python数据分析之爬虫三:BeautifulSoup库爬虫实例
实例一:中国大学排名定向爬虫
网址.:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
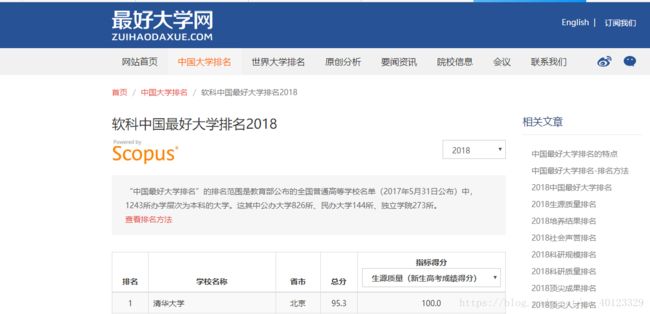

查看定向爬虫的可行性

每个大学以tr标签开始,每个大学的每项信息都以td标签开始。
判断定向爬虫的可行性:打开robots协议看是否有爬虫限制
http://www.zuihaodaxue.cn/robots.txt

并没有爬虫限制。
功能描述

程序结构设计


主函数的框架如下:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
return ""
def fillUnivList(ulist,html):
pass
def printUnivList(ulist,num):
print('Suc'+str(num))
def main():
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
main()填充各子函数
getHTMLText()

fillUnivList()

format函数格式:

printUnivList()

总体代码:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])#第二个是位置
def printUnivList(ulist,num):
print("{:^10}\t{:^10}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^10}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
main()
输出结果:

输出的结果中中文对齐并不是很理想。

我们可以设定当中文字符宽度不够时,采用中文字符的空格填充chr(12288) chr(12288)表示一个中文空格。
修改代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])#第二个是位置
def printUnivList(ulist,num):
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"#{3}表示学校名称填充时使用format第三个下标对应的填充方式
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
main()效果如下:

把爬取的成果输出到excel文件中去
import requests
import bs4
from bs4 import BeautifulSoup
import pandas as pd
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])#第二个是位置
def SaveUnivList(ulist,num):
path=r"C:\Users\LPH\Desktop\paiming.xlsx"
a=ulist[:num]
print(a)
a=pd.DataFrame(a,columns=['排名','学校名称','评分'])
a.to_excel(path,index=False)
def main():
uinfo=[]
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
fillUnivList(uinfo,html)
SaveUnivList(uinfo,20)
效果如下:

注意:爬取的数字是文本数字,要把文本数字改为数字。具体可以百度:Excel如何批量将文本格式的数字改为数值格式。
又自己码了一遍。。。。。
import requests
import bs4
from bs4 import BeautifulSoup
import pandas as pd
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(univl,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
univl.append([tds[0].text,tds[1].contents[0].text,tds[3].text])
def saveUnivList(univl,num,path):
univl=univl[:num]
print(univl)
a=pd.DataFrame(univl,columns=['大学排名','学校名称','分数'])
a.to_excel(path,index=False)
def main():
num=int(input("please input the number of universities you want to learn about:"))
url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html=getHTMLText(url)
univl=[]
path=r'C:\Users\LPH\Desktop\daxuepaiming.xlsx'
fillUnivList(univl,html)
saveUnivList(univl,num,path)
main()