SMO算法最通俗易懂的解释
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~
任何关于算法、编程、AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主在线答疑~此外,公众号内还有更多AI、算法、编程和大数据知识分享,以及免费的SSR节点和学习资料。其他平台(知乎/B站)也是同名「图灵的猫」,不要迷路哦~



SVM通常用对偶问题来求解,这样的好处有两个:1、变量只有N个(N为训练集中的样本个数),原始问题中的变量数量与样本点的特征个数相同,当样本特征非常多时,求解难度较大。2、可以方便地引入核函数,求解非线性SVM。求解对偶问题,常用的算法是SMO,彻底地理解这个算法对初学者有一定难度,本文尝试模拟算法作者发明该算法的思考过程,让大家轻轻松松理解SMO算法。文中的“我”拟指发明算法的大神。
001、初生牛犊不怕虎
最近,不少哥们儿向我反映,SVM对偶问题的求解算法太低效,训练集很大时,算法还没有蜗牛爬得快,很多世界著名的学者都在研究新的算法呢。听闻此言,我心头一喜:“兄弟我扬名立万的机会来了!”
我打开书,找出问题,看到是这个样子的:
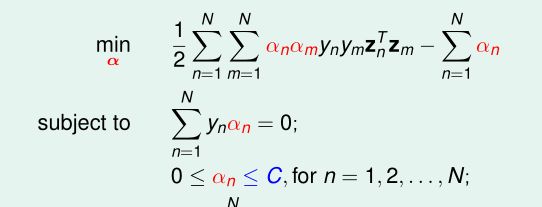
这明显就是一个凸二次规划问题嘛,还不好解?等等,哥们说现有算法比较慢,所以我绝对不能按照常规思路去思考,要另辟蹊径。
蹊径啊蹊径,你在哪里呢?
我冥思苦想好几天,都没有什么好办法,哎!看来扬名立万的事儿要泡汤了。放下书,我决定去湖边(注:是瓦尔登湖不?)散散心,我已经在小黑屋关得太久了。
010、得来全不费工夫
正午时分,一丝风也没有,湖边零零散散的小情侣在呢喃私语,只有苦逼的我单身一个,我坐在湖边的一块大石上,平静的湖面映出我胡子拉碴憔悴的脸,我心里苦笑:“湖想必是可怜我,映出个对影陪我。”“对影???!!!”我心头一道亮光闪过,犹如干裂的土地听到第一声惊雷!我突然有了新的思路!
我疯狂地跑回屋里,身后是一对对受惊的小情侣怨恨的眼神。
我开始整理自己的思绪:
这个问题如果作为单纯的凸二次规划问题来看,很难有什么新的办法,毕竟凸二次规划已经被研究得透透了。但它的特殊之处在于:它是另一个问题的对偶问题,还满足KKT条件,怎么充分利用这个特殊性呢?
我随机找一个α=(α1,α2,...,αN)。假设它就是最优解,就可以用KKT条件来计算出原问题的最优解(w,b),就是这个样子:
进而可以得到分离超平面:

按照SVM的理论,如果这个g(x)是最优的分离超平面,就有:
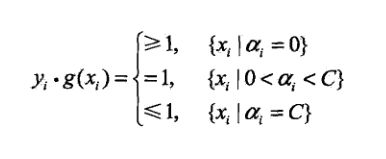
姑且称这个叫g(x)目标条件吧。
根据已有的理论,上面的推导过程是可逆的。也就是说,只要我能找到一个α,它除了满足对偶问题的两个初始限制条件:
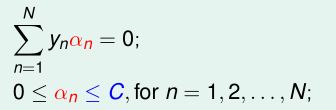
由它求出的分离超平面g(x)还能满足g(x)目标条件,那么这个α就是对偶问题的最优解!!!
至此,我的思路已经确定了:首先,初始化一个α,让它满足对偶问题的两个初始限制条件,然后不断优化它,使得由它确定的分离超平面满足g(x)目标条件,在优化的过程中始终确保它满足初始限制条件,这样就可以找到最优解。
我不禁感到洋洋得意了,哥们我没有按照传统思路,想着怎么去让目标函数达到最小,而是想着怎么让α满足g(x)目标条件,牛X!我真他妈牛X!哈哈!!
011、中流击水停不住
具体怎么优化α呢?经过思考,我发现必须遵循如下两个基本原则:
-
每次优化时,必须同时优化α的两个分量,因为只优化一个分量的话,新的α就不再满足初始限制条件中的等式条件了。
-
每次优化的两个分量应当是违反g(x)目标条件比较多的。就是说,本来应当是大于等于1的,越是小于1违反g(x)目标条件就越多,这样一来,选择优化的两个分量时,就有了基本的标准。
好,我先选择第一个分量吧,α的分量中有等于0的,有等于C的,还有大于0小于C的,直觉告诉我,先从大于0小于C的分量中选择是明智的,如果没有找到可优化的分量时,再从其他两类分量中挑选。
现在,我选了一个分量,就叫它α1吧,这里的1表示它是我选择的第一个要优化的分量,可不是α的第1个分量。
为啥我不直接选两个分量呢?
我当时是这么想的,选择的两个分量除了要满足违反g(x)目标条件比较多外,还有一个重要的考量,就是经过一次优化后,两个分量要有尽可能多的改变,这样才能用尽可能少的迭代优化次数让它们达到g(x)目标条件,既然α1是按照违反g(x)目标条件比较多来挑选的,我希望选择α2时,能够按照优化后让α1、α2有尽可能多的改变来选。
你可能会想,说的怪好听的,倒要看你怎么选α2?
经过我一番潜心思考,我还真找到一个选α2的标准!!
我为每一个分量算出一个指标E,它是这样的:
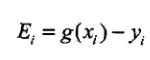
我发现,当|E1-E2|越大时,优化后的α1、α2改变越大。所以,如果E1是正的,那么E2越负越好,如果E1是负的,那么E2越正越好。这样,我就能选到我的α2啦。
啥,你问这是为什么?
这个回头再说,现在要开始优化我的α1、α2啦。
100、 无限风光在险峰
怎么优化α1、α2可以确保优化后,它们对应的样本能够满足g(x)目标条件或者违反g(x)目标条件的程度变轻呢?我这人不贪心,只要优化后是在朝着好的方向发展就可以。
本以为峰回路转,谁知道峰回之后是他妈一座更陡峭的山峰!我心一横,你就是90度的山峰,哥们我也要登它一登!!
在沉思中,我的眼睛不经意地瞟见了对偶问题:
灵光一闪,计上心来!
虽然我不知道怎样优化α1、α2,让它们对应的样本违反g(x)目标条件变轻,但是我可以让它们优化后目标函数的值变小啊!使目标函数变小,肯定是朝着正确的方向优化!也就肯定是朝着使违反g(x)目标条件变轻的方向优化,二者是一致的啊!!
我真是太聪明了!
此时,将α1、α2看做变量,其他分量看做常数,对偶问题就是一个超级简单的二次函数优化问题:
![]()
其中:
至此,这个问题已经变得超级简单了!
举例来说明一下,假设y1和y2都等于1,那么第一个限制条件就变成了
首先,将α1=K-α2代入目标函数,这时目标函数变成了关于α2的一元函数,对α2求导并令导数为0可以求出α2_new。
然后,观察限制条件,第一个条件α1=K-α2相当于
0≦K-α2≦C
进而求得:
K-C≦α2≦K,再加上原有的限制
0≦α2≦C,可得
max(K-C,0)≦α2≦min(K,C)
如果α2_new就在这个限制范围内,OK!求出α1_new,完成一轮迭代。如果α2_new不在这个限制范围内,进行截断,得到新的α2_new_new,据此求得α1_new_new,此轮迭代照样结束!!
至此,我终于找到了一个新的求解SVM对偶问题的方法,在SVM这块土地上,种上了一棵自己的树!扬名立万也就是水到渠成啦
>>>关于作者
CSDN 博客专家,2019-CSDN百大博主,计算机(机器学习方向)博士在读,业余Kaggle选手,有过美团、腾讯算法工程师经历,目前就职于Amazon AI lab。喜爱分享和知识整合。
关注微信公众号,点击“学习资料”菜单即可获取算法、编程资源以及教学视频,还有免费SSR节点相送哦。其他平台(微信/知乎/B站),欢迎关注同名公众号「图灵的猫」~