python数据分析七:DataFrame的函数(求和、协方差、相关系数等)
详解点击打开链接
导数:
导数简单点说,就是函数的斜率.比如说y=x这个函数,图像你应该很清楚吧,虽然y是随着x的正加而增大的,但是其变化率也就是斜率是一直不变的.那么你能猜出来y=x的导数是多少么?
y=x的导数y'=1,同理y=2x时,则y'=2,这是最简单的.当函数是2次函数的时候,其斜率会忽大忽小,甚至忽正忽负,这时y'不再是一个固定的数,而是一个根据x值变化的数(说白了也是一个函数)
协方差:
在 概率论和统计学中,协方差用于衡量两个变量的总体误差。而 方差是协方差的一种特殊情况,即当两个变量是相同的情况。
[1]
期望值分别为
E[
X]与
E[
Y]的两个实随机变量
X与
Y之间的
协方差
Cov(X,Y)定义为:
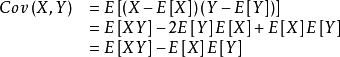
从直观上来看,协方差表示的是两个变量总体误差的期望。
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值时另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值;如果两个变量的变化趋势相反,即其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
相关系数:判断两个变量之间变换趋势的关系例子,比如一个班里同学的身高和体重对应的变化趋势的关系
- 用随机变量X,Y的协方差除以X的标准差和Y的标准差,公式为:ρ=Cov(X,Y)σxσyρ=Cov(X,Y)σxσy
- 相关系数也可以看成是协方差:一种剔除了两个变量量纲,标准化后的协方差。
既然是中特殊的协方差,那么:
1)也可以反映两个变量变化时是同向还是反向,如果同向变化就为正,反向变化就为负。
2)由于它是标准化后的协方差,因此更重要的特性来了:它消除了两个变量变化幅度的影响,而只是单纯反应两个变量每单位变化时的相似程度。
Xi 1.1 1.9 3
Yi 5.0 10.4 14.6
E(X) = (1.1+1.9+3)/3=2
E(Y) = (5.0+10.4+14.6)/3=10
E(XY)=(1.1×5.0+1.9×10.4+3×14.6)/3=23.02
Cov(X,Y)=E(XY)-E(X)E(Y)=23.02-2×10=3.02
此外:还可以计算:
D(X)=E(X²)-E²(X)=(1.1²+1.9²+3²)/3 - 4=4.60-4=0.6 σx=0.77
D(Y)=E(Y²)-E²(Y)=(5²+10.4²+14.6²)/3-100=15.44 σy=3.93
X,Y的相关系数:
r(X,Y)=Cov(X,Y)/(σxσy)=3.02/(0.77×3.93) = 0.9979
表明这组数据X,Y之间相关性很好!这里的σy就是D(Y)方差的平方根
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
'''
函数应用和映射
'''
frame=DataFrame(np.random.randn(4,3),columns=list('bde'),index=['Ut','Oh','Te','Or'])
frame2=np.abs(frame)
print(frame2)
# b d e
# Ut 0.150541 2.285615 0.167419
# Oh 0.251909 1.053112 1.362582
# Te 1.195181 0.096545 0.695548
# Or 0.076306 0.184408 0.227923
#apply方法,lambda方法进行复杂运算,获取行或列,最大值减去最小值
f=lambda x:x.max()-x.min()
print(frame2.apply(f))
# b 1.118875
# d 2.189071
# e 1.195162
print(frame2.apply(f,axis=1))
# Ut 2.135074
# Oh 1.110673
# Te 1.098636
# Or 0.151617
# dtype: float64
#定义函数方法 获取最大值和最小值
def f(x):
return Series([x.min(),x.max()],index=['min','max'])
print(frame.apply(f))
# b d e
# min -0.159609 -1.706797 -0.732225
# max 0.912972 1.986610 2.781436
#设置小位数计算
format=lambda x:'%.2f' %x
print(frame.applymap(format))
# b d e
# Ut -0.27 -0.04 0.03
# Oh 0.64 -0.90 0.89
# Te 0.71 -0.53 1.13
# Or 1.89 -0.58 -0.05
#设置单列计算
print(frame['e'].map(format))
# Ut 1.64
# Oh 0.17
# Te 2.66
# Or 1.91
# Name: e, dtype: object
'''
排序和排名
'''
obj=Series(range(4),index=list('dabc'))
#索引排序
obj_sort=obj.sort_index()
print(obj_sort)
# a 1
# b 2
# c 3
# d 0
# dtype: int64
#可以对轴上的任意索引进行排序
frame=DataFrame(np.arange(8).reshape(2,4),index=['two','one'],columns=list('bcad'))
print(frame)
# b c a d
# two 0 1 2 3
# one 4 5 6 7
#行排序
print(frame.sort_index())
# b c a d
# one 4 5 6 7
# two 0 1 2 3
#列排序
print(frame.sort_index(axis=1))
# a b c d
# two 2 0 1 3
# one 6 4 5 7
#降序
print(frame.sort_index(axis=1,ascending=False))
# d c b a
# two 3 1 0 2
# one 7 5 4 6
#对Series排序有order的方法
obj=Series([1,23,4,5])
print(obj)
#根据一个或多个列进行排序
frame=DataFrame({'b':[100,20,34,5],'a':[30,4,50,6]})
print(frame)
print(frame.sort_values(by=['b']))
print(frame.sort_values(by=['b','a']))
# b a
# 3 5 6
# 1 20 4
# 2 34 50
# 0 100 30
'''
排名,rank 它和numpy.argsort的排序索引差不多,,根据某种关系破坏平级关系,
'''
obj=Series([7,-5,7,4,2,0,4])
print(obj.rank())
# 0 6.5
# 1 1.0
# 2 6.5
# 3 4.5
# 4 3.0
# 5 2.0
# 6 4.5
# dtype: float64
#根据原数据出现的顺序进行排名,谁先出现谁的排名高
print(obj.rank(method='first'))
# 0 6.0
# 1 1.0
# 2 7.0
# 3 4.0
# 4 3.0
# 5 2.0
# 6 5.0
# dtype: float64
#降序排名
print(obj.rank(ascending=False,method='first'))
# 0 1.0
# 1 7.0
# 2 2.0
# 3 3.0
# 4 5.0
# 5 6.0
# 6 4.0
# dtype: float64
'''
DataFrame排序
'''
frame=DataFrame({'b':[4.3,7,-3,2],'a':[0,1,2,1],'c':[2.4,1,3,4]})
print(frame)
# b a c
# 0 4.3 0 2.4
# 1 7.0 1 1.0
# 2 -3.0 2 3.0
# 3 2.0 1 4.0
print(frame.rank(axis=1))
# b a c
# 0 3.0 1.0 2.0
# 1 3.0 1.5 1.5
# 2 1.0 2.0 3.0
# 3 2.0 1.0 3.0
'''
DataFrame或者Series可能有多个索引
'''
obj=Series([1,23,3,4],index=list('aabb'))
print(obj['a'])
# a 1
# a 23
#判断索引是否唯一
print(obj.index.is_unique)#False
data=DataFrame(np.arange(12).reshape(3,4),index=list('aab'))
print(data)
# 0 1 2 3
# a 0 1 2 3
# a 4 5 6 7
# b 8 9 10 11
print(data.ix['a'])
# 0 1 2 3
# a 0 1 2 3
# a 4 5 6 7
'''
汇总和计算统计,平均值,总和等
'''
df=DataFrame([[1.2,np.nan],[7.1,-4.5],[np.nan,np.nan],[0.75,-1.3]],index=list('abcd'),columns=['one','two'])
print(df)
# one two
# a 1.20 NaN
# b 7.10 -4.5
# c NaN NaN
# d 0.75 -1.3
#列求和
print(df.sum())
# one 9.05
# two -5.80
# dtype: float64
#行求和
print(df.sum(axis=1))
# a 1.20
# b 2.60
# c 0.00
# d -0.55
# dtype: float64
#行求平均值
print(df.mean(axis=1))
# a 1.200
# b 1.300
# c NaN
# d -0.275
# dtype: float64
#最大值
df.idxmax()
#最小值
df.idxmin()
#累加型
print(df.cumsum())
# one two
# a 1.20 NaN
# b 8.30 -4.5
# c NaN NaN
# d 9.05 -5.8
#汇总多个信息
print(df.describe())
# one two
# count 3.000000 2.000000
# mean 3.016667 -2.900000
# std 3.543421 2.262742
# min 0.750000 -4.500000
# 25% 0.975000 -3.700000
# 50% 1.200000 -2.900000
# 75% 4.150000 -2.100000
# max 7.100000 -1.300000
'''
Series方法同DataFrame
'''
obj=Series(['a','a','c','b']*4)
print(obj.describe())
# count 16
# unique 3
# top a
# freq 8
# dtype: object
'''
相关系数 corr
协方差 cov
'''
data=DataFrame([[-2.1,-1,4.3],[3,1.1,0.12],[3,1.1,0.12]],index=['one','two','three'],columns=list('abc'))
print(data)
print('相关系数')
#one two three的相关系数
# 相关系数
print(data.corr())
# a b c
# a 1.0 1.0 -1.0
# b 1.0 1.0 -1.0
# c -1.0 -1.0 1.0
print('协方差')
print(data.cov())
# 协方差
# a b c
# a 8.670 3.570 -7.106000
# b 3.570 1.470 -2.926000
# c -7.106 -2.926 5.824133
# from pandas_datareader import data as web
# all_data={}
#
# for ticker in ['AAPL', 'IBM', 'GOOG']:
# all_data[ticker] = web.get_data_yahoo(ticker, '1/1/2000', '1/1/2010')
#
# price = DataFrame({tic:data['Adj Close'] for tic,data in all_data.iteritems()})
# volume = DataFrame({tic:data['Volume'] for tic,data in all_data.iteritems()})
# returns = price.pct_change() #计算百分比
# print(returns.tail())
'''
唯一值,值计数,成员资格
'''
obj=Series(['c','a','d','a','a','b','b','c','c'])
#去重
print(obj.unique())#['c' 'a' 'd' 'b']
#计算出现的频率
print(obj.value_counts())
# a 3
# c 3
# b 2
# d 1
# dtype: int64
#成员资格
mask=obj.isin(['b','c'])
print(mask)
# 0 True
# 1 False
# 2 False
# 3 False
# 4 False
# 5 True
# 6 True
# 7 True
# 8 True
# dtype: bool
#成员位置
print(obj[mask])
# 0 c
# 5 b
# 6 b
# 7 c
# 8 c
'''
生成柱状数据
'''
data=DataFrame({'Q1':[1,3,4,3,4],'Q2':[2,3,1,2,3],'Q3':[1,5,2,4,4]})
print(data)
# Q1 Q2 Q3
# 0 1 2 1
# 1 3 3 5
# 2 4 1 2
# 3 3 2 4
# 4 4 3 4
#查看Q1,Q2,Q3 存在对象的个数
result=data.apply(pd.value_counts).fillna(0)
print(result)
# Q1 Q2 Q3
# 1 1.0 1.0 1.0
# 2 0.0 2.0 1.0
# 3 2.0 2.0 0.0
# 4 2.0 0.0 2.0
# 5 0.0 0.0 1.0