PyTorch实现的MTCNN/LPRNet车牌识别
文章目录
- MTCNN
- MTCNN 基础知识
- MTCNN车牌检测
- MTCNN车牌检测网络结构
- LPRNet
- LPRNet特性
- STNet
- STNet网络结构
- LPRNet的基础构建模块
- 特征提取骨干网络架构
- LPRNet网络结构
- CCPD数据集
这是一个在MTCNN和LPRNet中使用PYTORCH的两阶段轻量级和健壮的车牌识别。
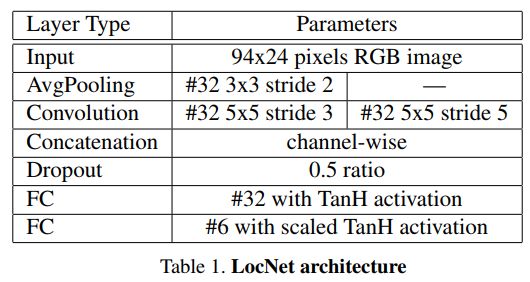
MTCNN是一个非常著名的实时检测模型,主要用于人脸识别。修改后用于车牌检测。LPRNet是另一种实时的端到端DNN,用于模糊识别.该网络以其优越的性能和较低的计算成本而不需要初步的字符分割。在这项工作中嵌入了Spatial Transformer Layer(空间变换层 LocNet),以便有更好的识别特性。
在Nivida Quadro P4000上使用该结构在CCPD数据集上能达到~ 80 ms/image的速度,识别准确率可达99%。下面是流程框架:

MTCNN
MTCNN 基础知识
MTCNN 一开始主要是拿来做人脸识别的(不知道现在还是不是,希望大佬可以分享最新的人脸识别网络)。MTCNN人脸检测是2016年的论文提出来的,MTCNN的“MT”是指多任务学习(Multi-Task),在同一个任务中同时学习”识别人脸“、”边框回归“、”人脸关键点识别“。

- 首先对test图片不断进行Resize,得到图片金字塔。按照resize_factor(如0.70,这个具体根据数据集人脸大小分布来确定,基本确定在0.70-0.80之间会比较合适,设的比较大,容易延长推理时间,小了容易漏掉一些中小型人脸)对test图片进行resize,直到大等于Pnet要求的12 * 12大小。这样子你会得到原图、原图 * resize_factor、原图* resize_factor2…、原图*resize_factorn(注,最后一个的图片大小会大等于12)这些不同大小的图片,堆叠起来的话像是金字塔,简单称为图片金字塔。注意,这些图像都是要一幅幅输入到Pnet中去得到候选的。

- 图片金字塔输入Pnet,得到大量的候选(candidate)。根据上述步骤1得到的图片金字塔,将所有图片输入到Pnet,得到输出map形状是(m, n, 16(2+4+10))。根据分类得分,筛选掉一大部分的候选,再根据得到的4个偏移量对bbox进行校准后得到bbox的左上右下的坐标,对这些候选根据IOU值再进行非极大值抑制(NMS)筛选掉一大部分候选。详细的说就是根据分类得分从大到小排,得到(num_left, 4)的张量,即num_left个bbox的左上、右下绝对坐标。每次以队列里最大分数值的bbox坐标和剩余坐标求出iou,干掉iou大于0.6(阈值是提前设置的)的框,并把这个最大分数值移到最终结果。重复这个操作,会干掉很多有大量overlap的bbox,最终得到(num_left_after_nms, 16)个候选,这些候选需要根据bbox坐标去原图截出图片后,resize为24 * 24输入到Rnet。

- 经过Pnet筛选出来的候选图片,经过Rnet进行精调。根据Pnet输出的坐标,去原图上截取出图片(截取图片有个细节是需要截取bbox最大边长的正方形,这是为了保障resize的时候不产生形变和保留更多的人脸框周围细节),resize为24 * 24,输入到Rnet,进行精调。Rnet仍旧会输出二分类one-hot2个输出、bbox的坐标偏移量4个输出、landmark10个输出,根据二分类得分干掉大部分不是人脸的候选、对截图的bbox进行偏移量调整后(说的简单点就是对左上右下的x、y坐标进行上下左右调整),再次重复Pnet所述的IOU NMS干掉大部分的候选。最终Pnet输出的也是(num_left_after_Rnet, 16),根据bbox的坐标再去原图截出图片输入到Onet,同样也是根据最大边长的正方形截取方法,避免形变和保留更多细节。

- 经过Rnet干掉很多候选后的图片输入到Onet,输出准确的bbox坐标和landmark坐标。大体可以重复Pnet的过程,不过有区别的是这个时候我们除了关注bbox的坐标外,也要输出landmark的坐标。(有小伙伴会问,前面不关注landmark的输出吗?嗯,作者认为关注的很有限,前面之所以也有landmark坐标的输出,主要是希望能够联合landmark坐标使得bbox更精确,换言之,推理阶段的Pnet、Rnet完全可以不用输出landmark,Onet输出即可。当然,训练阶段Pnet、Rnet还是要关注landmark的)经过分类筛选、框调整后的NMS筛选,好的,至此我们就得到准确的人脸bbox坐标和landmark点了,任务完满结束。
MTCNN车牌检测
这项工作只使用proposal net(Pnet)和output net(Onet),因为在这种情况下跳过Rnet不会损害准确性。Onet接受24(高度)x94(宽度)bGR图像,这与LPRNet的输入一致。
修改后的MTCNN结构如下:

MTCNN车牌检测网络结构
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
"""
Arguments:
x: a float tensor with shape [batch_size, c, h, w].
Returns:
a float tensor with shape [batch_size, c*h*w].
"""
# without this pretrained model isn't working
x = x.transpose(3, 2).contiguous()
return x.view(x.size(0), -1)
class PNet(nn.Module):
def __init__(self, is_train=False):
super(PNet, self).__init__()
self.is_train = is_train
self.features = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(3, 10, 3, 1)),
('prelu1', nn.PReLU(10)),
('pool1', nn.MaxPool2d((2,5), ceil_mode=True)),
('conv2', nn.Conv2d(10, 16, (3,5), 1)),
('prelu2', nn.PReLU(16)),
('conv3', nn.Conv2d(16, 32, (3,5), 1)),
('prelu3', nn.PReLU(32))
]))
self.conv4_1 = nn.Conv2d(32, 2, 1, 1)
self.conv4_2 = nn.Conv2d(32, 4, 1, 1)
def forward(self, x):
"""
Arguments:
x: a float tensor with shape [batch_size, 3, h, w].
Returns:
b: a float tensor with shape [batch_size, 4, h', w'].
a: a float tensor with shape [batch_size, 2, h', w'].
"""
x = self.features(x)
a = self.conv4_1(x)
b = self.conv4_2(x)
if self.is_train is False:
a = F.softmax(a, dim=1)
return b, a
class ONet(nn.Module):
def __init__(self, is_train=False):
super(ONet, self).__init__()
self.is_train = is_train
self.features = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(3, 32, 3, 1)),
('prelu1', nn.PReLU(32)),
('pool1', nn.MaxPool2d(3, 2, ceil_mode=True)),
('conv2', nn.Conv2d(32, 64, 3, 1)),
('prelu2', nn.PReLU(64)),
('pool2', nn.MaxPool2d(3, 2, ceil_mode=True)),
('conv3', nn.Conv2d(64, 64, 3, 1)),
('prelu3', nn.PReLU(64)),
('pool3', nn.MaxPool2d(2, 2, ceil_mode=True)),
('conv4', nn.Conv2d(64, 128, 1, 1)),
('prelu4', nn.PReLU(128)),
('flatten', Flatten()),
('conv5', nn.Linear(1280, 256)),
('drop5', nn.Dropout(0.25)),
('prelu5', nn.PReLU(256)),
]))
self.conv6_1 = nn.Linear(256, 2)
self.conv6_2 = nn.Linear(256, 4)
def forward(self, x):
"""
Arguments:
x: a float tensor with shape [batch_size, 3, h, w].
Returns:
c: a float tensor with shape [batch_size, 10].
b: a float tensor with shape [batch_size, 4].
a: a float tensor with shape [batch_size, 2].
"""
x = self.features(x)
a = self.conv6_1(x)
b = self.conv6_2(x)
if self.is_train is False:
a = F.softmax(a, dim=1)
return b, a
LPRNet
LPRNet全程就叫做License Plate Recognition via Deep Neural Networks(基于深层神经网络的车牌识别)。LPRNet由轻量级的卷积神经网络组成,所以它可以采用端到端的方法来进行训练。据我们所知,LPRNet是第一个没有采用RNNs的实时车牌识别系统。因此,LPRNet算法可以为LPR创建嵌入式部署的解决方案,即便是在具有较高挑战性的中文车牌识别上。
LPRNet特性
- 实时、高精度、支持车牌字符变长、无需字符分割、对不同国家支持从零开始end-to-end的训练;
- 第一个不需要使用RNN的足够轻量级的网络,可以运行在各种平台,包括嵌入式设备;
- 鲁棒,LPRNet已经应用于真实的交通监控场景,事实证明它可以鲁棒地应对各种困难情况,包括透视变换、镜头畸变带来的成像失真、强光、视点变换等。
STNet
Spatial Transformer Networks提出的空间网络变换层,具有平移不变性、旋转不变性及缩放不变性等强大的性能。这个网络可以加在现有的卷积网络中,提高分类的准确性。
空间变换网络主要有如下三个作用:
- 可以将输入转换为下一层期望的形式
- 可以在训练的过程中自动选择感兴趣的区域特征
- 可以实现对各种形变的数据进行空间变换

ST的结构如上图所示,每一个ST模块由Localisation net, Grid generator和Sample组成。
- Localisation net决定输入所需变换的参数θ,
- Grid generator通过θ和定义的变换方式寻找输出与输入特征的映射T(θ),
- Sample结合位置映射和变换参数对输入特征进行选择并结合双线性插值进行输出。
首先,输入图像由空间变换层(Spatial Transformer Layer)预处理 STNet 这是对检测到的车牌形状上的校正,使用 Spatial Transformer Layer(这一步是可选的),但用上可以使得图像更好得被识别。
下面是他的效果图,看起来是不是很舒服。

STNet网络结构
import torch.nn as nn
import torch
import torch.nn.functional as F
class STNet(nn.Module):
def __init__(self):
super(STNet, self).__init__()
# Spatial transformer localization-network
self.localization = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(32, 32, kernel_size=5),
nn.MaxPool2d(3, stride=3),
nn.ReLU(True)
)
# Regressor for the 3x2 affine matrix
self.fc_loc = nn.Sequential(
nn.Linear(32 * 14 * 2, 32),
nn.ReLU(True),
nn.Linear(32, 3*2)
)
# Initialize the weights/bias with identity transformation
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1,0,0,0,1,0], dtype=torch.float))
def forward(self, x):
xs = self.localization(x)
xs = xs.view(-1, 32*14*2)
theta = self.fc_loc(xs)
theta = theta.view(-1,2,3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
LPRNet的基础构建模块
LPRNet的基础网络构建模块受启发于SqueezeNet Fire Blocks和Inception Blocks,如下图所示。
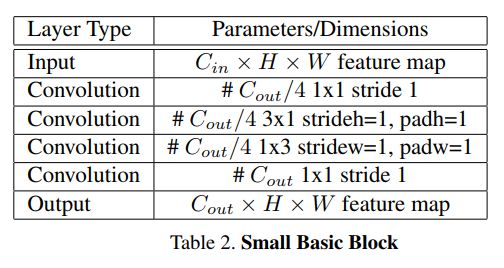
特征提取骨干网络架构
骨干网将原始的RGB图像作为输入,计算得到空间分布的丰富特征。为了利用局部字符的上下文信息,该文使用了宽卷积(1×13 kernel)而没有使用LSTM-based RNN。骨干网络最终的输出,可以被认为是一系列字符的概率,其长度对应于输入图像像素宽度。
由于解码器的输出与目标字符序列长度不同,训练的时候使用了CTC Loss,它可以很好的应对不需要字符分割和对齐的end-to-end训练。
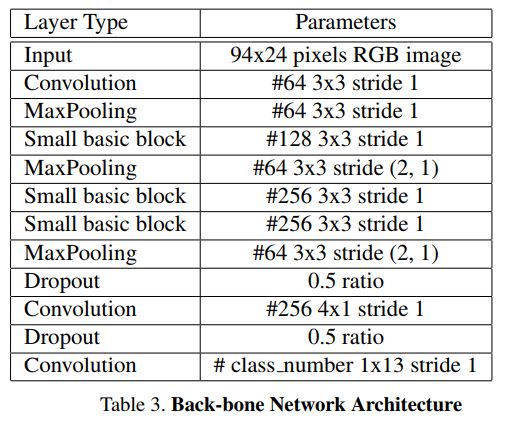
为了进一步地提升模型的表现,增强解码器所得的中间特征图,采用用全局上下文关系(global context)进行嵌入。它是通过全连接层对骨干网络的输出层进行计算,随后将其平铺到所需的大小,最后再与骨干网络的输出进行拼接 , 加入GAP思想源于Parsenet。下图为加入GAP拼接到feature map上进行识别的表示。

LPRNet网络结构
import torch.nn as nn
import torch
class small_basic_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(small_basic_block, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),
)
def forward(self, x):
return self.block(x)
class LPRNet(nn.Module):
def __init__(self, class_num, dropout_rate):
super(LPRNet, self).__init__()
self.class_num = class_num
self.backbone = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1), # 0
nn.BatchNorm2d(num_features=64),
nn.ReLU(), # 2
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1)),
small_basic_block(ch_in=64, ch_out=128), # *** 4 ***
nn.BatchNorm2d(num_features=128),
nn.ReLU(), # 6
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(2, 1, 2)),
small_basic_block(ch_in=64, ch_out=256), # 8
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 10
small_basic_block(ch_in=256, ch_out=256), # *** 11 ***
nn.BatchNorm2d(num_features=256), # 12
nn.ReLU(),
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2)), # 14
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(1, 4), stride=1), # 16
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 18
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=256, out_channels=class_num, kernel_size=(13, 1), stride=1), # 20
nn.BatchNorm2d(num_features=class_num),
nn.ReLU(), # *** 22 ***
)
self.container = nn.Sequential(
nn.Conv2d(in_channels=256+class_num+128+64, out_channels=self.class_num, kernel_size=(1,1), stride=(1,1)),
# nn.BatchNorm2d(num_features=self.class_num),
# nn.ReLU(),
# nn.Conv2d(in_channels=self.class_num, out_channels=self.lpr_max_len+1, kernel_size=3, stride=2),
# nn.ReLU(),
)
def forward(self, x):
keep_features = list()
for i, layer in enumerate(self.backbone.children()):
x = layer(x)
if i in [2, 6, 13, 22]: # [2, 4, 8, 11, 22]
keep_features.append(x)
global_context = list()
for i, f in enumerate(keep_features):
if i in [0, 1]:
f = nn.AvgPool2d(kernel_size=5, stride=5)(f)
if i in [2]:
f = nn.AvgPool2d(kernel_size=(4, 10), stride=(4, 2))(f)
f_pow = torch.pow(f, 2)
f_mean = torch.mean(f_pow)
f = torch.div(f, f_mean)
global_context.append(f)
x = torch.cat(global_context, 1)
x = self.container(x)
logits = torch.mean(x, dim=2)
return logits
CCPD数据集
CCPD(中国城市停车数据集,ECCV)和PDRC(车牌检测与识别挑战)。这是一个用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
https://github.com/detectRecog/CCPD
该数据集在合肥市的停车场采集得来的,采集时间早上7:30到晚上10:00.涉及多种复杂环境。一共包含超多25万张图片,每种图片大小720x1160x3。一共包含9项。每项占比如下:
| CCPD- | 数量/k | 描述 |
|---|---|---|
| Base | 200 | 正常车牌 |
| FN | 20 | 距离摄像头相当的远或者相当近 |
| DB | 20 | 光线暗或者比较亮 |
| Rotate | 10 | 水平倾斜20-25°,垂直倾斜-10-10° |
| Tilt | 10 | 水平倾斜15-45°,垂直倾斜15-45° |
| Weather | 10 | 在雨天,雪天,或者雾天 |
| Blur(已删除) | 5 | 由于相机抖动造成的模糊(这个后面被删了) |
| Challenge | 10 | 其他的比较有挑战性的车牌 |
| NP | 5 | 没有车牌的新车 |
数据标注:
文件名就是数据标注。eg:
025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
由分隔符-分为几个部分:
-
025为车牌占全图面积比, -
95_113对应两个角度, 水平倾斜度和垂直倾斜度,水平95°, 竖直113° -
154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473) -
386&473_177&454_154&383_363&402对应四个角点右下、左下、左上、右上坐标 -
0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y…
provinces = [“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”, “警”, “学”, “O”]
alphabets = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘O’]
ads = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘O’]
-
37亮度 -
15模糊度
所以根据文件名即可获得所有标注信息。