区号。如下

注意:同时登陆zk客户端查看所创建主题的元数据信息如下:
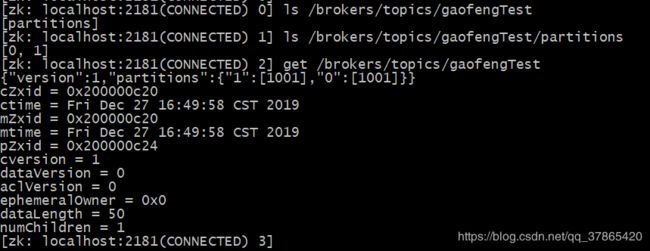
上面gaofengTest主题为2分区,两个分区都是单副本,都在broker_id为1001的节点上
kafka-topic.sh --list
bin/kafka-topics.sh --list \
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181
list命令罗列所有主题名称
kafka-topic.sh --describe
kafka-topic.sh --describe
bin/kafka-topics.sh --zookeeper host-10-1-236-82:2181,\
host-10-1-236-83:2181,host-10-1-236-84:2181 --describe \
--topic gaofengTest
如果查看全部topic则不指定topic
查看topic为zhaoyim01的主题

第一行:主题名称、分区总数、副本总数、创建主题通过config参数所设置的配置。
第二行:按照主题分区编号排序,展示每个分区的leader副本节点,副本列表AR以及ISR列表信息
注意:AR=ISR+OSR
AR:分区中所有的副本统称为AR(assigned replicas)
ISR:所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成 ISR (In Sync Replicas),因此 ISR 是 AR 中的一个子集
OSR:滞后的replicas,follower副本同步时间大于同步所能容忍的最大时间即滞后,则follower副本被leader副本从ISR中剔除,到OSR中了
follower 进入 ISR 列表条件
能够进入 ISR 列表中的条件是可以进行参数配置的:
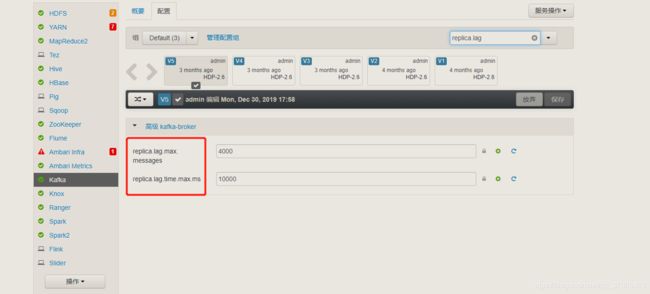
replica.lag.time.max.ms 默认值:10000,单位为:毫秒
该配置表示如果一个 follower 在有一个时间窗口内(默认值为 10 秒)没有发送任意 fetch 请求,leader 就会把这个 follower 从 ISR(in-sync replicas)移除,并存入 OSR 集合。
Kafka 0.9.0.0版本后移除了replica.lag.max.messages参数,只保留了replica.lag.time.max.ms作为ISR中副本管理的参数了,但是HDP(如下图)中看到并没有移除,比较奇怪,未进行深入研究
查看正在同步的主题(describe与under-replicated-partitions命令组合使用)
运维的同学需要注意如下这个操作
bin/kafka-topics.sh --describe \
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--under-replicated-partitions
#查看处于(under replicated)状态的主题
同样的上面的命令可以指定 查看没有Leader的分区(describe与unavailable-partitions组合使用) 查看主题覆盖的配置(describe 与topics-with-overrides组合使用) 输出信息如下: 可以修改主题级别的配置、增加主题分区、修改副本分配方案、修改主题Offset等 修改主题级别配置(alter与config组合使用) 不过还是推荐使用kafka-configs.sh –delete-config删除配置项如下 增加分区 命令执行成功后,查看${log.dir}目录下所分配的分区目录文件均已完成创建 生产者终端模拟如下 生产者模拟可添加如下参数 上述命令也可以指定–partitions参数来指定一个或者多个分区,用逗号分隔,若不指定分区则默认查看所有分区 创建主题 输入上述命令后生产者启动成功,发布消息报WARN日志,提示 查看消息 2.0 中可以使用 kafka-dump-log.sh 查 看.index 文件 重分配脚本 分成三步 –execute 执行分区重分配计划 –verify 验证分区充重配计划 其实实际上就是执行一个json file,从而改变topic --describe出来的分区以及replica内容 我通常都是直接不generate自动生成json文件,而是自己手写这个json file 创建increase-replication-factor.json文件后执行 指定replicas的value值 测试结果输出如下 测试输出结果个字段说明如下 测试结果如下 测试结果共展示了6列信息,依次为运行时间、结束时间、消费的消息总量(单位为MB)、按消费总量统计的吞吐量(单位为MB/s)、消费的消息总条数、按消息总数统计的吞吐量--topics查询
处于(under replicated)状态的主题可能正在进行同步操作,也有可能同步发生异常即ISRbin/kafka-topics.sh --describe \
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--unavailable-partitions
#查看处于unavailable-partitions状态的分区
bin/kafka-topics.sh --describe \
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--topics-with-overrides
--topic gaofengTest
#查看主题所覆盖的配置
Topic:config-test PartitionCount:3 ReplicationFactor:2 Configs:max.message.bytes=404800
kafka-topic.sh --alter
修改gaofengTest主题的max.message.bytes配置使其值为204800
注意:该操作会有警告,提示你该命令已过期,这是因为alter与config组合使用的方式在未来的版本中将不再支持,我在0.10.1.1版本中测试就会返回警告信息。虽然这种操作方式已经过期,但是未被移除bin/kafka-topics.sh --alter
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--topic gaofengTest \
--config max.message.bytes=204800
#增加max.message.bytes=204800配置
bin/kafka-topics.sh --alter
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--topic gaofengTest \
--config segment.bytes=209715200
#增加segment.bytes=209715200配置
bin/kafka-topics.sh --alter
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--topic gaofengTest \
--delete-config segment.bytes
#删除segment.bytes=209715200配置
kafka并不支持减少分区的操作,我们只能为一个主题增加分区,如下partitions由3个增加到5个,直接配置–partitions 5即可bin/kafka-topics.sh --alter
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 \
--topic gaofengTest \
--partitions 5
#为一个主题增加分区,partitions由3个增加到5个
并且同时登陆ZK客户端,查看分区元数据信息显示,主题gaofengTest的分区数已经增加到5个,同时个分区副本进行了重新分配
Kafka-console-producer.sh
bin/kafka-console-producer.sh --broker-list \
host-10-1-236-82:6667,host-10-1-236-83:6667,host-10-1-236-84:6667 \
--topic gaofengTest
![]()
--property parse.key=true #指定每条消息包含有key
例如生产者输入gaofeng 123
消费者获取数据为123
--property key.separator='|' #修改key后面的分隔符
例如生产者输入gaofeng|123
消费者获取数据为123
查看某个主题各分区对应偏移量bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list \
host-10-1-236-82:6667,host-10-1-236-83:6667,host-10-1-236-84:6667 \
--topic gaofengTest --time -1
--time -1
time参数表示查看在指定时间之前的数据,支持-1(latest),-2(earliest)两个时间选项,默认取值为-1 ,-1查询偏移量最大值,-2查询偏移量最小值
先前说过若不指定topic可以创建主题,就可以用这个脚本创建bin/kafka-console-producer.sh --broker-list \
host-10-1-236-82:6667,host-10-1-236-83:6667,host-10-1-236-84:6667 \
--topic nullTopic
WARN Error while fetching metadata with correlation id 0 : {nullTopic=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
警告信息产生的同时就会创建一个新主题nullTopic,该主题有${num.partitions}个分区和${default.replication.factor}个副本。list看出有一个新的主题产生了
这时候继续发布消息,消费者就可以订阅到消息啦


kafka-run-class.sh
Kafka生产的消息以二进制的形式存在文件中,为了方便查看消息内容,Kafka提供了一个查看日志文件的工具类kafka.tools.DumpLogSegments.通过kafka-run-class.sh脚本,可以直接在终端运行该工具类。例如,查看主题gaofengTest相应分区下的日志文件如下图,
执行命令如下:bin/kafka-run-class.sh kafka.tools.DumpLogSegments \
--files /data/kafka-logs/gaofengTest-2/00000000000000000000.log \
--print-data-log

关键字
解释
offset
消息在partition中的绝对offset。能表示这是partition的第多少条消息
message
message大小
CRC32
用crc32校验message
magic
表示本次发布kafka服务程序协议版本号
attributes
表示为独立版本、或标识压缩类型、或编码类型
key length
表示key的长度,当key为-1时,K byte key字段不填
key
可选
value bytes payload
实际消息数据
bin/kafka-dump-log.sh --files ./00000000000000000000.index
kafka-reassign-partitions.sh
此脚本用于
–generate 生成分区重分配计划
步骤可以参考
https://blog.csdn.net/hjtlovelife/article/details/81263168
文件格式如下
replicas扩容{"version":1,
"partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":1,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":2,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":4,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":5,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":6,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":7,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":8,"replicas":[1001,1002]},
{"topic":"__consumer_offsets","partition":9,"replicas":[1001,1002]}
]}
bin/kafka-reassign-partitions.sh --zookeeper host-10-1-236-82:2181,\
host-10-1-236-83:2181,host-10-1-236-84:2181 \
--reassignment-json-file increase-replication-factor.json --execute
监控消费者-订阅消息
bin/kafka-console-consumer.sh
--zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,\
host-10-1-236-84:2181 --topic test006 --from-beginning
监控生产者-模拟发布消息
bin/kafka-console-producer.sh --broker-list host-10-1-236-82:6667,\
host-10-1-236-83:6667,host-10-1-236-84:6667 --topic gaofengTest
生产者性能测试
bin/kafka-producer-perf-test.sh --num-records 1000000 \
--record-size 1000 --topic producer-perf-test throughput 1000000 \
--producer-props bootstrap.servers=server1:9092,server2:9092 acks=all
1000000 records sent,237812.128419 records/sec (226.80MB/sec),
105.50ms avg latency,340.00ms max latency,
101 ms 50th,223 ms 95th,238 ms 99th,240 ms 99.th
字段名
描述
records sent
测试时发送的消息总数
records/sec
以每秒发送的消息数来统计的吞吐量
MB/sec
以每秒发送的消息大小(单位为MB)来统计的吞吐量
avg latency
消息处理的平均耗时,单位为ms
max latency
消息处理的最大耗时,单位为ms
50th/95th/99.9th
分别表示50%,95%,99%的消息处理耗时
消费者性能测试
kafka-consumer-perf-test.sh --broker-list server1:9092,server2:9092,server3:9092 --threads 5 --message 1000000 --message-size 1000 --num-fetch-threads 2 --group consumer-perf-test --new-consumer
start,time, end.time,data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2020-5-13 11:22:33:412, 2020-5-13 11:22:34:002, 953.9422, 166.9251, 1000304, 175023.1243
查看所有消费组名称
kafka-consumer-groups.sh --bootstrap-server server1:9092,server2:9092 --list --new-consumer
解读:
list参数返回与启动方式对应的所有消费组
即,若是以参数zookeeper方式启动的,则返回的是老版本的消费者对应的消费组信息,否则返回新版本的消费者(–bootstrap-server方式启动)对应的消费组信息
执行结果如下
![]()
查看某个消费组消费情况
./bin/kafka-consumer-groups.sh --zookeeper host-10-1-236-82:2181,host-10-1-236-83:2181,host-10-1-236-84:2181 --describe --group test-consumer-group
执行结果如下

解读:注意参数是–bootstrap-server还是–zookeeper,不同的参数查询新老消费组,前者查询新消费组,后者查询旧消费组Kafka脑图
