使用多任务级联卷积网络进行人脸检测和对齐(MTCNN翻译)
使用多任务级联卷积网络进行人脸检测和对齐
摘要
在无约束的环境下,由于各种各样的姿势、光线强度以及面部遮挡等原因,人脸检测和对齐是一个巨大的挑战。最近的研究表明,深度学习的方法在这两个任务上的表现令人印象深刻。在本文中,我们提出了一个深入的级联多任务框架,通过它们之间内在的相互关系去提高它们的性能。值得一提的是,我们的框架采用级联结构伴随着精心设计的深度卷积网络的三个阶段,以粗到细的方式去预测人脸和特征点的位置。除此之外,在学习的过程中,我们提出了一种新的在线硬样本挖掘方法,能够在没有手动选择样本的情况下自动提升性能。在FDDB和WIDER FACE为基准的人脸识别挑战和以ALFW为基准的人脸对齐挑战中,我们的方法在保持实时性能的同时,达到了极高的精确度并且超过了现在最新的技术。
关键字:人脸检测 人脸对齐 级联卷积神经网络
一、绪论
人脸检测和对齐是很多人脸应用的基础,如人脸识别和表情分析。然而,人脸在遮挡、姿态变换以及极端光照的巨大变化下,给这些任务在实际应用中带来了巨大的挑战。
Viola和Jones[2]提出的级联人脸检测算法利用类haar特征和adaboost来训练级联分类器,取得了良好的性能和实时性。然而,相当多的工作[1, 3, 4]表明该检测器在实际应用中的性能会显著降级,即使在具有更高级特征和分类器的情况下,人脸的视觉变化也会变得更大。在级联结构的基础上,[5, 6, 7]引入了用于人脸检测的可变模型(DPM),取得了显著的性能。然而,它们需要很高的计算开销,并且在训练阶段通常需要繁琐的标注。近年来,卷积神经网络(CNN)在各种计算机视觉任务中取得了显著进步,例如图像分类[9]和人脸识别[10]。由于受到CNN在计算机视觉任务中取得良好表现的启发,所以近年来提出了一些基于CNN面部检测的方法。Yang et al. [11]训练了用于面部属性识别的深度卷积神经网络,以便于在面部区域获得高区分度,从而进一步产生面部的候选窗口。但是由于其复杂的CNN结构,这种方法在实践中非常耗时。Li et al. [19]使用级联的CNN进行人脸检测,但是它需要在人脸检测中进行边界框校准,伴随着额外的计算开销,并且忽略了人脸标志定位和边界框回归之间的内在关联。
人脸对齐也同样引起了广泛的关注,基于回归的方法[12,13,16]和模板拟合的方法[14,15,7]是两个流行的类别。最近, Zhang et al. [22]提出了在使用面部属性识别作为辅助任务的基础上利用深度卷积神经网络提高面部对齐的性能。
然而,大多数可用的面部检测和面部对齐的方法都忽略了这两个任务之间的固有关联。尽管已经存在了几种尝试共同解决它们的作品,但是这些作品然而存在局限性。例如,Chen et al. [18] 使用像素值差的特征与随机森林联合进行对准和检测,但是其使用的手动特征限制了这个方法的性能。Zhang et al. [20]使用多任务CNN来提高多视图中人脸检测的准确性,但是其检测精度收到弱人脸检测器产生的初始检测窗口的限制。
另一方面,在训练过程中,挖掘硬样本对于增强检测器的能力至关重要。但是,传统的硬样本挖掘通常以离线的方式执行,这大大增加了手动操作。所以期望能够设计出一种用于面部检测和对准的在线硬样本挖掘策略,该策略能够自动适用于当前的训练过程。
在本文中,我们提出了一个新框架,通过多任务学习使用统一级联的CNN去集成这两个任务。这个CNN框架包含三个阶段。在第一阶段,它会通过浅层的CNN快速生成候选窗口。然后,它将通过更复杂的CNN来优化窗口以拒绝大量非面部窗口。最后,手那个用功能更强大的CNN细化结果并输出面部标志位置。
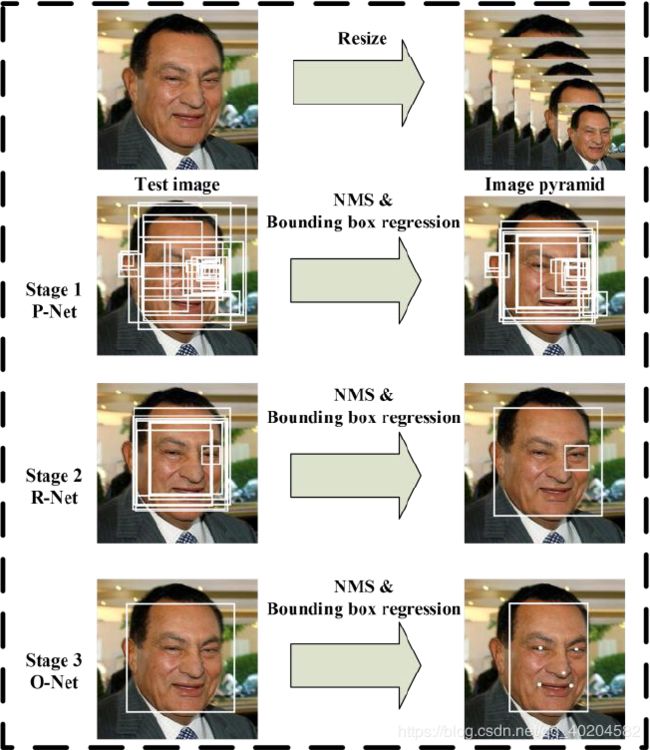 Fig. 1
Fig. 1
Fig. 1.我们级联框架的管道包含三个阶段任务的深度卷积网络。首先,通过快速的提案网络(P-Net)产生候选窗口。之后,在下一阶段通过优化网络(R-Net)优化这些候选对象。在第三阶段,输出网络(O-Net)产生最终的边界框和面部标志位。
多亏了这种多任务学习框架,该算法的性能得以显著提升。本文的主要贡献概括如下:
(1)我们提出了一个新的基于级联CNN的联合人脸检测和对齐的框架,并精心设计了轻量级CNN框架以实现实时性能。
(2)我们提出了一种有效的在线硬样本挖掘方法以提高其性能。
(3)在具有挑战性的基准上进行了广泛的实验,以证明该方法的显著能行,并且能够改进与最先技术相比的面部检测和对齐任务。
二、方法
在本节中,我们将描述我们人脸检测和对齐的联合方法。
A. Overall Framework
我们的方法整体流程如Fig. 1所示。给定图像,我们首先将其调整为不同的比例以构建图片金字塔,以下内容是三个输入阶段的级联框架:
Stage 1:我们利用被称之为全卷积网络的提案网络(P-Net),以[29]类似的方式去获取候选窗口和它们的边界框回归向量。然后我们使用估计的边界框回归向量来校准候选人。接着,我们利用非最大抑制(NMS)来合并高度重叠的候选人。
Stage 2:所有候选人都送入另一个名为“优化”的CNN网络(R-Net),进一步拒绝大量错误候选者,使用边界框回归进行校准,再与NMS候选者合并。
Stage 3:这个阶段类似于第二阶段,但是在这个阶段,我们旨在更详细的描述面孔。尤其是,网络将输出五个面部标志的位置。
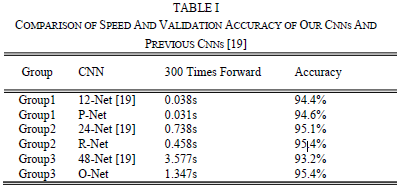
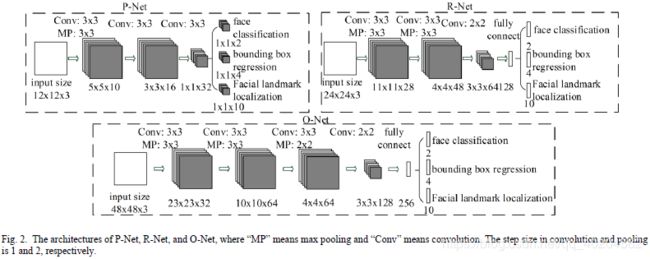
B. CNN Architectures
在[19]中,已经为面部检测设计了多个CNN。然而,我们注意到其性能可能受到以下事实限制:
(1)一些过滤器缺乏权重的多样性可能会限制它们产生区分性描述。
(2)与其它多类别的目标检测和分类任务相比,人脸检测是一个具有挑战性的二进制分类任务,因此它可能需要用较少的过滤器数量去获取在它们之中更多的区分度。为此,我们减少了过滤器的数量,将5x5过滤器更改为3x3过滤器以较少计算量,同时增加深度以获得更好的性能。 用这些改善与[19]中之前的架构相比,我们可以用更少的运行时间获得更好的性能(结果如Table 1所示。为了公平比较,我们将相同的数据用于两种方法)。我们的CNN架构如Fig. 2所示。
C. Training
我们利用三项任务来训练CNN检测器:人脸/非人脸分类,边界框回归和面部标志本地化。
(1)人脸分类:将学习目标表述为二分类问题。对于每个样本
 ,我们使用交叉熵损失:
,我们使用交叉熵损失:
![]()
其中 表示网络产生的概率,表明一个样本就是一张脸。符号
表示网络产生的概率,表明一个样本就是一张脸。符号![]() 表示真实标签。
表示真实标签。
(2)边界框回归:对每个候选窗口,我们预测它与最接近真实情况之间的偏移量(即,边界框的左上角,高度和宽度)。学习目标被称之为回归问题,我们采用每个样本的欧几里得损失:
![]()
其中![]() 是从网络中获得的回归目标,
是从网络中获得的回归目标,![]() 是真实坐标。这里有四个坐标,包含左上角,高度和宽度,因此
是真实坐标。这里有四个坐标,包含左上角,高度和宽度,因此![]() 。
。
(3)面部标志定位:类似于边界框回归任务,将面部标志检测公式化为回归问题,我们将欧几里得损失降至最低:
![]()
其中![]() 是从网络中获得的面部标志坐标,
是从网络中获得的面部标志坐标,![]() 是真实坐标。这里有五个面部标志,包括左眼,右眼,鼻子,左嘴角和右嘴角,因此
是真实坐标。这里有五个面部标志,包括左眼,右眼,鼻子,左嘴角和右嘴角,因此![]() 。
。
(4)多来源训练:由于我们在每个CNN中采用不同的任务,因此在学习过程中有不同类型的训练图像,例如面部,非面部和部分对齐的面部。在这种情况下,一些损失函数(i.e., Eq. (1)-(3))将不被使用。例如说,对于背景区域的样本,我们只计算![]() ,将其它两个损失值设为0。这可以直接通过样本类型指示器来实现。然后总体学习目标可以表述为:
,将其它两个损失值设为0。这可以直接通过样本类型指示器来实现。然后总体学习目标可以表述为:
![]()
其中N是训练样本数量。![]() 表示任务的重要性。我们在P-Net和R-Net中使用
表示任务的重要性。我们在P-Net和R-Net中使用![]() ,在O-Net中使用
,在O-Net中使用![]() 来获得更准确的面部标志定位。
来获得更准确的面部标志定位。![]() 是样本类型指示器。在这种情况下,采用自然的随机梯度下降来训练CNN。
是样本类型指示器。在这种情况下,采用自然的随机梯度下降来训练CNN。
(5)在线硬样本挖掘:不同于先进行传统硬样本挖掘,后训练原始分类器的方法,我们在人脸分类任务中进行在线硬样本挖掘以适应训练过程。
尤其是,在每个小批量中,我们对所有样本在前向传播阶段计算出的损耗进行排序,并选择其中的前70%作为硬样本。然后,我们仅在后向传播阶段从硬样本中计算梯度。这意味着我们忽略了简单的样本,这些样本在训练时对增强检测器的帮助较小。实验表明,这种策略无需手动选择样本即可获得更好的性能。第三节中证明了其有效性。
三、实验
在本节中,我们首先评估提出的硬样本挖掘策略的有效性。然后,我们将人脸检测和对齐与人脸检测数据集中最先进的方法进行对比,包含FDDB[25],WIDER FACE[24]和带标记的野外环境AFLW[8]。FDDB数据集包含2,845张图像,5,171张人脸。WIDER FACE数据集由32,203张图像中的393,703个带标签的面部边界框组成,其中50%根据图像的难度分为三个子集进行测试,40%用于训练,其余用于验证。AFLW包含24,386张面部的标签注释,并且我们使用与[22]相同的测试子集。最后,我们评估人脸检测器的计算效率。
A. Training Data
由于我们同时使用人脸检测和对齐,因此我们在训练过程中使用四种不同类型的数据注释:
(i)负样本:与真实人脸联合相交(IoU)小于0.3的区域。
(ii)正样本:与真实人脸相交高于0.65.
(iii)局部样本:与真实人脸相交,IoU在0.4和0.65之间。
(iv)标签样本:人脸5个标志的标签位置。
负样本和正样本用于人脸分类任务,正样本和局部样本用于边界框回归,标签样本用于人脸标志的定位。每个网络的训练数据描述如下:
(1)P-Net:我们对WIDER FACE[24]进行了随机裁切,以收集正样本,负样本和局部样本。然后,我们将CelebA[23]中的人脸裁剪为标签样本。
(2)R-Net:在从CelebA[23]中检测标签人脸的时候,我们使用框架中的第一阶段从WIDER FACE[24]检测人脸,以收集正样本,负样本和局部样本。
(3)O-Net:类似于R-Net收集数据,但我们使用框架的前两个阶段来检测人脸。
B. The effectiveness of online hard sample mining
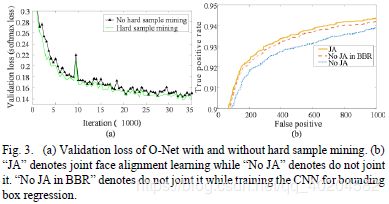
为了评估提出的在线硬样本挖掘策略的贡献,我们训练了两个O-Net(有和没有在线硬样本挖掘)并比较了它们的损失曲线。为了更直接地进行比较,我们仅训练O-Net进行人脸分类任务。在这两个O-Net中,包括网络初始化在内的所有训练参数都相同。为了更轻松地比较它们,我们使用固定学习率。Fig. 3 (a)显示了两种不同训练方式的损耗曲线。很明显,硬样本挖掘有利于提高性能。
C. The effectiveness of joint detection and alignment
为了评估联合检测和对齐的贡献,我们评估了FDDB(具有相同的P-Net和R-Net,以进行公平比较)上两个不同的O-Net(联合面部标识回归任务和不联合)的性能。我们还比较了这两个O-Net中边界框回归的性能。Fig. 3 (b) 表明联合面部标识任务学习对于人脸分类和边界框回归任务都是有益的。
D. Evaluation on face detection
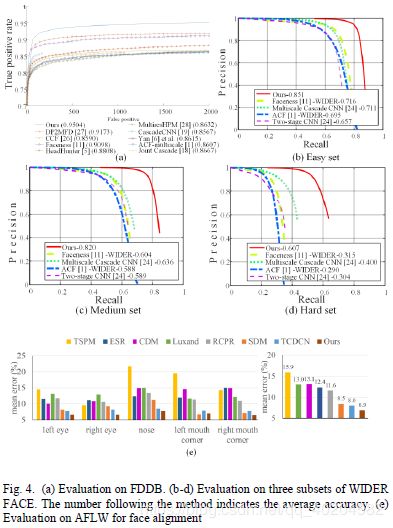
为了评估我们的人脸检测方法的性能,我们将我们的方法与FDDB中 [1,5, 6, 11, 18, 19, 26, 27, 28, 29]和WIDER FACE中[1, 24, 11]最先进的方法进行了比较。Fig. 4(a)-(d)表明,我们的方法在两个基准测试中均以较大的优势胜过先前所有的方法。我们还评估了一些具有挑战性照片的方法。
E. Evaluation on face alignment
在这一部分中,我们将我们的方法与以下方法的人脸对齐性能进行了比较:RCPR [12], TSPM[7], Luxand face SDK [17], ESR [13], CDM [15], SDM [21], TCDCN [22]。在测试阶段,我们的方法无法检测到13张图像。 因此,我们裁剪了这13张图像的中心区域,并将它们作为O-Net的输入。通过估计的标志位和真实标志位之间的距离测量平均误差,并相对于眼间距离进行归一化。 Fig. 4 (e)表明我们的方法在性能上优于所有最新方法。
F. Runtime efficiency
给定级联结构,我们的方法可以在联合人脸检测和对齐中实现非常快的速度。在2.60GHz CPU上达到16fps,在GPU (Nvidia Titan Black)上达到99fps。目前,我们的实现基于未优化的MATLAB代码。
四、结论
在本文中,我们提出了一种基于多任务级联CNN的框架,用于联合人脸检测和对齐。实验结果表明,在保持实时性能的同时,我们的方法在多个具有挑战性的基准(包括用于人脸检测的FDDB和WIDER FACE,以及用于人脸对齐的AFLW)上始终优于最新方法。 将来,我们将利用人脸检测与其它人脸分析任务之间的固有关联性,进一步提高性能。
参考资料
[1] B. Yang, J. Yan, Z. Lei, and S. Z. Li, “Aggregate channel eatures for multi-view face detection,” in IEEE International Joint Conference on Biometrics, 2014, pp. 1-8.
[2] P. Viola and M. J. Jones, “Robust real-time face detection. International journal of computer vision,” vol. 57, no. 2, pp. 137-154, 2004
[3] M. T. Pham, Y. Gao, V. D. D. Hoang, and T. J. Cham, “Fast polygonal integration and its application in extending haar-like features to improve object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 942-949.
[4] Q. Zhu, M. C. Yeh, K. T. Cheng, and S. Avidan, “Fast human detection using a cascade of histograms of oriented gradients,” in IEEE Computer Conference on Computer Vision and Pattern Recognition, 2006, pp. 1491-1498.
[5] M. Mathias, R. Benenson, M. Pedersoli, and L. Van Gool, “Face detection without bells and whistles,” in European Conference on Computer Vision, 2014, pp. 720-735.
[6] J. Yan, Z. Lei, L. Wen, and S. Li, “The fastest deformable part model for object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2497-2504.
[7] X. Zhu, and D. Ramanan, “Face detection, pose estimation, and landmark localization in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 2879-2886.
[8] M. Köstinger, P. Wohlhart, P. M. Roth, and H. Bischof, “Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2011, pp. 2144-2151.
[9] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097-1105.
[10] Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Advances in Neural Information Processing Systems, 2014, pp. 1988-1996.
[11] S. Yang, P. Luo, C. C. Loy, and X. Tang, “From facial parts responses to face detection: A deep learning approach,” in IEEE International Conference on Computer Vision, 2015, pp. 3676-3684.
[12] X. P. Burgos-Artizzu, P. Perona, and P. Dollar, “Robust face landmark estimation under occlusion,” in IEEE International Conference on Computer Vision, 2013, pp. 1513-1520.
[13] X. Cao, Y. Wei, F. Wen, and J. Sun, “Face alignment by explicit shape regression,” International Journal of Computer Vision, vol 107, no. 2, pp. 177-190, 2012.
[14] T. F. Cootes, G. J. Edwards, and C. J. Taylor, “Active appearance models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 6, pp. 681-685, 2001.
[15] X. Yu, J. Huang, S. Zhang, W. Yan, and D. Metaxas, “Pose-free facial landmark fitting via optimized part mixtures and cascaded deformable shape model,” in IEEE International Conference on Computer Vision, 2013, pp. 1944-1951.
[16] J. Zhang, S. Shan, M. Kan, and X. Chen, “Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment,” in European Conference on Computer Vision, 2014, pp. 1-16.
[17] Luxand Incorporated: Luxand face SDK, http://www.luxand.com/
[18] D. Chen, S. Ren, Y. Wei, X. Cao, and J. Sun, “Joint cascade face detection and alignment,” in European Conference on Computer Vision, 2014, pp. 109-122.
[19] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural network cascade for face detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 5325-5334.
[20] C. Zhang, and Z. Zhang, “Improving multiview face detection with multi-task deep convolutional neural networks,” IEEE Winter Conference on Applications of Computer Vision, 2014, pp. 1036-1041.
[21] X. Xiong, and F. Torre, “Supervised descent method and its applications to face alignment,” in IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 532-539.
[22] Z. Zhang, P. Luo, C. C. Loy, and X. Tang, “Facial landmark detection by deep multi-task learning,” in European Conference on Computer Vision, 2014, pp. 94-108.
[23] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in IEEE International Conference on Computer Vision, 2015, pp. 3730-3738.
[24] S. Yang, P. Luo, C. C. Loy, and X. Tang, “WIDER FACE: A Face Detection Benchmark”. arXiv preprint arXiv:1511.06523
[25] V. Jain, and E. G. Learned-Miller, “FDDB: A benchmark for face detection in unconstrained settings,” Technical Report UMCS-2010-009, University of Massachusetts, Amherst, 2010.
[26] B. Yang, J. Yan, Z. Lei, and S. Z. Li, “Convolutional channel features,” in IEEE International Conference on Computer Vision, 2015, pp. 82-90.
[27] R. Ranjan, V. M. Patel, and R. Chellappa, “A deep pyramid deformable part model for face detection,” in IEEE International Conference on Biometrics Theory, Applications and Systems, 2015, pp. 1-8.
[28] G. Ghiasi, and C. C. Fowlkes, “Occlusion Coherence: Detecting and Localizing Occluded Faces,” arXiv preprint arXiv:1506.08347.
[29] S. S. Farfade, M. J. Saberian, and L. J. Li, “Multi-view face detection using deep convolutional neural networks,” in ACM on International Conference on Multimedia Retrieval, 2015, pp. 643-650.