Storm(流计算)技术原理
流计算概述
什么是流数据:
数据有静态数据和流数据。
静态数据:
很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘和OLAP(On-Line Analytical Processing)分析工具从静态数据中找到对企业有价值的信息。

流数据:
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达。
- 实例:PM2.5检测、电子商务网站用户点击流
流数据具有如下特征:
- 数据快速持续到达,潜在大小也许是无穷无尽的。
- 数据来源众多,格式复杂。
- 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储。
- 注重数据的整体价值,不过分关注个别数据。
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
批量计算和实时计算:
对静态数据和流数据的处理,对应着两种截然不同的计算模式:批量计算和实时计算。
- 批量计算:充裕时间处理静态数据,如Hadoop。
- 流计算:流数据不适合采用批量计算,因为流数据不适合用传统的关系模型建模。流数据必须采用实时计算,响应时间为秒级。在大数据时代,数据格式复杂、来源众多、数据量巨大,对实时计算提出了很大的挑战。因此,针对流数据的实时计算——流计算,应运而生。

流计算的概念:
流计算:实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息。
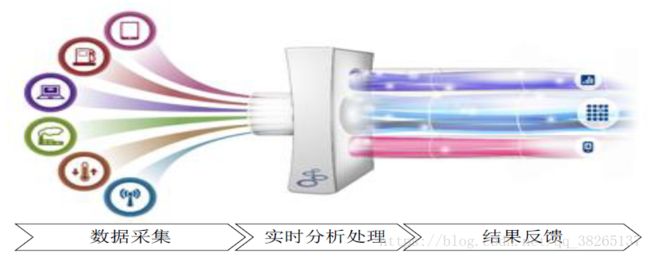
流计算秉承一个基本理念,即数据的价值随着时间的流逝而降低,如用户点击流。因此,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,就需要一个低延迟、可扩展、高可靠的处理引擎.
对于一个流计算系统来说,它应达到如下需求:
- 高性能
- 海量式
- 实时性
- 分布式
- 易用性
- 可靠性
Streaming定义:
Streaming是基于开源Storm,是一个分布式、实时计算框架。
特点:
- 实时响应,低延时。
- 数据不存储,先计算
- 连续查询
- 事件驱动
传统数据库计算:数据先存储,在查询处理。
流计算与Hadoop:
Hadoop设计的初衷是面向大规模数据的批量处理。
MapReduce是专门面向静态数据的批量处理的,内部各种实现机制都为批处理做了高度优化,不适合用于处理持续到达的动态数据。
可能会想到一种“变通”的方案来降低批处理的时间延迟——将基于MapReduce的批量处理转为小批量处理,将输入数据切成小的片段,每隔一个周期就启动一次MapReduce作业。但这种方式也无法有效处理流数据。
- 切分成小片段,可以降低延迟,但是也增加了附加开销,还要处理片段之间依赖关系。
- 需要改造MapReduce以支持流式处理。
结论:鱼和熊掌不可兼得,Hadoop擅长批处理,不适合流计算。
Streaming在FusionInsight中的位置:
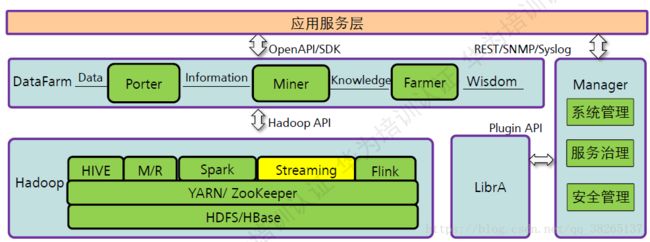
Streaming是一个实时分布式的实时计算框架,在实时业务汇总有广泛的应用。
流计算框架:
当前业界诞生了许多专门的流数据实时计算系统来满足各自需求。
商业级:IBM InfoSphere Streams和IBM StreamBase。
开源流计算框架
- Twitter Storm:免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的流数据。
- Yahoo! S4(Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统。
公司为支持自身业务开发的流计算框架:
- Facebook Puma
- Dstream(百度)
- 银河流数据处理平台(淘宝)
流计算的应用:
流计算是针对流数据的实时计算,可以应用在多种场景中。如百度、淘宝等大型网站中,每天都会产生大量流数据,包括用户的搜索内容、用户的浏览记录等数据。采用流计算进行实时数据分析,可以了解每个时刻的流量变化情况,甚至可以分析用户的实时浏览轨迹,从而进行实时个性化内容推荐。但是,并不是每个应用场景都需要用到流计算的。流计算适合于需要处理持续到达的流数据、对数据处理有较高实时性要求的场景。
主要应用于以下几种场景:
- 实时分析:如实时日志处理、交通流量分析等。
- 实时统计:如网站的实时访问统计、排序等。
- 实时推荐:如实时的广告定位、时间营销等。
流计算处理流程
概述:
传统的数据处理流程,需要先采集数据并存储在关系数据库等数据管理系统中,之后由用户通过查询操作和数据管理系统进行交互。
传统的数据处理流程隐含了两个前提:
- 存储的数据是旧的。存储的静态数据是过去某一时刻的快照,这些数据在查询时可能已不具备时效性了。
- 需要用户主动发出查询来获取结果。
流计算的处理流程一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务。
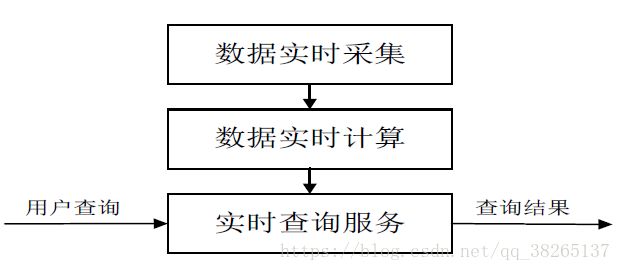
图:流计算处理流程示意图
数据实时采集:
数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠。
以日志数据为例,由于分布式集群的广泛应用,数据分散存储在不同的机器上,因此需要实时汇总来自不同机器上的日志数据。
目前有许多互联网公司发布的开源分布式日志采集系统均可满足每秒数百MB的数据采集和传输需求,如:
- Facebook的Scribe
- LinkedIn的Kafka
- 淘宝的Time Tunnel
- 基于Hadoop的Chukwa和Flume
数据采集系统的基本架构一般有以下三个部分:

- Agent:主动采集数据,并把数据推送到Collector部分。
- Collector:接收多个Agent的数据,并实现有序、可靠、高性能的转发。
- Store:存储Collector转发过来的数据(对于流计算不存储数据)。
数据实时计算:
数据实时计算阶段对采集的数据进行实时的分析和计算,并反馈实时结果。
经流处理系统处理后的数据,可视情况进行存储,以便之后再进行分析计算。在时效性要求较高的场景中,处理之后的数据也可以直接丢弃。
实时查询服务:
实时查询服务:经由流计算框架得出的结果可供用户进行实时查询、展示或储存。
传统的数据处理流程,用户需要主动发出查询才能获得想要的结果。而在流处理流程中,实时查询服务可以不断更新结果,并将用户所需的结果实时推送给用户。
虽然通过对传统的数据处理系统进行定时查询,也可以实现不断地更新结果和结果推送,但通过这样的方式获取的结果,仍然是根据过去某一时刻的数据得到的结果,与实时结果有着本质的区别。
可见,流处理系统与传统的数据处理系统有如下不同:
- 流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据。
- 用户通过流处理系统获取的是实时结果,而通过传统的数据处理系统,获取的是过去某一时刻的结果。
- 流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户。
开源流计算框架Storm
Storm简介:
Twitter Storm是一个免费、开源的分布式实时计算系统,Storm对于实时计算的意义类似于Hadoop对于批处理的意义,Storm可以简单、高效、可靠地处理流数据,并支持多种编程语言。
Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统。
Twitter是全球访问量最大的社交网站之一,Twitter开发Storm流处理框架也是为了应对其不断增长的流数据实时处理需求。
Storm的特点:
Storm可用于许多领域中,如实时分析、在线机器学习、持续计算、远程RPC、数据提取加载转换等。
Storm具有以下主要特点:
- 整合性
- 简易的API
- 可扩展性
- 可靠的消息处理
- 支持各种编程语言
- 快速部署
- 免费、开源
系统架构:

基本概念:
Storm主要术语包括Streams、Spouts、Bolts、Topology和Stream Groupings.
-
Topology:Streaming中运行的一个实时应用程序。
-
Nimbus:负责资源分配和任务调度。
-
Supervisor:负责接收Nimbus分配的任务,启动和停止属于自己管理的worker进程。
-
Worker:Topology运行时的物理进程。每个Worker是一个JVM进程。
-
Spout:Storm认为每个Stream都有一个源头,并把这个源头抽象为Spout。
在一个Topology中产生源数据流的组件。
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。
-
Bolt:在一个Topology中接收数据后然后执行处理的组件。
-
Task:Worker中每一个Spout/Bolt的线程称为一个Task。
-
Tuple:Streaming的核心数据结构,是消息传递的基本单元,不可变Key-Value对,这些Tuple会以一种分布式的方式进程创建和处理。
-
Stream:Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理。即无界的Tuple序列。
-
Zookeeper:为Streaming服务中各自进程提供分布式的协作服务、主备Nimbus、Supervisor、Worker将自己的信息注册到Zookeeper中,Nimbus据此感知各个角色的监控状态。
Topology介绍:

Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提
交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理。
Topology里面的每个处理组件(Spout或Bolt)都包含处理逻辑, 而组件之间的连接则表示数据流动的方向。
Topology里面的每一个组件都是并行运行的:
-
在Topology里面可以指定每个组件的并行度,Storm会在集群里面分配那么多的线程来同时计算。
-
在Topology的具体实现上,Storm中的Topology定义仅仅是一些Thrift结构体(二进制高性能的通信中间件),支持各种编程语言进行定义。
一个Topology是由一组Spout组件(数据源)和Bolt组件(逻辑处理)通过Stream Groupings进行连接的有向无环图(DAG)。
业务处理逻辑被封装进Streaming中的Topology中。
Worker介绍:

Worker:一个Worker是一个JVM进程,所有的Topology都是在一个或者多个Worker中运行的。Worker启动后是长期运行的,除非人工停止。Worker进程的个数取决于Topology的设置,且无设置上限,具体可获得并调度启动的Worker个数则取决于Supervisor配置的slot个数。
Executor:在一个单独的Worker进程中会运行一个或多个Executor线程。每个Executor只能运Spout或者Bolt中的一个或多个Task实例。
Task:是最终完成数据处理的实体单元。
Task介绍:
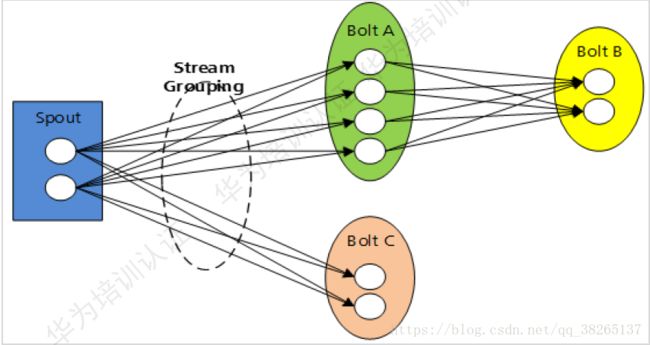
Topology里面的每一个Component(组件)(Spout/Blot)节点都是并行运行的。在Topology里面,可以指定每个节点的并发度,Streaming则会在集群里分配响应的Task来同时计算,以增强系统的处理能力。
消息分发策略(Stream Groupings):
Groupings:Storm中的Stream Groupings用于告知Topology如何在两个组件间(如Spout和Bolt之间,或者不同的Bolt之间)进行Tuple的传送。每一个Spout和Bolt都可以有多个分布式任务,一个任务在什么时候、以什么方式发送Tuple就是由Stream Groupings来决定的。
目前,Storm中的Stream Groupings有如下几种方式:
- ShuffleGrouping:随机分组,随机分发Stream中的Tuple,保证每个Bolt的Task接收Tuple数量大致一致。
- FieldsGrouping:按照字段分组,保证相同字段的Tuple分配到同一个Task中。
- AllGrouping:广播发送,每一个Task都会收到所有的Tuple。
- GlobalGrouping:全局分组,所有的Tuple都发送到同一个Task中。
- NonGrouping:不分组,和ShuffleGrouping类似,当前Task的执行会和它的被订阅者在同一个线程中执行。
- DirectGrouping:直接分组,直接指定由某个Task来执行Tuple的处理。

Storm框架设计:
Storm集群采用“Master—Worker”的节点方式:
-
Master节点运行名为“Nimbus”的后台程序(类似Hadoop中的“JobTracker”),负责在集群范围内分发代码、为Worker分配任务和监测故障。
-
Worker节点运行名为“Supervisor”的后台程序,负责监听分配给它所在机器的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程,一个Worker节点上同时运行若干个Worker进程。
-
Storm使用Zookeeper来作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作。借助于Zookeeper,若Nimbus进程或Supervisor进程意外终止,重启时也能读取、恢复之前的状态并继续工作,使得Storm极其稳定。

Nimbus并不直接和Supervisor交换,而是通过Zookeeper进行消息的传递。
Storm和Hadoop架构组件功能对应关系:
Storm运行任务的方式与Hadoop类似:Hadoop运行的是MapReduce作业,而Storm运行的是“Topology”。
但两者的任务大不相同,主要的不同是:MapReduce作业最终会完成计算并结束运行,而Topology将持续处理消息(直到人为终止)。

Storm工作流程:
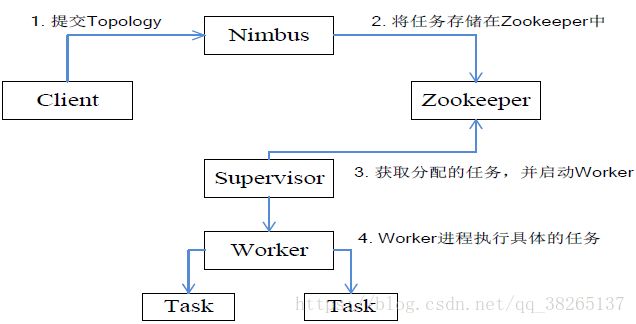
Storm工作流程为:
- 提交Topology
- 将任务存储在Zookeeper中
- 获取分配的任务,并启动Worker
- Worker进程执行具体的任务
所有Topology任务的提交必须在Storm客户端节点上进行,提交后,由Nimbus节点分配给其他Supervisor节点进行处理。
Nimbus节点首先将提交的Topology进行分片,分成一个个Task,分配给相应的Supervisor,并将Task和Supervisor相关
的信息提交到Zookeeper集群上。
Supervisor会去Zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理。
Streaming提供的接口:
REST接口:(Representational State Transfer)表述性状态转移接口。
Thrift接口:由Nimbus提供。Thrift是一个基于静态代码生成的跨语言的RPC协议栈实现,它可以生成包括C++,Java,Python, Ruby , PHP等主流语言的代码实现,这些代码实现了RPC的协议层和传输层功能,从而让用户可以集中精力与服务的调用和实现。
Streaming的关键特性介绍
Nimbus HA:

-
使用Zookeeper分布式锁:
Nimbus HA的实现是使用Zookeeper分布式锁,通过主备间争抢模式完成的Leader选举和主备切换。
-
主备间元数据同步:
主备Nimbus之间会周期性的同步元数据,保证在发生主备切换后拓扑数据不丢失,业务不受损。
容灾能力:
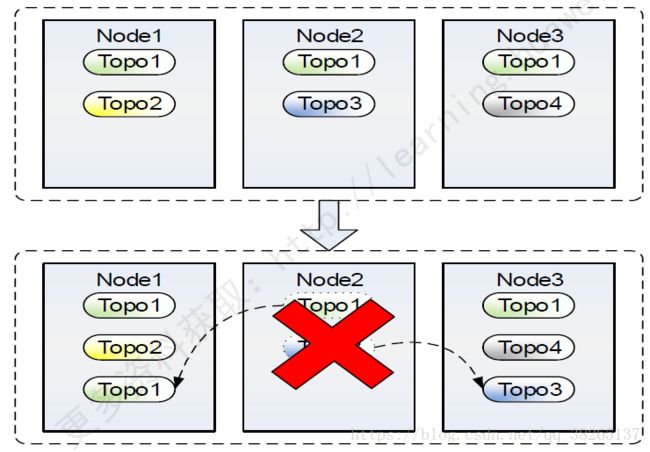
容灾能力:节点失效,自动迁移到正常节点,业务不中断。
整个过程无需人工干预!
消息可靠性:

在Streaming里面一个Tuple被完全处理的意思是:这个Tuple所派生的所有tuple都被成功处理。如果这个消息在Timeout所指定的时间内没有成功处理,这个tuple就被认为处理失败了。
可靠性级别设置:
如果并不要求每个消息必须被处理(允许在处理过程中丢失一些信息),那么可以关闭消息的可靠性处理机制,从而可以获得较好的性能。关闭消息的可靠性机制一位着系统中的消息数会减半。
有三种方法可以关闭消息的可靠性处理机制:
- 将参数Config.TOPOLGY_ACKERS设置为0.
- Spout发送一个消息时,使用不指定消息message ID的接口进行发送。
- Blot发送消息时使用Unanchor方式发送,使Tuple树不往下延伸,从而关闭派生消息的可靠性。
ACK机制:
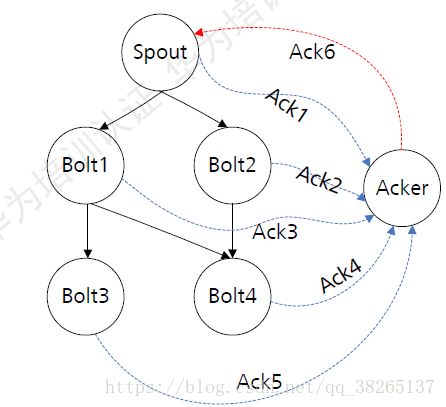
- 一个Spout发送一个Tuple时,会通知Acker一个新的根消息产生了,Acker会创建一个新的Tuple tree,并初始化校验和为0.
- Bolt发送消息时间向Acker发送anchor tuple,刷新tuple tree,并在发送成功后向Acker反馈结果。如果成功则重新刷新校验和,如果失败则Acker会立即通知Spout处理失败。
- 当Tuple tree被完成吹了(校验和为0),Acker会通知Spout处理成功。
- Spout提供ack()和Fail()接口方法用户处理Acker的反馈结果,需要用户实现。一般在fail()方法中实现消息重发逻辑。
Streaming与其他组件:
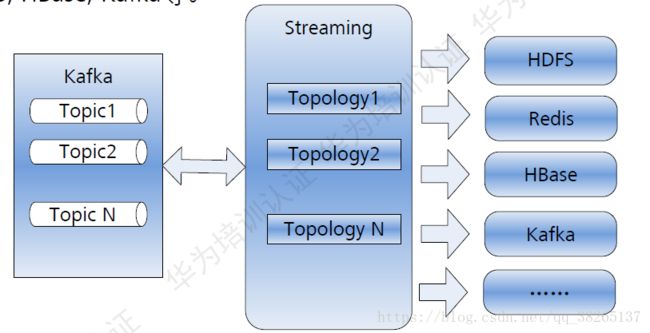
整合HDFS/HBase等外部组件,将实时结构提供给其他组件,进程离线分析。
Spark Streaming
Spark Streaming设计:
Spark Streaming可整合多种输入数据源,如Kafka、Flume、
HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件
系统、数据库,或显示在仪表盘里。

Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据。

**Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。**在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段的DStream,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终转变为对相应的RDD的操作。

Spark Streaming 与 Storm的对比:
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理。
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Samza技术原理
基本概念:
(1)作业:一个作业(Job)是对一组输入流进行处理转化成输出流的程序。
(2)分区:
- Samza的流数据单位既不是Storm中的元组,也不是Spark Streaming中的DStream,而是一条条消息。
- Samza中的每个流都被分割成一个或多个分区,对于流里的每一个分区而言,都是一个有序的消息序列,后续到达的消息会根据一定规则被追加到其中一个分区里。
(3)任务:
- 一个作业会被进一步分割成多个任务(Task)来执行,其中,每个任务负责处理作业中的一个分区。
- 分区之间没有定义顺序,从而允许每一个任务独立执行。
- YARN调度器负责把任务分发给各个机器,最终,一个工作中的多个任务会被分发到多个机器进行分布式并行处理。
(4)数据流图:
- 一个数据流图是由多个作业构成的,其中,图中的每个节点表示包含数据的流,每条边表示数据传输。
- 多个作业串联起来就完成了流式的数据处理流程。
- 由于采用了异步的消息订阅分发机制,不同任务之间可以独立运行。

Samza的系统架构:
Samza系统架构主要包括:
- 流数据层(Kafka)
- 执行层(YARN)
- 处理层(Samza API)
流处理层和执行层都被设计成可插拔的,开发人员可以使用其他框架来替代YARN和Kafka。

处理分析过程:

处理分析过程如下:
- Samza客户端需要执行一个Samza作业时,它会向YARN的ResouceManager提交作业请求。
- ResouceManager通过与NodeManager沟通为该作业分配容器(包含了CPU、内存等资源)来运行Samza ApplicationMaster。
- Samza ApplicationMaster进一步向ResourceManager申请运行任务的容器。
- 获得容器后,Samza ApplicationMaster与容器所在的NodeManager沟通,启动该容器,并在其中运行Samza Task Runner。
- Samza Task Runner负责执行具体的Samza任务,完成流数据处理分析。
Storm、Spark Streaming和Samza的应用场景
从编程的灵活性来讲,Storm是比较理想的选择,它使用Apache Thrift,可以用任何编程语言来编写拓扑结构(Topology)。
当需要在一个集群中把流计算和图计算、机器学习、SQL查询分析等进行结合时,可以选择Spark Streaming,因为,在Spark上可以统一部署Spark SQL,Spark Streaming、MLlib,GraphX等组件,提供便捷的一体化编程模型。
当有大量的状态需要处理时,比如每个分区都有数十亿个元组,则可以选择Samza。当应用场景需要毫秒级响应时,可以选择Storm和Samza,因为Spark Streaming无法实现毫秒级的流计算。
以上内容为听华为大数据培训课程和大学MOOC上厦门大学 林子雨的《大数据技术原理与应用》课程而整理的笔记。
大数据技术原理与应用: https://www.icourse163.org/course/XMU-1002335004