Python面试题
吐槽一下,互联网行业应届生确实好难找工作,顺便整理一下最近遇到过的一些面试题:
个人解答,如需专业解答请面向百度/谷歌。
爬虫
1 response.text与response.content的区别
response.text是字符串(比如网页静态的html),response.content是二进制流(一般用来保存图片、音频、视频等),
还有一个response.json(返回的是json格式的数据,如果不是json格式的数据调用这个会报错)2 re/xpath/beautifulsoup 需要导入哪些包(手写)
import re
from bs4 import beautifulsoup
from lxml import etree
Xpath: selector = etree.HTML(html)
result = selector.xpath('//a/text()')3.mongodb从导包,连接到插入/更新/查找数据(手写)
from pymongo import MongoClient
connect = MongoClient('mongodb://username:password@localhost:port')
db = connect['testdb']
collection = db['test']
collection.insert(d)
collection.update()
collection.find()4 图片验证码/滑动验证码如何处理
图片验证码(中英混合): 使用tesserocr识别技术对图片的文本进行解析,识别率可能较低,可以采用改变其灰度,
二值化等操作来提升识别效率,还可以利用深度学习训练机器识别验证码,自己下载10万
张验证码来训练电脑对图片的识别准确率。
滑动验证码:使用selenium模拟登陆,出现验证码的时候截取屏幕上验证码图片,一般会有两张,一张是完整的,一张
是有缺口的,通过对比找出这两个图片的缺口坐标,然后使用selenium模拟点击滑动块滑动至缺口部分,
(注意:必须要模拟人为拖动,人的正常行为是先加速,后减速。如果使用匀速或者随机速度,都会无法
通过验证,V=V0+at)
点触验证码:识别难度比较大,建议使用打码软件,调用打码平台的接口(比如超级鹰),上传图片至接口,会返回正确
识别后的坐标,然后模拟点击即可,如果无法识别,不会扣除积分。5 免费的ip代理池如何处理有效率很低的情况,怎么优化
自己通过爬取西刺代理的免费IP代理池,可以通过对IP进行评分,比如拿这个IP的时候,调用访问一个网站,如果r.status
为200,则评分100,如果r.status为其他数值,则降低评分20,如果评分小于0则剔除列表,然后对列表进行排序,每次取
评分靠前的IP。6.selenium从导包到模拟登陆(手写)
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
7.布隆过滤器是怎么实现的,实战中用过吗
利用Hash实现,缺点:会有误差率8 https和http的区别,requests里面怎么取消ssl验证
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
requests.get(url,verify=false) # 这样就可以进入12306的网站而不需要通过证书了9 scrapy的整个流程说出来
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1.引擎从调度器中取出一个链接(URL)用于接下来的抓取
2.引擎把URL封装成一个请求(Request)传给下载器
3.下载器把资源下载下来,并封装成应答包(Response)
4.爬虫解析Response
5.解析出实体(Item),则交给实体管道进行进一步的处理
6.解析出的是链接(URL),则把URL交给调度器等待抓取10 MongoDB和MySQL的区别
一、关系型数据库-MySQL
1、在不同的引擎上有不同的存储方式。
2、查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
3、开源数据库的份额在不断增加,mysql的份额页在持续增长。
4、缺点就是在海量数据处理的时候效率会显著变慢。
二、非关系型数据库-MongoDB
非关系型数据库(nosql ),属于文档型数据库。先解释一下文档的数据库,
即可以存放xml、json、bson类型系那个的数据。这些数据具备自述性,呈现分层的树状数据结构。数据结构由键值(key=>value)对组成。
1、存储方式:虚拟内存+持久化。
2、查询语句:是独特的MongoDB的查询方式。
3、适合场景:事件的记录,内容管理或者博客平台等等。
4、架构特点:可以通过副本集,以及分片来实现高可用。
5、数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
6、成熟度与广泛度:新兴数据库,成熟度较低,Nosql数据库中最为接近关系型数据库,比较完善的DB之一,适用人群不断在增长。11 模拟登陆百度贴吧,实现自动批量回帖,不能被封号,正常情况下回帖5-6个就会被封号
暂时未做出来,封号问题无法有效解决,账号有限--!基础算法
1 有一对兔子,生长三个月后。开始生第一对兔子,并且以后每月生一对兔子,小兔子生长三个月后,也开始生兔子,问N个月后兔子的总数量
递归:
def foo(n):
if n == 0:
print('Error')
elif n == 1 or n == 2:
return 1
else:
return foo(n - 1) + foo(n - 2)
非递归:
def bar(n):
a = b = 1
c = 0
time = 3
while time <= n:
c = a + b
a, b = b, c
time += 1
return c2 冒泡排序、快速排序、选择排序算法实现
冒泡排序:
def bubbleSort(nums):
for i in range(len(nums)-1): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(nums)-i-1): # j为列表下标
if nums[j] > nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums
# 效率较低
快速排序:
def QuickSort(myList,start,end):
#判断low是否小于high,如果为false,直接返回
if start < end:
i,j = start,end
#设置基准数
base = myList[i]
while i < j:
#如果列表后边的数,比基准数大或相等,则前移一位直到有比基准数小的数出现
while (i < j) and (myList[j] >= base):
j = j - 1
#如找到,则把第j个元素赋值给第个元素i,此时表中i,j个元素相等
myList[i] = myList[j]
#同样的方式比较前半区
while (i < j) and (myList[i] <= base):
i = i + 1
myList[j] = myList[i]
#做完第一轮比较之后,列表被分成了两个半区,并且i=j,需要将这个数设置回base
myList[i] = base
#递归前后半区
QuickSort(myList, start, i - 1)
QuickSort(myList, j + 1, end)
return myList
选择排序:
s = [3, 4, 1, 6, 2, 9, 7, 0, 8, 5]
# select_sort
for i in range(0, len(s) - 1):
index = i
for j in range(i + 1, len(s)):
if s[index] > s[j]:
index = j
s[i], s[index] = s[index], s[i]
# print sort result.
for m in range(0, len(s)):
print(s[m])基础算法原理题
1 爬虫的广度优先算法和深度优先算法如何实现?
广度优先算法:队列实现。面试官告诉我用redis的队列即可实现。
深度优先算法:堆栈实现。面试官告诉我用redis使用递归实现。2 redis实现爬取多个网站的优先级
我的回答是对url进行筛选之后排序,但是有一个弊端,就是如果数量级过大,那么效率很低。
正确做法是使用redis开两个队列即可。3 hash底层是如何实现的
等待更新中,暂时不太了解4 冒泡,快速排序等算法的应用场景
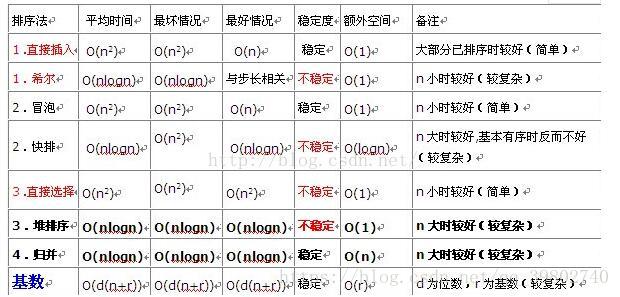
5 redis集群怎么搭建
比如一个master三个salve为一个节点,十几个节点即可组成一个集群。
如果master挂了,那么哨兵会监控,salve投票选举一个上岗。
如果master回归,那么会变成salve,可以设置有效时间,在固定时间内回来即可,否则变成salve。6 redis有哪几种数据类型,zset是怎么实现的?
字符串类型:页面缓存、查询结果缓存、计数、共享Session、限速
哈希类型:查询结果缓存、将关系数据库的表映射到内存中
列表类型:消息队列
集合类型:维护标签(例如:给用户贴标签、根据标签找用户)
有序集合类型:排行榜
(zset和set也是string类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数却可以重复)
另外提到了redis是将数据存储到内存中的非关系型数据库
读写性能优异
持久化、数据类型丰富、单线程、数据自动过期、发布订阅、分布式7 response获取后的数据怎么处理,是直接入库吗?这样有缺陷
未知8 谈谈Python里的异步
我回答的是和ajax异步请求一样,面试官告诉我不太一样。
他应该是想问asyncio异步编程
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式。
不相关的程序单元之间可以是异步的。
例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该
下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相
互通知协调。这些异步操作的完成时刻并不确定。简言之,异步意味着无序。