爬虫爬取京东商品详细数据 (品牌、售价、各类评论量(精确数量)、热评词及数量等)json解析部分数据
文章目录
- 前言
- 一、数据保存格式设置及数据库准备(CentOS云mysql数据库)
- 1、分析数据需求(单一商品为例)
- 2、数据库保存格式
- 3、用到的数据库操作及指令
- 二、网页分析
- 1、分析网页源码,确定提取方式
- 三、代码设计及信息爬取
- 完整代码:
- 四、优化与改进
- **改进需求:**
- 改进版(已完成)链接(时间由21000s优化至3000s左右)
前言
1.本编文章为毕设所著,所作内容不用于任何商业用途,爬虫所获取内容均用于个人设计
2.本文基于上一篇文章为前提,详情转:爬取京东笔记本电脑销量榜每件商品详情页url,并存入云服务器中的mysql库
3.目前多线程改进版已完成,请移步至:
(多线程优化版)爬虫爬取京东商品详细数据(品牌、售价、各类评论量(精确数量)、热评词及数量等) json解析部分数据
一、数据保存格式设置及数据库准备(CentOS云mysql数据库)
1、分析数据需求(单一商品为例)
此为所获取到的上商品url中的第一件商品的详情页

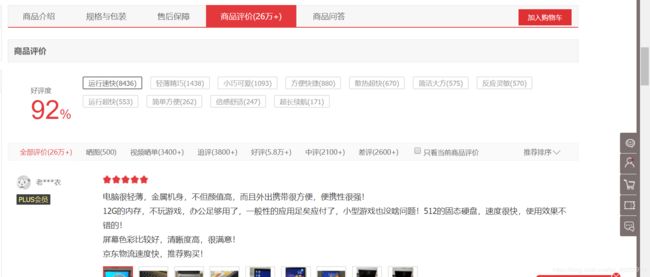
通过观察网页,初步确定数据需求为:
商品名称(product_name)、品牌(product_brand)、价格(product_price)、总评论数(total_comment_num)、好评数(good_comment_num)、好评率(good_percent_com)、差评数(bad_comment_num)、差评率(bad_percent_com)、评论标签及数量(dict_icon),共计9项。(后续网页分析后添加项:价格分为三项(最高价格(product_m_price)、当前价格(product_price)、指导价格(product_o_price))),合计11项。
2、数据库保存格式
继爬取到的数据继续存入上一文章保存url库中,增加字段,更新行数据。
结果示例:
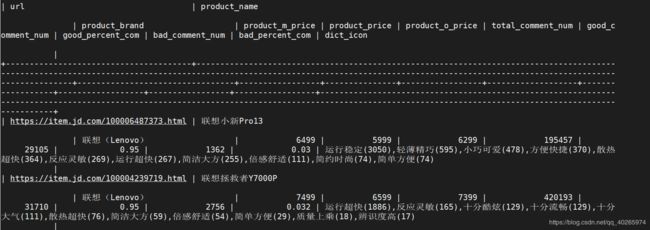
3、用到的数据库操作及指令
1、说明:创建数据库
CREATE DATABASE database-name
2、说明:删除数据库
drop database dbname
3、说明:备份sql server
--- 创建 备份数据的 device
USE master
EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'
--- 开始 备份
BACKUP DATABASE pubs TO testBack
4、说明:创建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)
根据已有的表创建新表:
A:create table tab_new like tab_old (使用旧表创建新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、说明:删除新表
drop table tabname
6、说明:增加一个列
Alter table tabname add column col type
注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键: Alter table tabname add primary key(col)
说明:删除主键: Alter table tabname drop primary key(col)
8、说明:创建索引:create [unique] index idxname on tabname(col….)
删除索引:drop index idxname
注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement
删除视图:drop view viewname
10、说明:几个简单的基本的sql语句
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
二、网页分析
1、分析网页源码,确定提取方式
1>.商品名称(product_name)、品牌(product_brand)
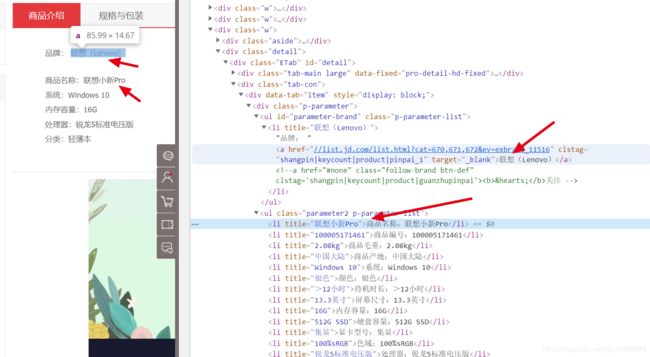
解析方式:xpth:
[product_name] = detail.xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]/li[1]/@title') # 商品名称
print("商品:" + str(product_name))
[product_brand] = detail.xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[1]/li[1]/a/text()') # 商品品牌
print("品牌:" + str(product_brand))
2>.其他数据
这些数据保存存在反爬措施,其数据保存在json中,提取方法:(请求json)
京东反爬措施导致无法爬取商品价格和评论等信息解决方法
最高价格(product_m_price)、当前价格(product_price)、指导价格(product_o_price):
p = requests.get('https:' + '//p.3.cn/prices/mgets?skuIds=J_' + product_id, headers=header, proxies=random.choice(proxy_list)) # 请求商品价格jso
[product_dict] = json.loads(p.text) # 获取商品价格
product_m_price = product_dict['m']
product_price = product_dict['p']
product_o_price = product_dict['op']
总评论数(total_comment_num)、好评数(good_comment_num)、好评率(good_percent_com)、差评数(bad_comment_num)、差评率(bad_percent_com):
c = requests.get('https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + product_id, headers=header, proxies=random.choice(proxy_list)) # 请求评论json
comment_dict = json.loads(c.text.split('[')[-1].split(']')[0]) # json内容截取
total_comment_num = comment_dict['CommentCount']
good_comment_num = comment_dict['ShowCount']
good_percent_com = comment_dict['GoodRate']
bad_comment_num = comment_dict['PoorCount']
bad_percent_com = comment_dict['PoorRate']
print("总评论数为:{}" .format(total_comment_num))
print("好评数: {}" .format(good_comment_num))
print("好评率: {}" .format(good_percent_com))
print("差评数: {}".format(bad_comment_num))
print("差评率: {}".format(bad_percent_com))
评论标签及数量(dict_icon):
icon = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=' + product_id + '&score=0&sortType=5&page=0&pageSize=10', headers=header, proxies=random.choice(proxy_list))
comment_ic = json.loads(icon.text.split('hotCommentTagStatistics":')[-1].split(',"jwotestProduct')[0])
icon = []
for ic in comment_ic:
comment_ic_name = ic['name']
comment_ic_num = ic['count']
comment_icon = comment_ic_name + '(' + str(comment_ic_num) + ')'
icon.append(comment_icon)
comment_icon_all = ','.join(icon)
print(comment_icon_all)
三、代码设计及信息爬取
完整代码:
备注:
1.需要预先获取url支持,详情参见本文前言。
2.数据库地址和密码以***代替,直接复制代码无法运行
import requests
from lxml import etree
import json
import random
import pymysql
import time
# 请求头池
user_agent = [
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
]
# Ip池
proxy_list = [
{"http" or "https": "112.115.57.20:3128"},
{"http" or "https": '121.41.171.223:3128'},
]
def get_url(): # 从数据库获取商品url
try:
db = pymysql.connect(host="***", user="root", password="***", database="JD_DATA", charset="utf8")
d = db.cursor()
sql = 'SELECT url FROM product_data'
d.execute(sql)
rows = d.fetchall()
urls = []
for row in rows:
for con in row:
urls.append(con)
return urls
d.close()
db.close()
except BaseException as e:
print("获取数据库数据失败!:{}".format(e))
def insert(value, table, p_url): # 写入数据到数据库函数
# 连接数据库
db = pymysql.connect(host="***", user="root", password="***", database="JD_DATA",
charset="utf8")
cursor = db.cursor()
# 更新数据,判断写入位置
sql = "UPDATE product_data SET {table} = '{val}' WHERE url = '{purl}'".format(table=table, val=value, purl=p_url)
try:
cursor.execute(sql)
db.commit()
except Exception as e:
db.rollback()
print("插入数据失败! error:{}".format(e))
db.close()
def get_data(url): # 获取商品详细数据
header = {'User-Agent': random.choice(user_agent)}
r = requests.get(url, headers=header, proxies=random.choice(proxy_list))
detail = etree.HTML(r.text) # str转HTML
[product_name] = detail.xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]/li[1]/@title') # 商品名称
# print("商品:" + str(product_name))
[product_brand] = detail.xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[1]/li[1]/a/text()') # 商品品牌
# print("品牌:" + str(product_brand))
# 请求价格信息json
p = requests.get('https:' + '//p.3.cn/prices/mgets?skuIds=J_' + product_id, headers=header, proxies=random.choice(proxy_list)) # 请求商品价格json
[product_dict] = json.loads(p.text) # 获取商品价格
product_m_price = product_dict['m']
product_price = product_dict['p']
product_o_price = product_dict['op']
# 请求评论信息json
c = requests.get('https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + product_id, headers=header, proxies=random.choice(proxy_list)) # 请求评论json
comment_dict = json.loads(c.text.split('[')[-1].split(']')[0]) # json内容截取
total_comment_num = comment_dict['CommentCount']
good_comment_num = comment_dict['ShowCount']
good_percent_com = comment_dict['GoodRate']
bad_comment_num = comment_dict['PoorCount']
bad_percent_com = comment_dict['PoorRate']
# 调用函数,写入数据
insert(value=product_name, table='product_name', p_url=p_url)
insert(value=product_brand, table='product_brand', p_url=p_url)
insert(value=product_m_price, table='product_m_price', p_url=p_url)
insert(value=product_price, table='product_price', p_url=p_url)
insert(value=product_o_price, table='product_o_price', p_url=p_url)
insert(value=total_comment_num, table='total_comment_num', p_url=p_url)
insert(value=good_comment_num, table='good_comment_num', p_url=p_url)
insert(value=good_percent_com, table='good_percent_com', p_url=p_url)
insert(value=bad_comment_num, table='bad_comment_num', p_url=p_url)
insert(value=bad_percent_com, table='bad_percent_com', p_url=p_url)
# 请求评论信息json
icon = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=' + product_id + '&score=0&sortType=5&page=0&pageSize=10', headers=header, proxies=random.choice(proxy_list))
comment_ic = json.loads(icon.text.split('hotCommentTagStatistics":')[-1].split(',"jwotestProduct')[0])
icon = []
for ic in comment_ic:
comment_ic_name = ic['name']
comment_ic_num = ic['count']
comment_icon = comment_ic_name + '(' + str(comment_ic_num) + ')'
icon.append(comment_icon)
comment_icon_all = ','.join(icon)
# print(comment_icon_all)
insert(value=comment_icon_all, table='dict_icon', p_url=p_url)
'''
print("当前价格:" + product_price)
print("指导价格:" + product_o_price)
print("最高价格:" + product_m_price)
print("总评论数为:{}" .format(total_comment_num))
print("好评数: {}" .format(good_comment_num))
print("好评率: {}" .format(good_percent_com))
print("差评数: {}".format(bad_comment_num))
print("差评率: {}".format(bad_percent_com))
'''
if __name__ == "__main__":
urls = []
i = 0
j = 0
start = time.perf_counter()
urls = get_url()
for p_url in urls:
try:
product_id = p_url.split('/')[-1].split('.')[0] # 提取商品ID
print('正在获取第{}件商品数据并上传数据库......'.format(i))
get_data(p_url)
i = i + 1
except Exception as e:
print('当前url数据获取失败! \n错误码:{} \n当前错误条数{}'.format(e, j))
end = time.perf_counter()
print('\n程序完成!\n共爬取{}件商品数据,失败{}件,耗时{}s。'.format(i, j, end-start))
运行结果截图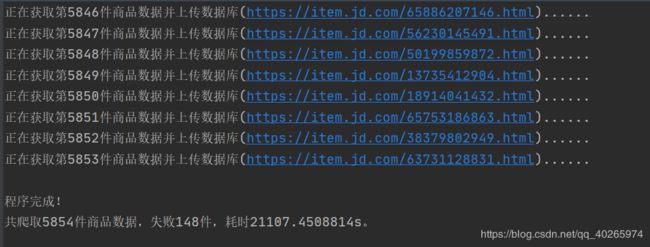
四、优化与改进
改进需求:
1.爬取速度过慢(约66000项数据),正在进行方法改进中,尝试多线程优化。
2.后续设计将进行可视化分析,见[可视化分析]栏目博客(构建中)
改进版(已完成)链接(时间由21000s优化至3000s左右)
(多线程优化版)爬虫爬取京东商品详细数据(品牌、售价、各类评论量(精确数量)、热评词及数量等) json解析部分数据