Flume+Sqoop
Flume
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
flume可以采集文件,socket数据包等各种形式源数据。有可以将采集到的数据传输到HDFS、hbase、hive、kafka等众多外部存储系统中
一般的采集需求,通过对flume的简单配置即可实现。
flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以使用于大部分的日常数据采集场景。
运行机制
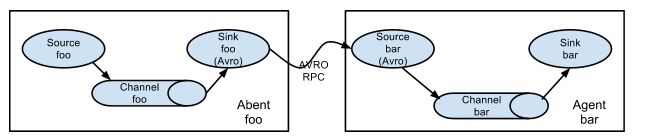
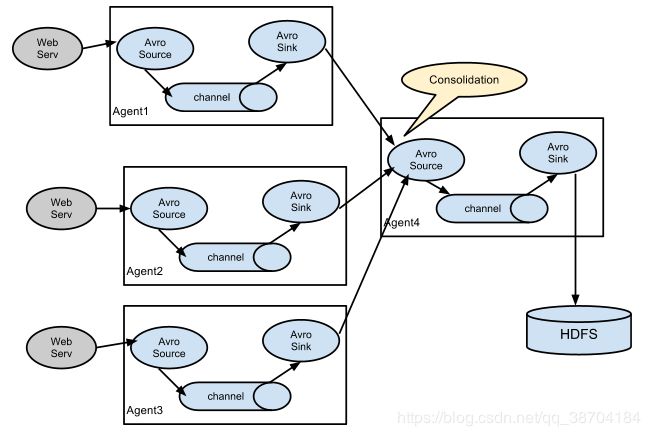
flume分布式系统中核心的角色是agent,flume采集系统就是有一个个agent锁连接起来形成的。
- source:采集员,用于跟数据源对接,以获取数据
- sink:下沉池,采集数据的传送目的,用于下一级agent传递数据或者往最终存储系统传递数据
- channel:agent内部的数据传输通道,童虎从source将数据传递到sink
- source到channel到sink之间传递数据的形式是Event事件,event事件是一个数据单元
- flume官方网站:http://flume.apache.org/FlumeUserGuide.html查看实例(包扣配置方案,如何测试,代码齐全)


2.Sqoop
sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例:mysql,orcal,postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进关系型数据库中。
- 上传
- 解压
- 把数据库连接驱动放到$SQOOP_HOME\lib下面
- 设置mysql数据库运行远程访问:(关闭WiFi精灵,防火墙,杀毒软件)默认不允许外部访问,原因root用户只允许localhost访问,不允许远程ip访问。
- GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
- FLUSH PRIVILEGES(权限刷新)
把mysql里面的数据导入到HDFS中(指定输出路径、指定数据分隔符)
./sqoop import --connect jdbc:mysql//主机ip:3306/数据库名 --username root --password 123456 --table 将要操作的表 --targer-dir '数据导入到HDFS上的目录' --fields-terminated-by '分隔符' [-m 2]
指定Map数量 -m
增加where条件,注意:条件必须用引号引起来
.... --table dept --where 'd_id>3' --target-dir '输出路径'
增加query语句(使用\将语句换行)
... --query 'select * from dept where d_id >2 AND $CONDITIONS' --split-by dept.d_id --target-dir '输出路径'
注意:如果使用--query这个命令的时候,需要注意的是where后面的参数,AND $CONDITIONS这个参数必须加上,而且存在单引号的区别,如果--query后面使用的是双引号,那么需要在$CONDITIONS前面加上\即\$CONDITIONS,如果设置map数量为1个时即-m 1,不要加上--split-by${tablename.column},否则需要加上。
注意:在HDFS我们设置的目录下可以看到,数据库中每一条数据都存放在一个单独的文件夹中,文件默认从0开始排序,而数据库索引是从1开始的
把HDFS中的数据导出到mysql中(不要忘记指定分隔符)
首先数据库创建表(数据库字段要符合HDFS上数据的格式)
导出:
./sqoop export --connect jdbc:mysql://主机ip:3306/数据库名 --username root --password 123456 --export-dir '从HDFS上呢个目录下的文件' --table 将要写入到数据库中呢个表里面 -m 1 --fields-terminated-by '分隔符'