5、Linux ElasticSearch 集群配置
写在前面:为什么要用ElasticSearch?我们的应用经常需要添加检索功能,开源的Elastic Search是目前全文检索引擎的首选。它可以快速的存储、搜索和分析海量数据。ElasticSearch是一个分布式搜索框架,提供RestfulAPI,底层基于Lucene,采用多shard(分片)的方式保证数据安全,并且提供自动resharding的功能。
Elasticsearch: 权威指南(中文):https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
一、拉取ElasticSearch镜像
在centos窗口中,执行如下命令:
docker pull elasticsearch:6.4.3 # 与你集群 jar 的版本号要一致。
当前ES镜像版本信息:
docker inspect docker.io/elasticsearch:6.4.3
二、创建数据挂在目录,以及配置ElasticSearch集群配置文件,调高JVM线程数限制数量
2.1 创建数据文件挂载目录,并开放通信端口
在centos窗口中,执行如下操作:
➜ tool pwd
/root/tool
➜ tool mkdir -p ES/config
➜ tool cd ES
➜ ES mkdir data1
➜ ES mkdir data2
➜ ES mkdir data3
➜ ES cd config
➜ config firewall-cmd --add-port=9300/tcp
Warning: ALREADY_ENABLED: '9300:tcp' already in 'public'
success
➜ config firewall-cmd --add-port=9301/tcp
success
➜ config firewall-cmd --add-port=9302/tcp
success
➜ config cd ../
➜ ES chmod 777 data1 data2 data3
注:如果ELK选的6.X版本的,那么读者需将data1 data2 data3 开启777权限=> chmod 777 data1 data2 data3
2.2 创建ElasticSearch配置文件
在centos窗口中,使用vim命令分别创建如下文件:es1.yml,es2.yml,es3.yml
es1.yml 最好把注释祛除,Linux 空格与 Windows 下不同
➜ config cat es1.yml
cluster.name: elasticsearch-cluster # 集群名称
node.name: es-node1 # 节点名称
network.bind_host: 0.0.0.0 # 节点服务器对应ip,生产环境对应host
network.publish_host: 192.168.26.22 # 同上 两行代码灯影network.port:192.168.26.22 未验证
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.26.22:9300","192.168.26.22:9301","192.168.26.22:9302"]
discovery.zen.minimum_master_nodes: 2
es2.yml
➜ config cat es1.yml
cluster.name: elasticsearch-cluster
node.name: es-node2
network.bind_host: 0.0.0.0
network.publish_host: 192.168.26.22
http.port: 9201
transport.tcp.port: 9301
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.26.22:9300","192.168.26.22:9301","192.168.26.22:9302"]
discovery.zen.minimum_master_nodes: 2
es3.yml
➜ config cat es1.yml
cluster.name: elasticsearch-cluster
node.name: es-node3
network.bind_host: 0.0.0.0
network.publish_host: 192.168.26.22
http.port: 9202
transport.tcp.port: 9302
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.26.22:9300","192.168.26.22:9301","192.168.26.22:9302"]
discovery.zen.minimum_master_nodes: 2
注:本机虚拟机ip:192.168.26.22 请自行更改
2.3 调高JVM线程数限制数量
在centos窗口中,修改配置sysctl.conf
vi /etc/sysctl.conf
加入如下内容:
vm.max_map_count=262144
启用配置:
sysctl -p
注:这一步是为了防止启动容器时,报出如下错误:
bootstrap checks failed max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
三、启动ElasticSearch集群容器
启动ElasticSearch集群容器
在centos窗口中,执行如下命令:
# 使用镜像 elasticsearch:6.4.3,(-d)以后台模式启动一个容器,将容器的 9300 端口映射到主机的 9300 端口,主机的目录 url 映射到容器的 url,容器的别名为ES01
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 -v /root/tool/ES/config/es1.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/tool/ES/data1:/usr/share/elasticsearch/data --name ES01 elasticsearch:6.4.3
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9201:9201 -p 9301:9301 -v /root/tool/ES/config/es2.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/tool/ES/data2:/usr/share/elasticsearch/data --name ES02 elasticsearch:6.4.3
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9202:9202 -p 9302:9302 -v /root/tool/ES/config/es3.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/tool/ES/data3:/usr/share/elasticsearch/data --name ES03 elasticsearch:6.4.3
注:设置-e ES_JAVA_OPTS="-Xms256m -Xmx256m" 是因为/etc/elasticsearch/jvm.options 默认jvm最大最小内存是2G,读者启动容器后 可用docker stats命令查看
四、验证是否搭建成功
4.1在浏览器地址栏访问http://192.168.26.22:9200/_cat/nodes?pretty 查看节点状态
192.168.26.22 38 93 6 0.83 2.63 1.63 mdi - es-node2
192.168.26.22 56 93 6 0.83 2.63 1.63 mdi * es-node1
192.168.26.22 35 93 6 0.83 2.63 1.63 mdi - es-node3
注:节点名称带表示为主节点*
4.2 使用elasticsearch-head前端框架
1.拉取镜像
docker pull mobz/elasticsearch-head:5
2.启动容器
docker run -d -p 9100:9100 --name es-manager mobz/elasticsearch-head:5
3.浏览器访问http://192.168.22.26:9100/
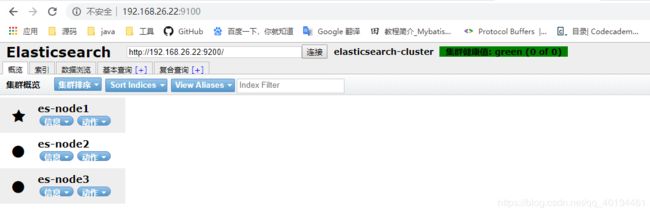
写在最后,这里要多提一点索引分片设置以及副本,官方推荐设置,读者根据自身需要进行修改:
curl -XPUT ‘http://localhost:9200/_all/_settings?preserve_existing=true’ -d ‘{
“index.number_of_replicas” : “1”,
“index.number_of_shards” : “10”
}’
附录:
- 查看容器内存
docker stats $(docker ps --format={{.Names}})
- 查看容器日志
docker logs 容器名/容器ID
- ElasticSearch配置文件说明
cluster.name: elasticsearch-cluster
node.name: es-node1
#index.number_of_shards: 2
#index.number_of_replicas: 1
network.bind_host: 0.0.0.0
network.publish_host: 192.168.26.22 两行代码灯影network.port:192.168.26.22 未验证
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["es-node1:9300","es-node2:9301","es-node3:9302"]
discovery.zen.minimum_master_nodes: 2
注:
- cluster.name:用于唯一标识一个集群,不同的集群,其 cluster.name 不同,集群名字相同的所有节点自动组成一个集群。如果不配置改属性,默认值是:elasticsearch。
- node.name:节点名,默认随机指定一个name列表中名字。集群中node名字不能重复
- index.number_of_shards: 默认的配置是把索引分为5个分片
- index.number_of_replicas:设置每个index的默认的冗余备份的分片数,默认是1
通过 index.number_of_shards,index.number_of_replicas默认设置索引将分为5个分片,每个分片1个副本,共10个结点。
禁用索引的分布式特性,使索引只创建在本地主机上:
index.number_of_shards: 1
index.number_of_replicas: 0
但随着版本的升级 将不在配置文件中配置而实启动ES后,再进行配置
- bootstrap.memory_lock: true 当JVM做分页切换(swapping)时,ElasticSearch执行的效率会降低,推荐把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的物理内存分配给ES,同时允许ElasticSearch进程锁住内存
- network.bind_host: 设置可以访问的ip,可以是ipv4或ipv6的,默认为0.0.0.0,这里全部设置通过
- network.publish_host:设置其它结点和该结点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址
同时设置bind_host和publish_host两个参数可以替换成network.host
network.bind_host: 192.168.9.219
network.publish_host: 192.168.9.219
=>network.host: 192.168.9.219
- http.port:设置对外服务的http端口,默认为9200
- transport.tcp.port: 设置节点之间交互的tcp端口,默认是9300
- http.cors.enabled: 是否允许跨域REST请求
- http.cors.allow-origin: 允许 REST 请求来自何处
- node.master: true 配置该结点有资格被选举为主结点(候选主结点),用于处理请求和管理集群。如果结点没有资格成为主结点,那么该结点永远不可能成为主结点;如果结点有资格成为主结点,只有在被其他候选主结点认可和被选举为主结点之后,才真正成为主结点。
- node.data: true 配置该结点是数据结点,用于保存数据,执行数据相关的操作(CRUD,Aggregation);
- discovery.zen.minimum_master_nodes: //自动发现master节点的最小数,如果这个集群中配置进来的master节点少于这个数目,es的日志会一直报master节点数目不足。(默认为1)为了避免脑裂,个数请遵从该公式 => (totalnumber of master-eligible nodes / 2 + 1)。 * 脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和Slave误以为出现两个active master,最终使得整个集群处于混乱状态*
- discovery.zen.ping.unicast.hosts: 集群个节点IP地址,也可以使用es-node等名称,需要各节点能够解析