使用scrapy爬取图片
一 半自定义方法
这里我们以美食杰为例,爬取它的图片,作为演示,这里只爬取一页。美食杰网址
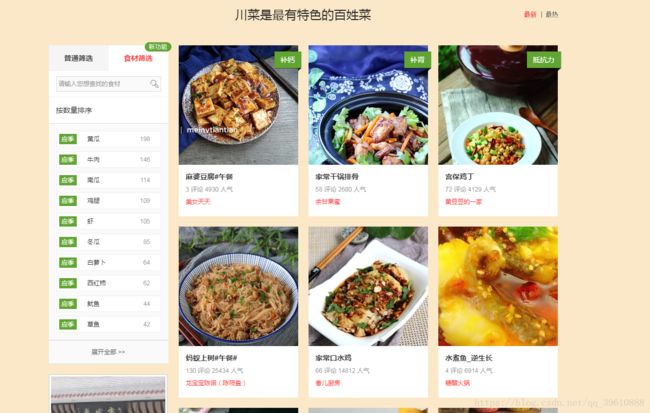
1 首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject meishi, 接着根据提示cd meishi, 再cd meishi,
, 下来写 scrapy genspider mei meishij.net ,生成如图所示文件。
(关于以上命令的讲解不在这次写的范围内)
2 点进如图所示的mei.py 文件,这里需要注意,要将start_urls[] 改为我们要爬取的Url 地址,然后根据xpath爬取图片
(这里放图片而不放源码得原因是,代码得自己写,不要复制)

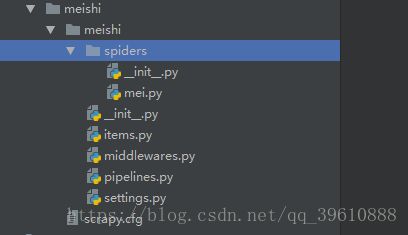
3 进入到items 文件,她来处理刚刚得到的文件
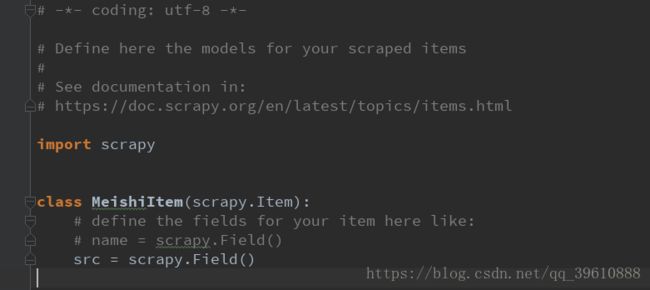
4 进入到mei.py 文件,引入items这个文件的函数,并进行输出,因为src是图片,所以要用[]括起来

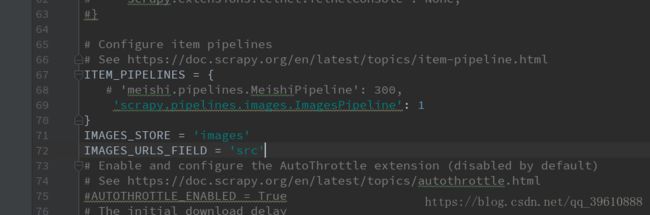
5 在settings.py 里进行设置,大致在67行前后的位置,自己定义下载。
最后两句代码,IMAGES_STORE = ’ ’ 里面写图片保存的路径
IMAGES_URLS_FIELD=’ ’ 里面写接收图片的变量
6 在命令行输入 scrapy crawl mei 点击确认,看到如图所示,表示成功

2 使用系统的方法
上面的方法虽然能爬取下来图片,但是图片的名字是scrapy 根据某些规则(哈希) 为我们命名的,但是我们想用图片原本的名字进行命名时,这种方法就明显不行了, 这时需要另外一种办法了。
下面,将以站长素材网为例,爬取图标,并根据名字保存下来 网址
1 上面已经介绍了如何创建scapy的方法,这里不再赘述,还是和上面一样,使用xpath提取我们想要的数据,
这里我们需要两个数据,一个是标题,一个是每一个详细图片的链接地址,

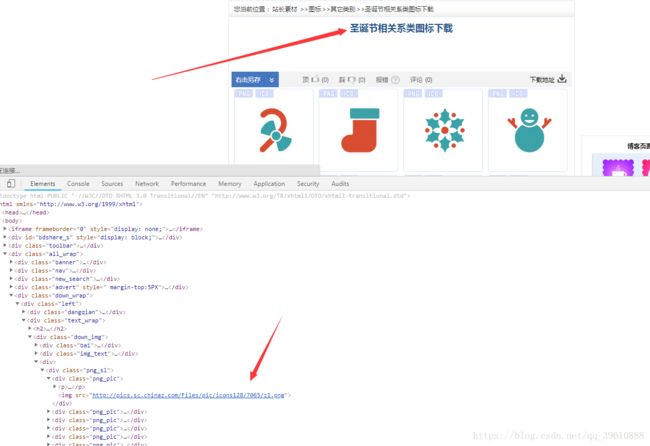
2 首先进入刚才给的网址,提取每一页的详细链接,使用callback=‘下一个函数的名字‘’
这里需要注意,把函数自带的括号删掉。
关于item配置,跟上面的一样,这里title表示提取出来的标题,src 表示每一个图片的详细链接
(xpath方法写的很烂,最精简的应该是,查看F12 点到你要提取的元素–>右击–>copy–>copy_Xpath, 这个以前介绍过)
接下来配置Items 跟上面一样,这次多了一个title
# -*- coding: utf-8 -*-
import scrapy
from ..items import ZhanzhangItem
class ZhanSpider(scrapy.Spider):
name = 'zhan'
allowed_domains = ['sc.chinaz.com']
start_urls = ['http://sc.chinaz.com/tubiao/']
def parse(self, response):
href_list = response.xpath('//div[@class="text_left"]//li/span/a/@href').extract()
for href in href_list:
yield scrapy.Request(url=href, callback=self.get_info)
def get_info(self, response):
div_list = response.xpath('//div[@class="all_wrap"]//div[@class="left"]')
for div in div_list:
title = div.xpath('.//div[2]/h2/a/text()').extract_first('')
src_list = div.xpath('.//div[@class="png_pic"]/img/@src').extract()
for src in src_list:
item = ZhanzhangItem()
item['title'] = title
item['src'] = [src]
yield item3 进入到settings.py 设置如图所示

4 写关于下载的函数, 我们进入到pipelines.py 文件, 我这里把原类注释掉了,也可以在里面直接写,
但是函数的名字是固定的,
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
# ImagesPipeline 为系统中下载图片的管道
from scrapy.pipelines.images import ImagesPipeline
#
# class ZhanzhangPipeline(object):
# def process_item(self, item, spider):
# return item
# 这个类的意思是,继承里系统中下载图片的功能
class ZhanzhangPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['src'][0],meta={'item':item})
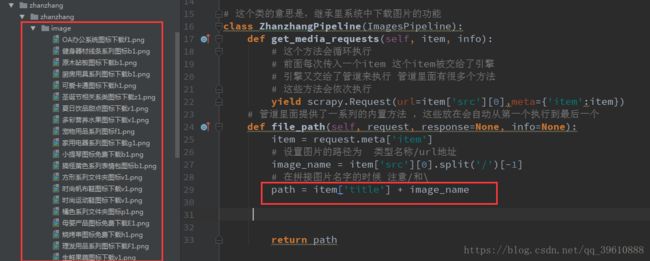
def file_path(self, request, response=None, info=None):
item = request.meta['item']
# 设置图片的路径为 类型名称/url地址
# 这是一个图片的url: http://pics.sc.chinaz.com/Files/pic/icons128/7065/z1.png
# 这句代码的意思是先取出图片的url,[0]表示从列表转成字符串
# split分割再取最后一个值,这样写是让图片名字看起来更好看一点
image_name = item['src'][0].split('/')[-1]5 文件保存 ,还是刚才的pipelines文件,关于文件保存有两种:
第一种方式:
(以下代码应该接在上面代码的后面,分开来写是因为这样更能讲的清楚)
# 这样写是保存在一个文件夹里面,注意最后是以'.jpg' 结尾
# path = item['title'] + image_name命令行运行scrapy crawl zhan ,如图所示
第二种方式:
# 这样写是保存在不同的文件夹中,根据title来为文件夹命名,路径下是图片的名字,还是以.jpg结尾的
path = '%s/%s' % (item['title'], image_name)
return path
最后,我们使用第二种方式整体运行一下,会得到如下图所示

(在上面我倒数第二个图片里面,每个文件夹只有一个图片,跟提取src数量有关,这些写的原因是图片数量太多,刚开始写的时候,每次只取一个,测试起来方便)
上面个的我都是是爬取了一页,要是想爬取所有页面,可以根据网页的下一页源码,进行提取,这里以美食杰为例,简单介绍一下
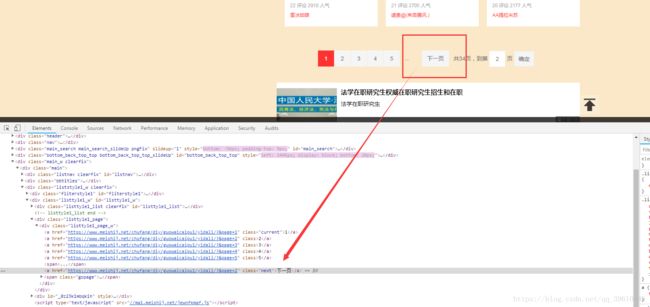
在刚才美食杰的mei.py文件里,加入如下代码:

以上就是简单的使用scrapy 爬取图片的方式,当然scrapy还可爬取其他东西,保存成json,csv等,我将在下一篇中介绍