利用正则表达式, xpath, Beautifulsoup来解析网页
1 使用正则表达式的时候需要导入re模块,这个是python自带的模块,不用下载
1.1正则表达式有许多常用的规则
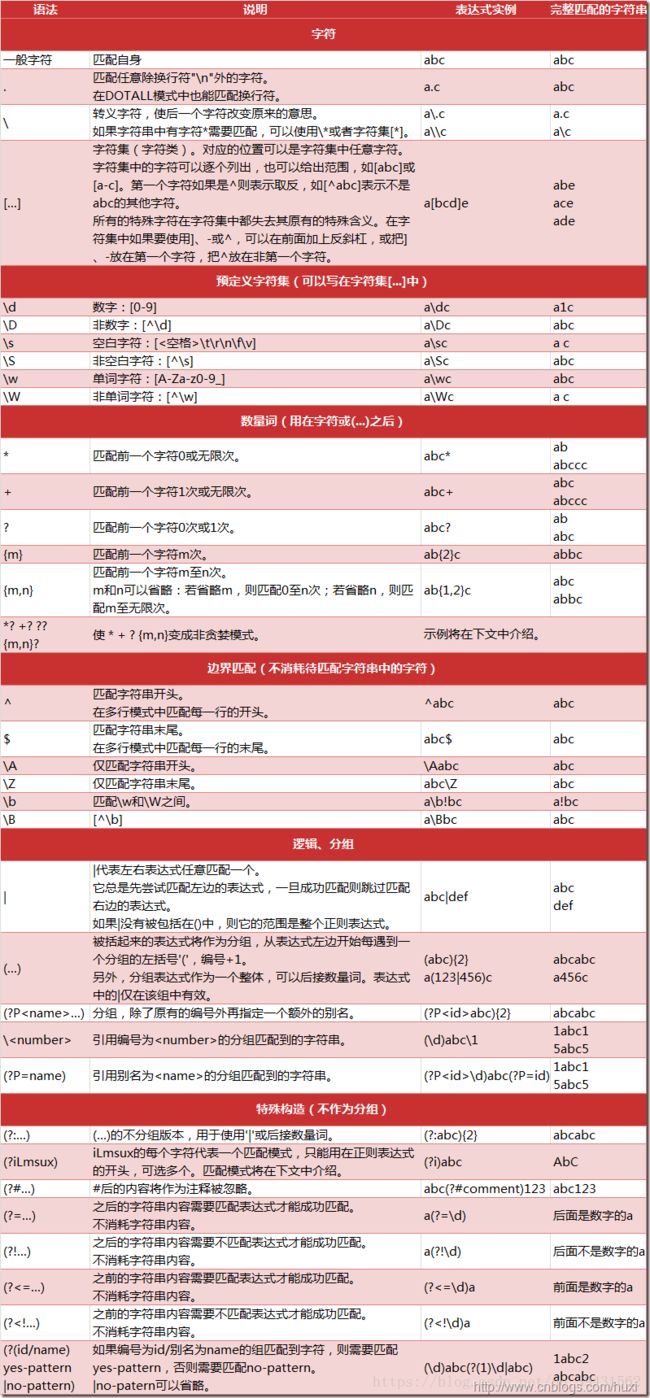
这里要注意贪婪匹配和非贪婪匹配以及反斜杠转义的问题
1.2 匹配网页的时候有时候要考虑到换行和大小写的问题
遇到匹配换行时要使用修饰符re.S,遇到忽略大小写时需要使用re.I
1.3 re.findall()方法,源码
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)返回匹配的所有项,并且存在列表里,它的应用场景就是我想匹配很多信息的时候,对吧
1.4 re.compile()方法 , 源码
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a pattern object."
return _compile(pattern, flags)这个方法将正则字符串编译成正则表达式对象,它的应用场景就是编译了一个正则表达式可以多次调用
1.5 re.sub()方法, 源码
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)就是说只要被pattern匹配到的字符,就会被repl替换,返回替换之后的项,它最常用在当提取的网页有多余的信息时,用它来把这些多余的东西处理掉
1.5 re.match()方法, 源码
def match(pattern, string, flags=0):
"""Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).match(string)它的意思就是说从一个字符串的开头匹配正则表达式,如果匹配返回一个匹配对象,否则返回None
这个的应用场景一般用来检验匹配是否正确的
match object有几个方法 span():返回匹配的范围,例如(0,12), group()返回匹配的字符串
2 BeautifulSoup
这个是需要从bs4这个库中导入的,而且python没有自带bs4,因此需要安装一下,cmd打开命令行,输入
pip install bs4前提是python的环境变量要配置好
2.1 BeautifulSoup有两个常用的解析器,lxml和html.parser,其中html.parser是python内置的标准库,执行速度一般,容错能力强,lxml这个库需要下载 pip install lxml, 它的优势就是速度快,容错能力强,因此建议使用lxml。
2.2 css选择器, 源码,太长了只贴一部分:
select 返回的是列表
def select(self, selector, _candidate_generator=None, limit=None):
"""Perform a CSS selection operation on the current element."""
# Handle grouping selectors if ',' exists, ie: p,a
if ',' in selector:
context = []
for partial_selector in selector.split(','):
partial_selector = partial_selector.strip()
if partial_selector == '':
raise ValueError('Invalid group selection syntax: %s' % selector)
candidates = self.select(partial_selector, limit=limit)
for candidate in candidates:
if candidate not in context:
context.append(candidate)
if limit and len(context) >= limit:
break
return context
tokens = shlex.split(selector)
current_context = [self]这个很简单,学过css的都知道它的选择器语法,在BeautifulSoup中我们使用select()方法来引用css选择器,粘贴一段演示代码,提取猫眼电影的一些信息:
soup = BeautifulSoup(html, "lxml")
data = soup.select(".board-item-content")
print(data)
for i in data:
file = []
file.append(i.p.a.text.strip())
file.append(i.select(".star")[0].text.strip())
file.append(i.select(".releasetime")[0].text.strip())
score = str(i.select(".score .integer")[0].text + i.select(".score .fraction")[0].text)
file.append(score)
info.append(file)
对应的html:
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/2641" title="罗马假日" data-act="boarditem-click" data-val="{movieId:2641}">罗马假日a>p>
<p class="star">
主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特
p>
<p class="releasetime">上映时间:1953-09-02(美国)p> div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.i><i class="fraction">1i>p>
div>
div>
div>通过select()方法筛选的节点都是bs4.element.Tag类型,因此可以进行嵌套的选择
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select("ul"):
print(ul.select('li'))3 方法选择器
3.1 find_all(),返回的是列表
def find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs):
"""Extracts a list of Tag objects that match the given
criteria. You can specify the name of the Tag and any
attributes you want the Tag to have.
The value of a key-value pair in the 'attrs' map can be a
string, a list of strings, a regular expression object, or a
callable that takes a string and returns whether or not the
string matches for some custom definition of 'matches'. The
same is true of the tag name."""
generator = self.descendants
if not recursive:
generator = self.children
return self._find_all(name, attrs, text, limit, generator, **kwargs)
findAll = find_all # BS3
findChildren = find_all # BS2name:可以根据节点名来查询元素:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))attrs:可以根据属性来查询元素,attrs是字典
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print( soup.find_all(attrs={'id':xxxx}))对于一些常用的我们可以不必用attrs来传递
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print( soup.find_all(id=xxxx))text参数可以用来匹配节点的文本,传入的形式可以是字符串也可以是正则表达式对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print( soup.find_all(text=re.compile('xxxxxxx')))3.2 find(),他和find_all差不多,只不过find返回一个,find_all返回多个,源代码:
def find(self, name=None, attrs={}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0] # 取索引为0的就是返回第一个呀
return r
findChild = find3.3 获取文本内容通常是用xxxx.string, xxx.text ,xxx. get_text()
3.5 获取属性:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print( soup.p.attrs))#返回的是字典形式的属性
也可以不这样写,直接写属性名
print( soup.p['class']))
print( soup.p['name']))