Python/打响2019年第三炮-Python爬虫入门(三)
打响2019年第三炮-Python爬虫入门
今晚喝了点茶,也就是刚刚,喝茶过程中大脑中溢出一个想法,茶中有茶叶,也有茶水,在茶水入口的一瞬间我不能直接喝进去,因为直接喝进去会带着茶叶喝进去会很难受。这可能是一句废话。
本章主要解决第一炮、第二炮遗留下来的问题,该如何去翻页爬取数据?
- 2019年第一炮
- 2019年第二炮
- 2019年第三炮------> 就在本章
等等,写到这之前我突然想到了一个问题,不得不记录一下。 因为敲代码一般都是使用两个显示器,一台测试看文档,一台去敲代码,那我突然想到,一般我们敲代码的显示器一般是放在左边还是右边。 于是找了几个资料,通过生理学所说:现代生理学表明,人的大脑分左脑和右脑两部分。左脑是负责语言和抽象思维的脑,右脑主管形象思维,具有音乐、图像、整体性和几何空间鉴别能力,对复杂关系的处理远胜于左脑,左脑主要侧重理性和逻辑,右脑主要侧重形象情感功能。 心理学方面表示,人眼睛向左看时是在想问题,经过问了几个稍微懂点的人,以及结合个人非专业的知识+百度。最后得出的结论为:一般看文档的显示器放在左边,一般敲代码的显示器放在右边。 个人理论:人在看文档也就是看原理的时候应该都会去想问题,思考,所以当人从左方看显示器时,眼睛也会向左方,所以看文档,看原理显示器放在左边比较合适,那么人在眼睛看右边显示器时候,代码一般都是有一些逻辑可以说是有一定复杂性的,正好人的右大脑对于复杂性的知识处理较快,因此经过我不专业的得出,摆放位置如下:

在上章中最终实现效果如下:

代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import csv
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
def download(url, headers, num_retries=3):
print("download", url)
try:
response = requests.get(url, headers=headers)
print(response.status_code)
if response.status_code == 200:
return response.content
return None
except RequestException as e:
print(e.response)
html = ""
if hasattr(e.response, 'status_code'):
code = e.response.status_code
print('error code', code)
if num_retries > 0 and 500 <= code < 600:
html = download(url, headers, num_retries - 1)
else:
code = None
return html
def find_Computer(url, headers):
r = download(url, headers=headers)
page = BeautifulSoup(r, "lxml")
all_items = page.find_all('li', attrs={'class' : 'gl-item'})
with open("Computer.csv", 'w', newline='') as f:
writer = csv.writer(f)
fields = ('ID', '名称', '价格', '评论数', '好评率')
writer.writerow(fields)
for all in all_items:
# 取每台电脑的ID
Computer_id = all["data-sku"]
print(f"电脑ID为:{Computer_id}")
# 取每台电脑的名称
Computer_name = all.find('div', attrs={'class':'p-name p-name-type-2'}).find('em').text
print(f"电脑的名称为:{Computer_name}")
# 取每台电脑的价格
Computer_price = all.find('div', attrs={'class':'p-price'}).find('i').text
print(f"电脑的价格为:{Computer_price}元")
# 取每台电脑的Json数据(包含 评价等等信息)
Comment = f"https://club.jd.com/comment/productCommentSummaries.action?referenceIds={Computer_id}"
comment_count, good_rate = get_json(Comment)
print('评价人数:', comment_count)
print('好评率:', good_rate)
row = []
row.append(Computer_id)
row.append(Computer_name)
row.append(str(Computer_price) + "元")
row.append(comment_count)
row.append(good_rate)
writer.writerow(row)
def get_json(url):
data = requests.get(url).json()
result = data['CommentsCount']
for i in result:
return i["CommentCountStr"], i["GoodRateShow"]
def main():
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://passport.jd.com"
}
URL = "https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&wq=%E7%94%B5%E8%84%91&pvid=1ff18312e8ef48febe71a66631674848"
find_Computer(URL, headers=headers)
if __name__ == '__main__':
main()
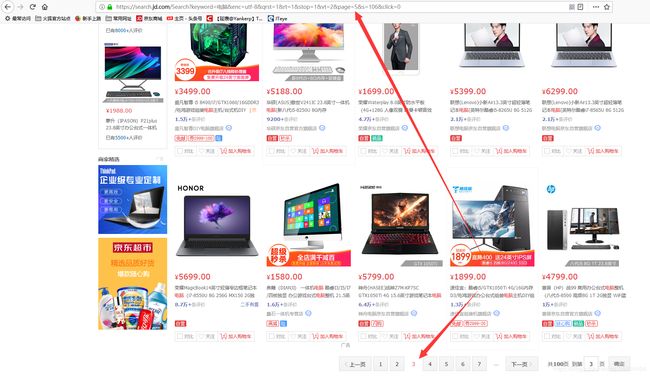
当我们打开京东去搜索某一个商品时,点击下一页来观察URL的变化

当打开第二页的时候,在URL中显示page=3如下:

以此类推当翻到第三页的时候就是page=5 以此类推-1-3-5-7-9如下:
python代码中实现1-3-5-7-9…
#!/usr/bin/env python
# -*- coding:utf-8 -*-
for page in range(1, 9, 2):
print(f"这是第{page}页")
>>>
这是第1页
这是第3页
这是第5页
这是第7页
演变如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
for page in range(1, 9, 2):
# https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=5&s=106&click=0
print(f"取到---> https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page={page}&s=106&click=0")
>>>
取到---> https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=1&s=106&click=0
取到---> https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=3&s=106&click=0
取到---> https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=5&s=106&click=0
取到---> https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=7&s=106&click=0
图:

输出结果

这样就可以取到商品的不同页面信息,只需要通过requests.get取到值,随后通过bs4找到数据即可如下:
def main():
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://passport.jd.com"
}
for page in range(1, 9, 2)
URL = f"https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page={page}&s=106&click=0""
find_Computer(URL, headers=headers)
但是需要把多页的数据存放至一个csv,所以得重写一个写入csv函数如下:
def write_csv(csv_name, data_list):
with open(csv_name, 'w', newline='') as f:
writer = csv.writer(f)
fields = ('ID', '名称', '价格', '评论数', '好评率')
for data in data_list:
writer.writerow(data)
find_Computer如下:
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import csv
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
def download(url, headers, num_retries=3):
print("download", url)
try:
response = requests.get(url, headers=headers)
print(response.status_code)
if response.status_code == 200:
return response.content
return None
except RequestException as e:
print(e.response)
html = ""
if hasattr(e.response, 'status_code'):
code = e.response.status_code
print('error code', code)
if num_retries > 0 and 500 <= code < 600:
html = download(url, headers, num_retries - 1)
else:
code = None
return html
def write_csv(csv_name, data_list):
with open(csv_name, 'w', newline='') as f:
writer = csv.writer(f)
fields = ('ID', '名称', '价格', '评论数', '好评率')
for data in data_list:
writer.writerow(data)
def find_Computer(url, headers):
r = download(url, headers=headers)
page = BeautifulSoup(r, "lxml")
all_items = page.find_all('li', attrs={'class' : 'gl-item'})
data_list = []
for all in all_items:
# 取每台电脑的ID
Computer_id = all["data-sku"]
print(f"电脑ID为:{Computer_id}")
# 取每台电脑的名称
Computer_name = all.find('div', attrs={'class':'p-name p-name-type-2'}).find('em').text
print(f"电脑的名称为:{Computer_name}")
# 取每台电脑的价格
Computer_price = all.find('div', attrs={'class':'p-price'}).find('i').text
print(f"电脑的价格为:{Computer_price}元")
# 取每台电脑的Json数据(包含 评价等等信息)
Comment = f"https://club.jd.com/comment/productCommentSummaries.action?referenceIds={Computer_id}"
comment_count, good_rate = get_json(Comment)
print('评价人数:', comment_count)
print('好评率:', good_rate)
row = []
row.append(Computer_id)
row.append(Computer_name)
row.append(str(Computer_price) + "元")
row.append(comment_count)
row.append(str(good_rate) + "%")
data_list.append(row)
return data_list
def get_json(url):
data = requests.get(url).json()
result = data['CommentsCount']
for i in result:
return i["CommentCountStr"], i["GoodRateShow"]
def main():
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"referer": "https://passport.jd.com"
}
all_list = []
for page in range(1, 9, 2):
URL = f"https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page={page}&s=106&click=0"
data_list = find_Computer(URL, headers=headers)
all_list += data_list
write_csv("csdn.csv", all_list)
if __name__ == '__main__':
main()
运行过程如下:

运行结果如下(部分截图):

希望对您有所帮助,再见~