微信词达人抓包分析
没有金刚钻不揽瓷器活,在我们开干之前首先我们需要一个好的工具,废话不多说。抓包抓包当然需要的就是一个可以抓取数据的工具软件了,提到这里小伙伴们首先想到的应该就是wireshark,这个抓包工具简直是牛X了,抓取来的数据能安照OSI 七层模型把数据分的明明白白啊。不得不说真™牛X。
不过我们今天用的工具并不是wireshark。这里又要说到Fiddler了,Fiddler是一个http协议调试代理工具
是专门针对于http,而且他有一些出色的功能,比如支持脚本,自身集成了一些非常好用的工具,比如解码工具。
Fiddler是什么原理运行的呢简单的一张图片给你解释明白。

刚才说到Fiddler是代理工具,他通过代理的方式运行在客户端服务器建立的连接之间。在客户端向服务器发送请求时,fiddler伪装成客户端接收客户端发送的请求信息,并伪装成客户端再讲请求发送到服务器去。同理,服务器响应的请求返回客户端是fiddler伪装成客户端接收,随后再伪装成服务器发送到客户端去。通过这样一种方式实现了中间信息的截取。
工欲善其事,必先利其器
这里我将工具分享给大家,绿色中文版,免去了安装,下载解压后即可使用了
链接:https://pan.baidu.com/s/1TXN3b4h0z-ky16Xw_nlceA
提取码:ddc9
拿到工具我们先运行他Fiddler.exe这里我要说明一下
这次抓包我选择的是登录PC版微信,通过Fiddler抓取本机PC版微信中词达人与服务器通信的数据,当然Fiddler既然是代理工具也可以抓取手机中微信词达人与服务器通信的数据,需要做一些配置,我不在这里详细说明了,方法网上可以百度。大致方法就是电脑共享热点给手机,手机连接电脑的WiFi与电脑处于同一局域网下,手机通过设置VPN代理的方式使手机通信数据经过运行在电脑端的Fiddler从而截取通讯数据。
我们本次抓包以PC版微信为例,不在具体演示手机端的方法。
-
运行fiddler软件,解压出来的文件中Fiddler.exe
-
设置fiddler

我们在工具中找到选项将https和连接做下图中的参数配置


-
在软件的左侧可以看到fiddler抓取到的一些正在通信的HTTP请求响应数据包

-
我们打开PC版微信进入词达人


注意主机为wap.vocabgo.com的请求,该请求地址是发送向词达人的 -
我们进入一个自学任务并选好词开始做题
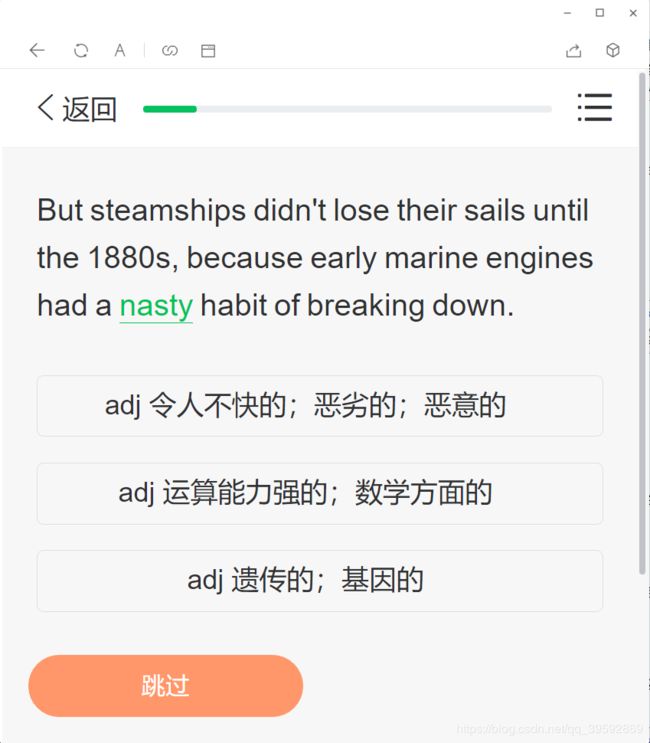
-
仔细看抓到的发送到wap.vocabgo.com的最新数据 请求的URL路径为/Student/StudyTask/StartTask

我们选中改条数据在软件右侧选中JSON面板如下图

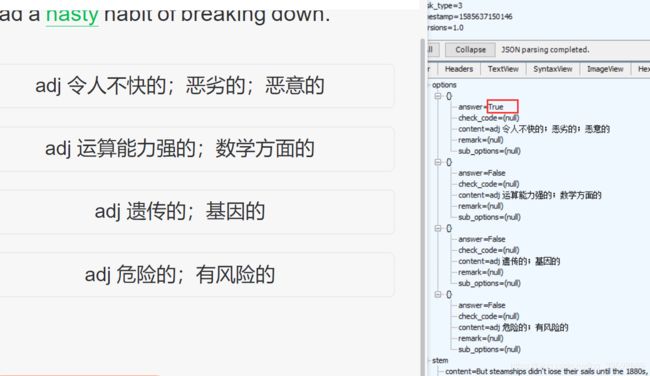
观察可见,数据中的内容与选项匹配,而且在answer后面还有true,false的标识,不难发现四个选项只有第一个是true,我们选着题的答案坑定就是他了

-
下面问题来了
我们答完题点击下一题后会发现,又抓取到了新的数据

也就是说我们每点击一次下一题都会发送一个新的请求,这样的方法获取答案是不是有些太慢了 -
新的思路,既然fiddler是支持脚本的,我们何不让其每次向改URL发送请求后都将捕获到的该URL返回的最新数据自动写入到一个txt中,我们在通过Python写脚本不断地从txt中筛选出答案输出,这样岂不是完美
-
我们打开fiddler的脚本编辑器跳转到
OnBeforeResponse
在下面插入这样几行代码
if(oSession.uriContains("https://wap.vocabgo.com/Student/ClassTask/SubmitAnswer")){
oSession.utilDecodeResponse();
oSession.SaveResponse("E:/cdr/response.txt",true);
oSession.SaveResponseBody("E:/cdr/responseBody.txt");
}
if(oSession.uriContains("https://wap.vocabgo.com/Student/StudyTask/SubmitAnswer")){
oSession.utilDecodeResponse();
oSession.SaveResponse("E:/cdr/response.txt",true);
oSession.SaveResponseBody("E:/cdr/responseBody.txt");
}
经过反复的数据分析我发现自学任务请求的URL为https://wap.vocabgo.com/Student/StudyTask/SubmitAnswer
班级任务请求的URL为https://wap.vocabgo.com/Student/ClassTask/SubmitAnswer
于是我们使用上面两个if条件,将这两个URL请求头写入到E:/cdr/response.txt
返回的数据写入到E:/cdr/responseBody.txt

这样带有答案的数据就被写入到我E盘cdr下的responseBody.txt文本中了,虽然这些数据时带有答案的,但是通过人工的方式判断难免太费心力了
10.我们来分析一下几条数据
这些东西看起来实在太乱了,一共几就这几种题型的数据我就不全部举例了,下面单只详细说一下选择题的数据
选择 {"code":1,"msg":"处理成功","data":{"task_id":5823457,"topic_index":2240,"course_id":"QXB_1","list_id":"QXB_1_2_B","word":"flame","topic_mode":11,"stem":{"content":"It uses light bulbs instead of a {flame} for cooking and turns off automatically after ten minutes.","remark":"它用灯泡而非火焰来烹饪,而且十分钟后自动熄灭。"},"options":[{"content":"noun 火焰;烈焰;火舌","remark":null,"answer":true,"check_code":null,"sub_options":null},{"content":"noun 程度;地步","remark":null,"answer":false,"check_code":null,"sub_options":null},{"content":"noun 碰撞;碰撞声","remark":null,"answer":false,"check_code":null,"sub_options":null},{"content":"noun 原则;原理","remark":null,"answer":false,"check_code":null,"sub_options":null}],"study_type":1,"task_control_id":12058073,"task_type":3,"topic_total":107,"topic_done_num":11,"tips":"选出句中划线单词词义(多义词的每项词义都会被考查)"}}
选词{"code":1,"msg":"处理成功","data":{"task_id":5824378,"topic_index":3698,"course_id":"QXB_1","list_id":"QXB_1_3_A","word":"nasty","topic_mode":31,"answer_content":[{"sen_marked":"a {nasty} attack","sen_cn":"恶意的袭击","relation":"attack","answer_str":null,"answer_arr":null},{"sen_marked":"have a {nasty} tongue","sen_cn":"毒舌","relation":"tongue","answer_str":null,"answer_arr":null},{"sen_marked":"a {nasty} habit","sen_cn":"恶习","relation":"habit","answer_str":null,"answer_arr":null}],"options":[{"content":"skill","remark":null,"answer":false,"check_code":null,"sub_options":null},{"content":"habit","remark":null,"answer":true,"check_code":null,"sub_options":null},{"content":"tongue","remark":null,"answer":true,"check_code":null,"sub_options":null},{"content":"attack","remark":null,"answer":true,"check_code":null,"sub_options":null},{"content":"experience","remark":null,"answer":false,"check_code":null,"sub_options":null},{"content":"trick","remark":null,"answer":false,"check_code":null,"sub_options":null}],"chance_num":3,"answer_num":2,"study_type":1,"task_control_id":12060478,"task_type":3,"topic_total":46,"topic_done_num":25,"tips":null}}
单词排序{"code":1,"msg":"处理成功","data":{"task_id":3402998,"topic_index":1436,"course_id":"QXB_1","list_id":"QXB_1_1_B","word":"drag","topic_mode":32,"stem":{"content":"_ _ _ _ _","remark":"把一个醉汉拖到安全地带"},"answer_content":{"sen_marked":null,"sen_cn":null,"relation":null,"answer_str":"drag a drunk to safety","answer_arr":["drag","a","drunk","to","safety"]},"options":[{"content":"drunk","remark":null,"answer":null,"check_code":null,"sub_options":null},{"content":"drag","remark":null,"answer":null,"check_code":null,"sub_options":null},{"content":"safety","remark":null,"answer":null,"check_code":null,"sub_options":null},{"content":"a","remark":null,"answer":null,"check_code":null,"sub_options":null},{"content":"to","remark":null,"answer":null,"check_code":null,"sub_options":null}],"study_type":1,"task_control_id":12059383,"task_type":3,"topic_total":38,"topic_done_num":21,"tips":"按正确顺序选择单词,组成正确的表达"}}
填空{"code":1,"msg":"处理成功","data":{"task_id":5822808,"topic_index":2041,"course_id":"QXB_1","list_id":"QXB_1_2_A","word":"estimate","topic_mode":51,"stem":{"content":"an {estimated} value","remark":"一个估计值"},"answer_content":"estimated","study_type":1,"task_control_id":12056325,"task_type":3,"topic_total":99,"topic_done_num":91,"tips":null}}
选择题第一题
{“code”:1,“msg”:“处理成功”,“data”:{“task_id”:5823457,“topic_index”:2240,“course_id”:“QXB_1”,“list_id”:“QXB_1_2_B”,“word”:“flame”,“topic_mode”:11,“stem”:{“content”:“It uses light bulbs instead of a {flame} for cooking and turns off automatically after ten minutes.”,“remark”:“它用灯泡而非火焰来烹饪,而且十分钟后自动熄灭。”},“options”:[{“content”:“noun 火焰;烈焰;火舌”,“remark”:null,“answer”:true,“check_code”:null,“sub_options”:null},{“content”:“noun 程度;地步”,“remark”:null,“answer”:false,“check_code”:null,“sub_options”:null},{“content”:“noun 碰撞;碰撞声”,“remark”:null,“answer”:false,“check_code”:null,“sub_options”:null},{“content”:“noun 原则;原理”,“remark”:null,“answer”:false,“check_code”:null,“sub_options”:null}],“study_type”:1,“task_control_id”:12058073,“task_type”:3,“topic_total”:107,“topic_done_num”:11,“tips”:“选出句中划线单词词义(多义词的每项词义都会被考查)”}}
这些动看起来可真是头疼,在没有fiddler的JSON面板格式下真是乱成一团
,我们先去提取有用的数据,其他的就先不要管在options:中content:后面的文字肯定就是选项了,我们要输出的肯定是content后面的文字。但是也不能都输出啊,那么answer后面的true/false肯定就用来判定了,这里思路就很清晰了,用Python写个脚本,读取txt中的数据,去提取options中的选项数据,逐条根据answer判定,当为true时将其条选项content中的内容输出。
- 于是我就这样写好了脚本,果然能够运行,但是当题型切换到短语的呢个出问题了,这个题要选多个选项并分析其题型数据,这个题不是按照true/false判定的,而且填空题也不是,于是我们就需要单独根据选词和填空题题单独写脚本,若是这样岂不是太麻烦,切换题型后还要手动切换脚本。我断定在数据中肯定有条数据是用来判断区分题型的
- 就这样我不断地切换题型切换不同单元抓取数据分析发现"topic_mode":后面的数字是用来判定题型的,不同的题型数值不一,但是在不同的单元中相同题型其数字是相同的,这样条数据就可以用来区分题型了。下面是脚本思路:
我们先根据topic_mode来判断题型使用if嵌套,匹配题型后执行if后的语句根据题型特点提取答案并输出
这样就完美解决了所有问题。
下面附上Python代码,在这里首先感谢一下我多年的好友,一位Python大牛,浩浩同学根据我的要求为为提供的Python代码
import re
import json
import time
files = []
def read():
with open("responseBody.txt", "r",encoding='utf-8') as f:
data = f.read()
files.append(data)
return data
def main(data):
if(data['data']['topic_mode'] in [51]):
print(data['data']['answer_content']+"\n"+"-----------------------")
elif(data['data']['topic_mode'] in [11,22,42]):
options = data['data']['options']
for option in options:
if(option['answer']==True):
print(option['content']+"\n"+"-----------------------")
elif(data['data']['topic_mode'] in [32]):
print(data['data']['answer_content']['answer_str'])
print("\n"+"-----------------------")
elif(data['data']['topic_mode'] in [31]):
options = data['data']['options']
for option in options:
if(option['answer']==True):
print(option['content'])
print("-----------------------")
if __name__ == '__main__':
while True:
data=read()
main(json.loads(data))
time.sleep(0.8)
- 将Python打包成EXE运行一下给大家展示一下成果



嗯嗯,效果还不错
哈哈哈 - 以上的部分看完相信你也能自己动手做出这个词达人辅助工具了
- 下面我给大家分享一下我的发现,并希望能够找到投合的大佬继续深入研究
- 第一个问题是,我发现在答题完成后点击下一题本地并没有将作答结果提交会服务器,而是发送了下一道题的请求。还有就是为什么请求的题目会将答案与题目一块返回过来,这可能说明了两个问题,1这是傻X行为 2印证了上面所说没有提交作答结果,这就很可能是作答在本地做了判断运算,但是
每一个单词都是有分数的,分数是如何提交上去的呢?我认为是在本地运算作判定,直到最后一题作答完后,本地将所有的运算结果整理后向服务器提交一次数据作为分数。也就是说我们的作答判定是在本地进行的,不是提交到服务器进行的。这恰巧符合为什么数据选项会将答案一并返回给客户端。 - 假设上述观点成立,有没有这样一种可能,我们将做题的过程省略,我们只需抓取到最后的判定汇总,给他修改成想要的结果,模拟最后一次提交成绩数据的发包给服务器。这样就完成了一套题并省略了答题过程。
- 以上思路就是我想到的所有可能,可能会有不妥和不足之处,希望各路大佬指点,不喜勿喷。毕竟本人小白出身功底甚差。如果各位有思路欢迎一同探讨。