pandas库简单入门
author:明天依旧可好
email: [email protected]
myName:柯尊柏
文章目录
- 1 文件
- 1.1 读取文件
- 1.2 写CSV文件
- 2 DataFrame
- 2.1 遍历
- 2.2 合并
- 3 行列
- 3.1 查找
- 3.2 删除
- 3.3. 依旧某列对dataFrame进行排序
- 4 索引
- 4.1 更新
- 4.2 设置
- 4.3 重置
- 5 重复项
- 5.1 查看是否存在重复项
- 5.2 删除
- 6 元素
- 6.1 查找
- 6.2 修改
- 7.排序
1 文件
1.1 读取文件
import pandas as pd
import os
file_path = os.path.join("test.csv")
data = pd.read_csv(open(file_path,'r',encoding='utf-8'),sep='|')
#定义一个列表来获取name列中的内容
name_list = []
for column, row in data.iterrows():
name_list.append(row['name'])
print(row['name'])
1.2 写CSV文件
#任意的多组列表
a = [1,2,3]
b = [4,5,6]
#字典中的key值即为csv中的列名
data_dict = {'a_name':a,'b_name':b}
#设置DataFrame中列的排列顺序
dataFrame = pd.DataFrame(data_dict, columns=['a_name', 'b_name'])
#将DataFrame存储到csv文件中,index表示是否显示行名,default=True
dataFrame.to_csv("test.csv", index=False, sep='|')
#如果希望在不覆盖原文件内容的情况下将信息写入文件,可以加上mode="a"
dataFrame.to_csv("test.csv", mode="a", index=False,sep='|')
2 DataFrame
2.1 遍历
遍历DataFrame数据。
for index, row in df.iterrows():
print(row["column"])
2.2 合并
谈到DataFrame数据的合并,一般用到的方法有concat、join、merge。
这里就介绍concat方法,以下是函数原型。
pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明 :
objs:series,dataFrame或者是panel构成的序列list。
axis:需要合并链接的轴,0是行,1是列。
join: 连接的方式 inner,或者outer。
其他一些参数不常用,用的时候再补上说明。
2.2.1 相同字段的表首尾相接
# 现将表构成list,然后在作为concat的输入
frames = [df1, df2, df3]
result = pd.concat(frames)

2.2.2 横向表拼接(行对齐)
2.2.2.1 axis
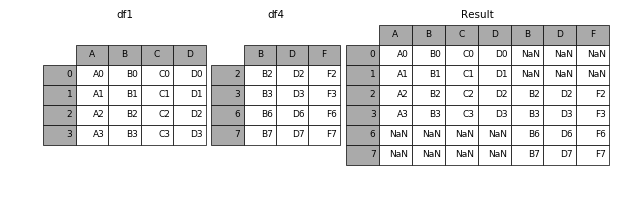
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并。
result = pd.concat([df1, df4], axis=1)
2.2.2.2 join
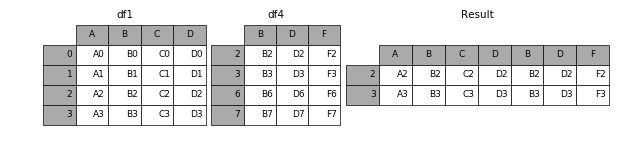
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
result = pd.concat([df1, df4], axis=1, join='inner')
2.2.2.3 join_axes
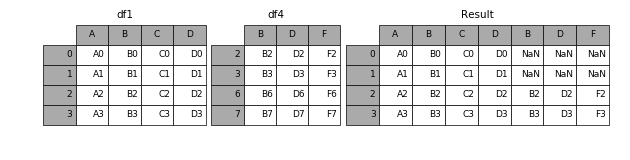
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
3 行列
3.1 查找
查找DataFrame数据类型中的某一(多)行(列)
这里记录三个可以实现该功能的函数:loc、iloc、ix。
讲解如下:
- loc:通过标签选取数据,即通过index和columns的值进行选取。loc方法有两个参数,按顺序控制行列选取。
- iloc:通过行号选取数据,即通过数据所在的自然行列数为选取数据。iloc方法也有两个参数,按顺序控制行列选取。
- ix:混合索引,同时通过标签和行号选取数据。ix方法也有两个参数,按顺序控制行列选取。
代码示例如下:
#DataFrame数据
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
3.1.1 loc
通过标签选取数据,即通过index和columns的值进行选取。loc方法有两个参数,按顺序控制行列选取。
#1.定位单行
df.loc['e']
'''
a 3
b 4
c 5
Name: e, dtype: int32
===================================
'''
#2.定位单列
df.loc[:,'a']
'''
d 0
e 3
f 6
g 9
Name: a, dtype: int32
===================================
'''
#3.定位多行
df.loc['e':]
'''
a b c
e 3 4 5
f 6 7 8
g 9 10 11
===================================
'''
#4.定位多行多列
df.loc['e':,:'b']
'''
a b
e 3 4
f 6 7
g 9 10
===================================
'''
3.1.2 iloc
通过行号选取数据,即通过数据所在的自然行列数为选取数据。iloc方法也有两个参数,按顺序控制行列选取。
#1.定位单行
df.iloc[1]
'''
a 3
b 4
c 5
Name: e, dtype: int32
===================================
'''
#2.定位单列
df.iloc[:,1]
'''
d 1
e 4
f 7
g 10
Name: b, dtype: int32
===================================
'''
#3.定位多行
df.iloc[1:3]
'''
a b c
e 3 4 5
f 6 7 8
===================================
'''
#4.定义多行多列
df.iloc[1:3,1:2]
'''
b
e 4
f 7
===================================
'''
3.1.3 ix
混合索引,同时通过标签和行号选取数据。ix方法也有两个参数,按顺序控制行列选取。
#1.同时用标签和行号
df.ix[1:,'b':]
'''
b c
e 4 5
f 7 8
g 10 11
===================================
'''
#2.用标签,略
#3.用行号,略
3.2 删除
删除DataFrame中某一行
df.drop([16,17])
3.3. 依旧某列对dataFrame进行排序
函数原型
sort_values(by, ascending)
参数说明
by:列名,依旧该列进行排序
ascending:确定排序方式,默认为True(降序)
实例
#dataFrame:
'''
a_name b_name
0 11 4
1 2 52
2 3 6
'''
print(dataFrame.sort_values(by='a_name', ascending=True))
'''
a_name b_name
1 2 52
2 3 6
0 11 4
'''
print(dataFrame.sort_values(by='a_name', ascending=False))
'''
a_name b_name
0 11 4
2 3 6
1 2 52
'''
4 索引
-
reindex()
更新index或者columns,
默认:更新index,返回一个新的DataFrame -
set_index()
将DataFrame中的列columns设置成索引index
打造层次化索引的方法 -
reset_index()
将使用set_index()打造的层次化逆向操作
既是取消层次化索引,将索引变回列,并补上最常规的数字索引
详细讲解:
4.1 更新
reindex():更新index或者columns。
默认:更新index,返回一个新的DataFrame。
# 返回一个新的DataFrame,更新index,原来的index会被替代消失
# 如果dataframe中某个索引值不存在,会自动补上NaN
df2 = df1.reindex(['a','b','c','d','e'])
# fill_valuse为原先不存在的索引补上默认值,不再是NaN
df2 = df1.reindex(['a','b','c','d','e'], fill_value=0)
# inplace=Ture,在DataFrame上修改数据,而不是返回一个新的DataFrame
df1.reindex(['a','b','c','d','e'], inplace=Ture)
# reindex不仅可以修改 索引(行),也可以修改列
states = ["columns_a","columns_b","columns_c"]
df2 = df1.reindex( columns=states )
4.2 设置
set_index():将DataFrame中的列columns设置成索引index。
打造层次化索引的方法。
# 将columns中的其中两列:race和sex的值设置索引,race为一级,sex为二级
# inplace=True 在原数据集上修改的
adult.set_index(['race','sex'], inplace = True)
# 默认情况下,设置成索引的列会从DataFrame中移除
# drop=False将其保留下来
adult.set_index(['race','sex'], drop=False)
4.3 重置
reset_index():将使用set_index()打造的层次化逆向操作。
既是取消层次化索引,将索引变回列,并补上最常规的数字索引。
df.reset_index()
5 重复项
5.1 查看是否存在重复项
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否重复行。
a = df.duplicated()
5.2 删除
而 drop_duplicates方法,它用于返回一个移除了重复行的DataFrame
df = df.drop_duplicates()
6 元素
6.1 查找
通过标签或行号获取某个数值的具体位置(DataFrame数据类型中)
#DataFrame数据
a b c
d 0 1 2
e 3 4 5
f 6 7 8
g 9 10 11
#获取第2行,第3列位置的数据
df.iat[1,2]
Out[205]: 5
#获取f行,a列位置的数据
df.at['f','a']
Out[206]: 6
'''
iat:依据行号定位
at:依旧标签定位
'''
6.2 修改
修改DataFrame中的某一元素
df['列名'][行序号(index)] = "新数据"
7.排序
df.sort_values(by="sales" , ascending=False)
函数原型:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’)
列举常用的参数用法:
- by:函数的操作对象是DataFrame
- axis:进行操作的列名,多个列名用列表表示
- ascending:默认为升序True
df
'''
输出:
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3
'''
df = df.sort_values(by=['col1'])
'''
输出:
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4
'''