利用Python提取视频中的字幕(文字识别)
学了好久机器学习的内容有些许枯燥,今天我们来做一个Python的小项目来玩耍吧!

文字识别
- 项目背景
- 需求阐述
- 思路
- 首先导包
- 代码详情
- 裁剪视频
- 创建文本
- 判断中文
- 截取字幕
- 访问百度API
- 读取图片&字幕操作
- 主方法控制台输出运行
项目背景
通过获取百度API实现视频文字识别。
需求阐述
将.MP4格式视频裁剪成一帧一帧的图片再将图片中的字幕摘取出来,保存成一个文档。
进入正题喽!!!
思路
1.将视频按帧截取成图片
2.将上一步截取的图片再进行裁剪,只保留字幕部分,然后在进行灰度处理
3.调用百度api识别文字
4.输出成txt
首先导包
# base64是一种将不可见字符转换为可见字符的编码方式
import base64
# opencv是跨平台计算机视觉库,实现了图像处理和计算机视觉方面的很多通用算法
import os
import cv2
import requests
from aip import AipOcr
# 百度AI的文字识别库
base64 base64是一种将不可见字符转换为可见字符的编码方式。
opencv 是跨平台计算机视觉库,实现了图像处理和计算机视觉方面的很多通用算法。
AipOcr 百度AI的文字识别库。
注意:
这里from aip import AipOcr刚开始可能会报错,原因可能是aip和baidu-aip根本不是同一个包,如果想要import的时候,都是使用:import aip
之后pip install baidu-aip就没报错了。
代码详情
裁剪视频
def tailor_video():
# 要提取视频的文件名,隐藏后缀
sourceFileName = 'material'
# 在这里把后缀接上
video_path = os.path.join("G:/material/", sourceFileName + '.mp4')
times = 0
# 提取视频的频率,每10帧提取一个
frameFrequency = 10
# 输出图片到当前目录video文件夹下
outPutDirName = 'G:/material/video/' + sourceFileName + '/'
if not os.path.exists(outPutDirName):
# 如果文件目录不存在则创建目录
os.makedirs(outPutDirName)
camera = cv2.VideoCapture(video_path)
while True:
times += 1
res, image = camera.read()
if not res:
print('not res , not image')
break
if times % frameFrequency == 0:
cv2.imwrite(outPutDirName + str(times) + '.jpg', image) #文件目录下将输出的图片名字命名为10.jpg这种形式
print(outPutDirName + str(times) + '.jpg')
print('图片提取结束')
这里定义一个函数用来裁剪视频。
我们需要将视频裁剪成一帧一帧的图片,将图片保存成10.jpg这种形式,并且将这些裁剪后的图片放在一个目录下。
这里我设置的是每10帧裁剪一张,你也可以任意设置多少帧裁剪。
视频裁剪后的图片效果:
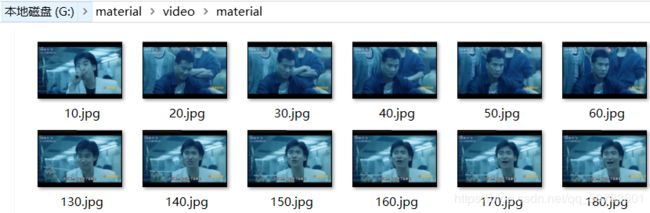
创建文本
def text_create(name, msg):
desktop_path = "G:/material/" # 新创建的txt文件的存放路径
full_path = desktop_path + name + '.txt' # 也可以创建一个.doc的word文档
file = open(full_path, 'w')
file.write(msg)
file.close()
这里创建一个函数,用来存放提取后的文字信息。
创建.txt文本存放提取后的文字。
判断中文
# 定义一个函数,用来判断是否是中文,是中文的话就返回True代表要提取中文字幕
def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
定义一个函数,用来判断是否是中文,是中文的话就返回True代表要提取中文字幕,不是中文的就返回False。
截取字幕
def tailor(path1,path2,begin,end,step_size): #截取字幕
for i in range(begin,end,step_size):
fname1=path1 % str(i)
print(fname1)
img = cv2.imread(fname1)
print(img.shape)
cropped = img[500:600, 100:750] # 裁剪坐标为[y0:y1, x0:x1]
imgray = cv2.cvtColor(cropped, cv2.COLOR_BGR2GRAY)
thresh = 200
ret, binary = cv2.threshold(imgray, thresh, 255, cv2.THRESH_BINARY) # 输入灰度图,输出二值图
binary1 = cv2.bitwise_not(binary) # 取反
cv2.imwrite(path2 % str(i), binary1)
对字幕进行灰度处理,目的是使截取的字幕更加清晰。
如下效果:
裁剪视频得到的图片(其一):

截取字幕后:

进行灰度处理后

对于灰度处理,二值化处理不明白的可以参考如下文章。
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/imgproc/threshold/threshold.html
https://blog.csdn.net/qq_37385726/article/details/82015545
访问百度API
# 定义一个函数,用来访问百度API,
def requestApi(img):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
params = {"image": img,'language_type':'CHN_ENG'}
access_token = '24.b802cd212b0e702b018f999c594b6d9f.2592000.1589466832.282335-19430506'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
results=response.json()
return results
这里的access_token是这么来的:
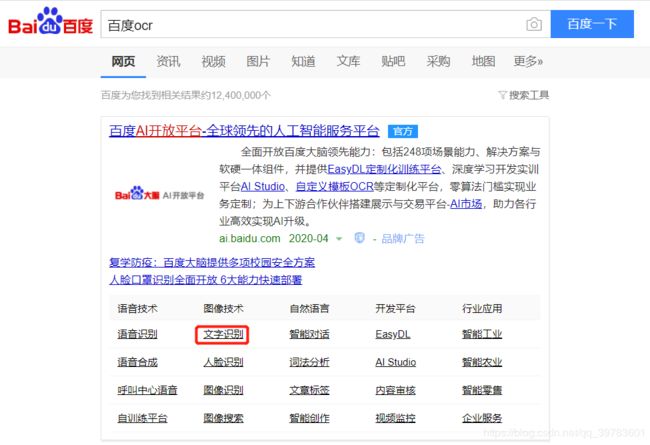
首先你需要百度搜索:百度ocr—— 点击文字识别
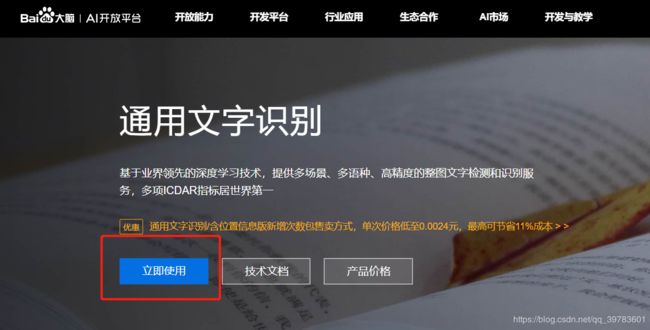
第二步:点击立即使用
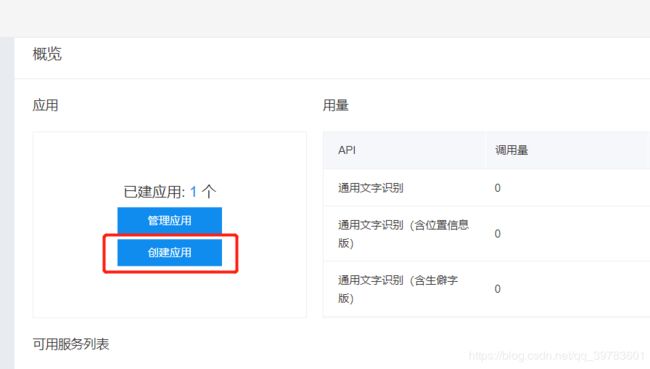
第三步:创建应用
第四步:随便填写一个名称,然后立即创建。
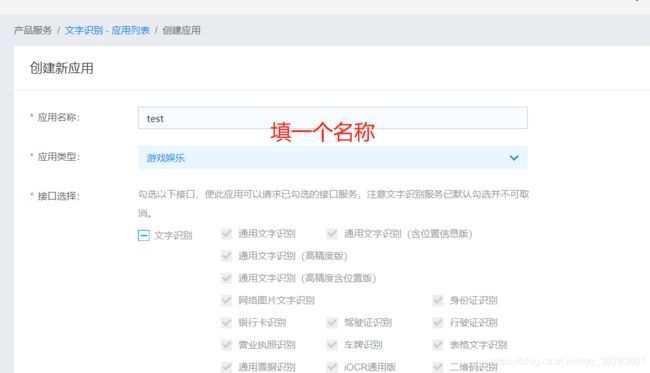
创建成功后你就会看到你刚才创建的一个应用test。
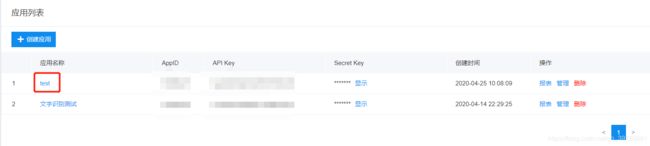
此时,我们需要这里的API Key和Secret Key两个参数中的内容,用来获取access_token的内容。

接下来第五步点击技术文档
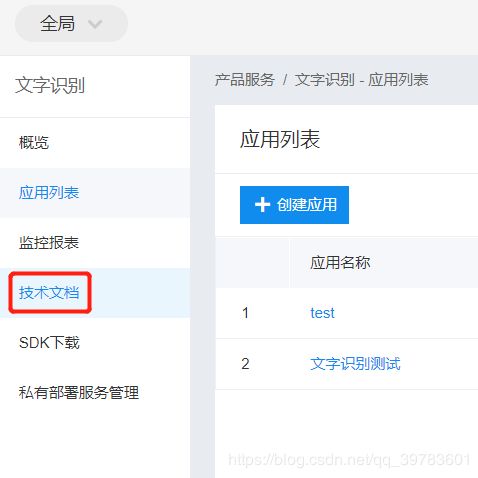
第六步:点击通用文字识别
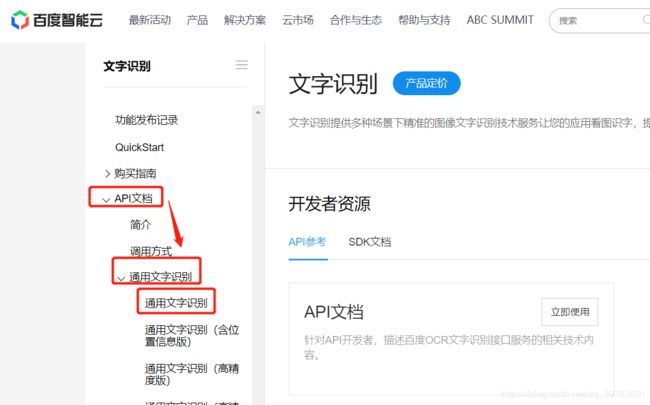
这里有access_token相关的介绍,可以点击Access Token获取查看详情。
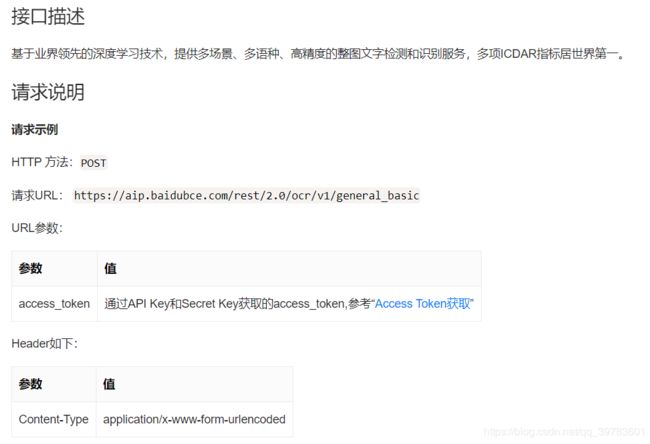
详情介绍了如何获取Access Token。
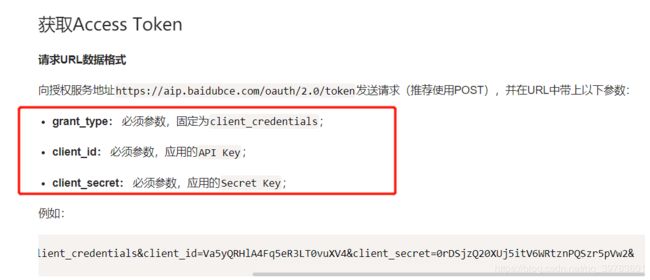
复制下面链接到浏览器:
https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=Va5yQRHlA4Fq5eR3LT0vuXV4&client_secret=0rDSjzQ20XUj5itV6WRtznPQSzr5pVw2&
替换对应如下的内容,就是上面创建应用test后得到的API Key和Secret Key两个参数中的内容,对应替换。
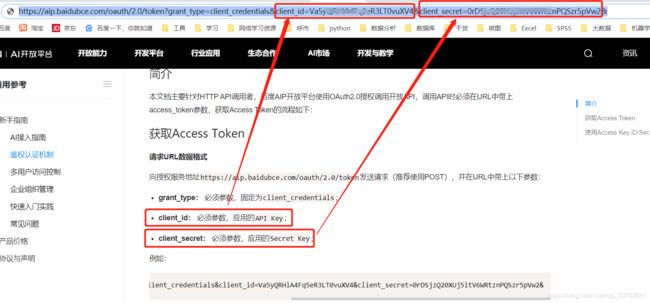
替换后回车就会得到:access Token的值。

其他代码中剩余的参数可以自行设置。
读取图片&字幕操作
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
# 将读取出来的图片转换为b64encode编码格式
return base64.b64encode(fp.read())
# 定义函数字幕,用来对字幕进行操作
# step_size 步长
def subtitle(fname,begin,end,step_size):
array =[] #定义一个数组用来存放words
for i in range(begin,end,step_size): #begin开始,end结束,循环按照步长step_size遍历,共有419张图片,也就是(1,420,10)
fname1=fname % str(i)
print(fname1)
image = get_file_content(fname1)
try:
results=requestApi(image)['words_result'] #调用requestApi函数,获取json字符串中的words_result
for item in results:
print(results)
if is_Chinese(item['words']):
array.append(item['words'].replace('猎奇笔记本', '')) # 将图片中不需要的字幕“猎奇笔记本”替换为空
except Exception as e:
print(e)
text=''
result = list(set(array)) # 将array数组准换为一个无序不重复元素集达到去重的效果,再转为列表
result.sort(key=array.index) # 利用sort将数组中的元素即字幕重新排序,达到视频播放字幕的顺序
for item in result:
print(item)
text+=item+'\n'
text_create('test1',text)
首先需要对读取到的图片进行转码,转为b64encode编码格式。
其中,在图片识别时候可能会识别到除字幕外的文字,我们还需要将图片中不需要的文字替换为空,只获取字幕。
例如:此处我们需要将“猎奇笔记本”替换为空。

主方法控制台输出运行
if __name__ =="__main__":
path1 = 'G:/material/video/img/%s.jpg' # 视频转为图片存放的路径(帧)
path2 = 'G:/material/video/img2/%s.jpg' # 图片截取字幕后存放的路径
print("""
1.图片裁剪
2.提取字幕
3.裁剪视频
""")
choose=input()
begin=100
end=1000
step_size=10
if choose=='1':
tailor(path1,path2,begin,end,step_size)
if choose=='2':
subtitle(path2,begin,end,step_size)
if choose=='3':
tailor_video()
结果:
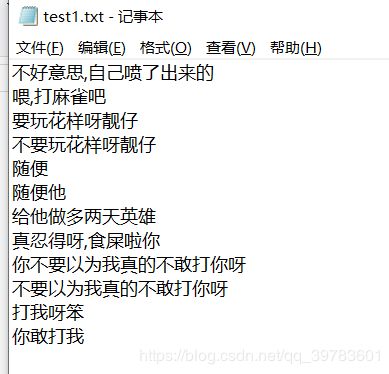
结果中精确度还不是很高,不过80%的文字都提取到了还算可以哦。这次只是做了一个小小的练习,代码还可以继续优化,获取到的字幕还能够更加准确哦。
