校招准备(八):javaweb基础知识
1.javaweb基础
1.1get和post区别
GET和POST的区别详细解说:

1.GET 用于获取信息,是无副作用的,是幂等的,且可缓存。 POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存。
2.GET 和 POST 只是 HTTP 协议中两种请求方式(异曲同工),而 HTTP 协议是基于 TCP/IP 的应用层协议。
报文格式上,不带参数时,最大区别就是第一行方法名不同。POST 方法请求报文第一行是这样的 POST /url HTTP/1.1 GET 方法请求报文第一行是这样的 GET /url HTTP/1.1。带参数时,在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中。
3.POST 比 GET 安全,因为数据在地址栏上不可见。然而,从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。要想安全传输,就只有加密,也就是 HTTPS。
1.2HTTP 1.0/1.1/2.0的区别。
HTTP 2.0 和 HTTP 1.1 相比有哪些优势呢?
HTTP1.0和HTTP1.1最主要的区别就是:
HTTP1.1默认是持久化连接(建立一次连接,多次请求均由这个连接完成!(如果阻塞了,还是会开新的TCP连接的),发送一次请求时,不需要等待服务端响应了就可以发送请求了,但是回送数据给客户端的时候,客户端还是要按照发送请求的顺序来接收响应)。
在HTTP1.0默认是短连接(需要等待服务端响应了才可以继续发送请求,每次与服务器交互,都需要新开一个连接)。
其他:
- HTTP 1.1中引入了
Chunked transfer-coding,范围请求,实现断点续传(实际上就是利用HTTP消息头使用分块传输编码,将实体主体分块传输) - HTTP 1.1增加host字段
- HTTP 1.1管线化(pipelining)理论,客户端可以同时发出多个HTTP请求,而不用一个个等待响应之后再请求
- 注意:这个pipelining仅仅是限于理论场景下,大部分桌面浏览器仍然会选择默认关闭HTTP pipelining!
- 所以现在使用HTTP1.1协议的应用,都是有可能会开多个TCP连接的!
- 增加缓存处理(新的字段如cache-control)
HTTP2与HTTP1.1最重要的区别就是解决了线头阻塞的问题!其中最重要的改动是:多路复用 (Multiplexing)
- 多路复用意味着线头阻塞将不在是一个问题,允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息,合并多个请求为一个的优化将不再适用。
- (我们知道:HTTP1.1中的Pipelining是没有付诸于实际的),之前为了减少HTTP请求,有很多操作将多个请求合并,比如:Spriting(多个图片合成一个图片),内联Inlining(将图片的原始数据嵌入在CSS文件里面的URL里),拼接Concatenation(一个请求就将其下载完多个JS文件),分片Sharding(将请求分配到各个主机上)......
- HTTP2所有性能增强的核心在于新的二进制分帧层(不再以文本格式来传输了),它定义了如何封装http消息并在客户端与服务器之间传输。
- 头部压缩
- 服务器推送
1.3 访问一个网站,比如 www.baidu.com 的时候,是怎么个流程。
在浏览器地址栏输入一个URL后回车,背后会进行哪些技术步骤?
1、第一步是浏览器对用户输入的网址做初步的格式化检查
2、默认使用http协议,除非小明输入的是“https ://zhihu.com”。
3、浏览器查询DNS,获取IP地址:先查内存里的DNS Cache,再查host文件,再请求DNS服务器 8.8.8.8(使用udp协议,检查ip路由表,发现需要跨域经过gateway,需要通过arp协议获取gateway的mac地址。然后将请求送到ip+端口对应的服务器,如果没有则向根域名查询)。
4.通过ip地址和端口号建立tcp链接,会返回HTTP Redirect 消息,重新访问https://zhihu.com。
5.三次握手成功后,将数据包给了tls进行传输:首先建立tls链接:
客户端:支持TLS版本1.2,以及我的认证算法、加密算法、数据校验算法,此外还有我的随机码。
服务器:你好,我也支持1.2版本,那我们就使用xx认证算法、xx加密算法、xx数据校验算法,我的随机码是xx,以及两个数字证书:证书1: “*.zhihu.com”,由GeoTrust RSA CA 2018签名并颁发,证书2: “GeoTrust RSA CA 2018”,由DigiCert Global Root CA签名并颁发。证书中携带公钥密码。
客户端首先验证证书:1.用DigiCert Global Root CA的公钥解密证书2的签名(DigiCert Global Root CA作为一个权威CA,已经被浏览器预先安装在可信任根证书列表,那么我们信任该CA的一切,当然包括其公钥,在该证书里包含了明文的公钥)解开了,证明是该CA私钥加密的,由于CA私钥只有CA知道,证书有效,并信任GeoTrust RSA CA 2018公钥。解不开,证明不是CA私钥加密,无效证书。2. 用GeoTrust RSA CA 2018的公钥解密证书1的签名。解开了就获取了zhihu.com的公钥。还需要检查的证书有效期,再检查证书是否被吊销(CRL),如果一切都没有问题,进入下一个步骤。
客户端使用*.zhihu.com”公钥加密一段随机的字符串,发送给TLS服务器。TLS服务器用自己的私钥解密,得到明文字符串。
至此,双方分享了这个神秘的字符串,双方还有早前分享的随机码(nonce),双方使用同样的算法,可以推导出相同的master key,进而推导出session key、HMAC key。Session Key用于加密/解密数据, HMAC Key主要用于保护数据的完整性,以防被第三方篡改。接下来浏览器使用sessionkey来加密请求,发送给服务器。服务器使用sessionkey解密,返回加密的反应。
1.4web安全:
1.DDOS 攻击的防范教程
备份网站,临时主页建议放到 Github Pages 或者 Netlify,它们的带宽大,可以应对攻击,而且都支持绑定域名,还能从源码自动构建。
HTTP 请求的特征一般有两种:IP 地址和 User Agent 字段。比如,恶意请求都是从某个 IP 段发出的,那么把这个 IP 段封掉就行了。或者,它们的 User Agent 字段有特征(包含某个特定的词语),那就把带有这个词语的请求拦截。
拦截可以在三个层次做。
(1)专用硬件
Web 服务器的前面可以架设硬件防火墙,专门过滤请求。这种效果最好,但是价格也最贵。
(2)本机防火墙
操作系统都带有软件防火墙,Linux 服务器一般使用 iptables。比如,拦截 IP 地址1.2.3.4的请求,可以执行下面的命令。
$ iptables -A INPUT -s 1.2.3.4 -j DROP
iptables 比较复杂,我也不太会用。它对服务器性能有一定影响,也防不住大型攻击。
(3)Web 服务器
Web 服务器也可以过滤请求。拦截 IP 地址1.2.3.4,nginx 的写法如下。
location / { deny 1.2.3.4; }
Apache 的写法是在.htaccess文件里面,加上下面一段。
Require all granted Require not ip 1.2.3.4
如果想要更精确的控制(比如自动识别并拦截那些频繁请求的 IP 地址),就要用到 WAF。这里就不详细介绍了,nginx 这方面的设置可以参考这里和这里。
Web 服务器的拦截非常消耗性能,尤其是 Apache。稍微大一点的攻击,这种方法就没用了。
CDN 指的是网站的静态内容分发到多个服务器,用户就近访问,提高速度。因此,CDN 也是带宽扩容的一种方法,可以用来防御 DDOS 攻击。
网站内容存放在源服务器,CDN 上面是内容的缓存。用户只允许访问 CDN,如果内容不在 CDN 上,CDN 再向源服务器发出请求。这样的话,只要 CDN 够大,就可以抵御很大的攻击。不过,这种方法有一个前提,网站的大部分内容必须可以静态缓存。对于动态内容为主的网站(比如论坛),就要想别的办法,尽量减少用户对动态数据的请求。
2.XSS攻击(Cross Site Scripting)
攻击者在网页中嵌入恶意脚本程序(比如在表单中提交js代码,而不是应该的用户信息),当用户打幵该网页时,脚本程序便开始在客户端的浏览器上执行,以盗取客户端cookie、用户名密码,下载执行病毒木马程序,甚至是获取客户端admin权限等。
解决办法:对用户输入的数据进行HTML转义处理,将其中的“尖括号”、“单引号”、“引号”之类的特殊字符进行转义编码:
3.csrf跨站请求伪造攻击( cross site request forgery)
通过伪装来自受信任用户的请求来利用受信任的网站。

- 首先用户C浏览并登录了受信任站点A;
- 登录信息验证通过以后,站点A会在返回给浏览器的信息中带上已登录的cookie,cookie信息会在浏览器端保存一定时间(根据服务端设置而定);
- 完成这一步以后,用户在没有登出(清除站点A的cookie)站点A的情况下,访问恶意站点B;
- 这时恶意站点 B的某个页面向站点A发起请求,而这个请求会带上浏览器端所保存的站点A的cookie;
- 站点A根据请求所带的cookie,判断此请求为用户C所发送的。
因此,站点A会报据用户C的权限来处理恶意站点B所发起的请求,而这个请求可能以用户C的身份发送 邮件、短信、消息,以及进行转账支付等操作,这样恶意站点B就达到了伪造用户C请求站点 A的目的。
受害者只需要做下面两件事情,攻击者就能够完成CSRF攻击:
- 登录受信任站点 A,并在本地生成cookie;
- 在不登出站点A(清除站点A的cookie)的情况下,访问恶意站点B。
一个需要注意的事情是:虽然cookie不能跨域,但是在从a域页面跳转到b域页面时,浏览器还是会携带a域的cookie。(我也不知道为什么,但是真的会这样。)这样的话就可以理解csrf的原因了。
解决方法:
1、尽量使用POST,限制GET
GET接口太容易被拿来做CSRF攻击,看上面示例就知道,只要构造一个img标签,而img标签又是不能过滤的数据。接口最好限制为POST使用,GET则无效,降低攻击风险。
当然POST并不是万无一失,攻击者只要构造一个form就可以,但需要在第三方页面做,这样就增加暴露的可能性。
2、将cookie设置为HttpOnly
CRSF攻击很大程度上是利用了浏览器的cookie,为了防止站内的XSS漏洞盗取cookie,需要在cookie中设置“HttpOnly”属性,这样通过程序(如JavaScript脚本、Applet等)就无法读取到cookie信息,避免了攻击者伪造cookie的情况出现。
在Java的Servlet的API中设置cookie为HttpOnly的代码如下:response.setHeader( "Set-Cookie", "cookiename=cookievalue;HttpOnly");
3、增加token
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于cookie中,因此攻击者可以在不知道用户验证信息的情况下直接利用用户的cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信总不存在于cookie之中。鉴于此,系统开发人员可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务端进行token校验,如果请求中没有token或者token内容不正确,则认为是CSRF攻击而拒绝该请求。
假设请求通过POST方式提交,则可以在相应的表单中增加一个隐藏域:
token的值通过服务端生成,表单提交后token的值通过POST请求与参数一同带到服务端,每次会话可以使用相同的token,会话过期,则token失效,攻击者因无法获取到token,也就无法伪造请求。作者:小怪聊职场
4、通过Referer识别
根据HTTP协议,在HTTP头中有一个字段叫Referer,它记录了该HTTP请求的来源地址。在通常情况下,访问一个安全受限的页面的请求都来自于同一个网站。比如某银行的转账是通过用户访问http://www.xxx.com/transfer.do页面完成的,用户必须先登录www.xxx.com,然后通过单击页面上的提交按钮来触发转账事件。当用户提交请求时,该转账请求的Referer值就会是
提交按钮所在页面的URL(本例为www.xxx. com/transfer.do)。如果攻击者要对银行网站实施CSRF攻击,他只能在其他网站构造请求,当用户通过其他网站发送请求到银行时,该请求的Referer的值是其他网站的地址,而不是银行转账页面的地址。因此,要防御CSRF攻击,银行网站只需要对于每一个转账请求验证其Referer值即可,如果是以www.xx.om域名开头的地址,则说明该请求是来自银行网站自己的请求,是合法的;如果Referer是其他网站,就有可能是CSRF攻击,则拒绝该请求。
取得HTTP请求Referer:String referer = request.getHeader("Referer");
4.文件上传漏洞

解决办法:
1.前端限制拓展名
2.服务器检查扩展名以及文件格式
3.文件上传的目录设置为不可执行
4.单独设置文件服务器的域名
5.sql注入
SQL注入的产生条件:
- 有参数传递
- 参数值带入数据库查询并且执行
解决办法如使用prestatement和使用框架。
1.5restful api:
怎样用通俗的语言解释REST,以及RESTful?
1.REST -- REpresentational State Transfer表现层状态转移。URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作。
2.URL中只使用名词来指定资源,原则上不使用动词。“资源”是REST架构或者说整个网络处理的核心。比如:
http://api.qc.com/v1/newsfeed: 获取某人的新鲜;
3.用HTTP协议里的动词来实现资源的添加,修改,删除等操作。即通过HTTP动词来实现资源的状态扭转:
GET 用来获取资源,
POST 用来新建资源(也可以用于更新资源),
PUT 用来更新资源,
DELETE 用来删除资源。
1.6servlet、tomcat、spring之间的关系:
Servlet/Tomcat/ Spring 之间的关系:
servlet/tomcat等容器/springMVC之间的关系
tomcat等容器其实就是web服务的实现,暴露端口,按照特定资源URL找到处理的servlet。然后处理请求。
web.xml其实tomcat在启动时候需要加载的配置欢迎页、Filter、Listener、Servlet等类的定义。当然不止加载这些东西,这些东西是需要加载到JVM堆内存中实例化的对象。
Tomcat启动时加载资源主要有三个阶段:
第一阶段:JVM相关资源
第二阶段:Tomcat自身相关资源
第三阶段:Web应用相关资源
客户端的请求直接打到tomcat,它监听端口,请求过来后,根据url等信息,确定要将请求交给哪个servlet去处理,然后调用那个servlet的service方法,service方法返回一个response对象,tomcat再把这个response返回给客户端。
一个http请求到来:容器将请求封装为servlet中的HttpServletRequest对象,调用init(),service()等方法输出response,由容器包装为httpresponse返回给客户端的过程。
浏览器http请求------》tomcat服务器-------》到达servlet-----》执行doget,dopost方法----》返回数据
<1>客户端发送请求到服务器端
<2>服务器将请求信息发送至Servlet
<3>Servlet生成响应内容并将其传给服务器。
<4>服务器将响应返回给客户端。

Servlet是JavaEE规范的一种,主要是为了扩展Java作为Web服务的功能,用于处理请求(service方法),统一接口。由其他内部厂商如tomcat,jetty内部实现web的功能。可以这样理解, tomcat有着Servlet接口规范,并且是个大容器,自己的Spring是个小容器, Spring里面的Servlet是Spring中的小容器。 那么既然Spring是tomcat容器里面的小容器, 自然可以拿到tomcat在接受连接之后所干的“脏活累活”了。 容器可以理解为类的概念,子容器为类的属性 或着内部类的样子。
servlet专门用来接收客户端的请求,专门接收客户端的请求数据,然后调用底层service处理数据并生成结果
生命周期:加载实例化、初始化、处理客户端请求、销毁。
加载实例化主要是交由web容器完成,而其他三个阶段则对应Servlet的init、service和destroy方法。
当Servlet初始化完成后,开始接受客户端的请求,这些请求被封装成ServletRequest类型的请求对象和ServletResponse类型的响应对象,通过service方法处理请求并响应客户端;
当一个Servlet需要从web容器中移除时,就会调用对应的destroy方法用于释放所有的资源,并且调用destroy方法之前要保证所有正在执行service方法的线程都完成执行。
当请求来容器第一次调用某个servlet时,需要先初始化init(),
但当某个请求再次打到给servlet时,容器会起多个线程同时访问一个servlet的service()方法。
单实例多线程: 主要是请求来时,会由线程调度者从线程池李取出来一个线程,来作为响应线程。这个线程可能是已经实例化的,也可能是新创建的。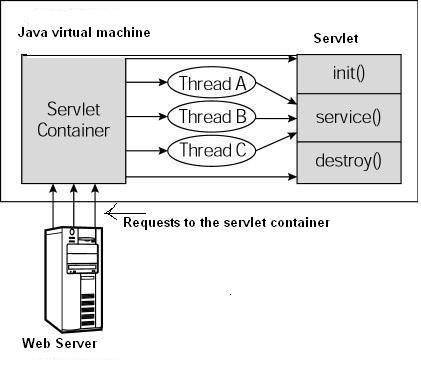
多个客户访问同一service()方法,会涉及线程安全的问题:
如果service()方法没有访问Servlet的成员变量也没有访问全局的资源比如静态变量、文件、数据库连接等,而是只使用了当前线程自己的资源,比如非指向全局资源的临时变量、request和response对象等。该方法本身就是线程安全的,不必进行任何的同步控制。
如果service()方法访问了Servlet的成员变量,但是对该变量的操作是只读操作,该方法本身就是线程安全的,不必进行任何的同步控制。
如果service()方法访问了Servlet的成员变量,并且对该变量的操作既有读又有写,通常需要加上同步控制语句。
如果service()方法访问了全局的静态变量,如果同一时刻系统中也可能有其它线程访问该静态变量,如果既有读也有写的操作,通常需要加上同步控制语句。
如果service()方法访问了全局的资源,比如文件、数据库连接等,通常需要加上同步控制语句。
Servlet容器默认是采用单实例多线程的方式处理多个请求的:
1.当web服务器启动的时候(或客户端发送请求到服务器时),Servlet就被加载并实例化(只存在一个Servlet实例);
2.容器初始化化Servlet主要就是读取配置文件(例如tomcat,可以通过servlet.xml的设置线程池中线程数目,初始化线程池通过web.xml,初始化每个参数值等等。
3.当请求到达时,Servlet容器通过调度线程(Dispatchaer Thread) 调度它管理下线程池中等待执行的线程(Worker Thread)给请求者;
4.线程执行Servlet的service方法;
5.请求结束,放回线程池,等待被调用;
(注意:避免使用实例变量(成员变量),因为如果存在成员变量,可能发生多线程同时访问该资源时,都来操作它,照成数据的不一致,因此产生线程安全问题)
spring: 任何Spring Web的entry point,都是servlet。
1.7javaweb相关的几个类:
ServletContext:
Servlet与Servlet容器之间直接通信的接口,一个web应用只独有一个ServletContext.
作用:
- 用于在web应用范围内存取共享数据,如setAttribute(String name, Object object),getAttribute()
- 获取当前Web应用的资源,如getContextPath()
- 获取服务器端的文件系统资源,如getResourceAsStream()
- 输出日志,如log(String msg) : 向Servlet的日志文件中写日志
- 在具体ServletContext 实现中,提供了添加Servlet,Filter,Listener到ServletContext里面的方法
生命周期:和web应用的生命周期一样
使用:一般由web容器实现,如tomcat
Filter:
作用:用于Web容器对请求和响应做统一处理,例如统一改变HTTP请求内容和响应内容,它可以作用在某个Servlet或一组Servlet
生命周期:加载实例化、初始化(init)、处理客户端请求(doFilter)、销毁(destroy)
使用:在doFilter方法中调用chain.doFilter(request, response)之前的代码可用来做一些请求校验,之后代码可用来做一些响应包装。
ServletRequest:
封装了客户端请求的所有信息,如果使用HTTP协议通信则包括HTTP协议的请求行和请求头。HTTP协议对应请求对象类型是HttpServletRequest类
作用:
- 获取HTTP协议请求头部,如getHeader、getHeaders
- 获取请求路径,如getContextPath、getServletPath
- 获取cookie的方法,如getCookies
- 获取session的方法,如getSession,session是存储在服务器内存中,返回响应的时候会写入浏览器一个sessionId的cookie,用来标示这一个会话
生命周期:只在servlet的service方法或过滤器的doFilter方法作用域内有效,除非启用了异步处理调用了ServletRequest接口对象的startAsync方法,此时request对象会一直有效,直到调用AsyncContext的complete方法。另外,web容器通常会为了性能而不销毁ServletRequest接口的对象,而是重复利用ServletRequest接口对象。
ServletResponse:
Servlet通过ServletResponse对象来生成响应结果。
作用:定义了一系列与生成响应结果相关的方法,如:
- setCharacterEncoding() —— 设置相应正文的字符编码。响应正文的默认字符编码为ISO-8859-1;
- setContentLength() —— 设置响应正文的长度;
- setBufferSize() —— 设置用于存放响应正文数据的缓冲区的大小
- getBufferSize() —— 获得用于存放响应正文数据的缓冲区的大小;
- reset() —— 清空缓冲区内的正文数据,并且清空响应状态代码及响应头
- resetBuffer() —— 仅仅清空缓冲区的正文数据,不清空响应状态代码及响应头;
- flushBuffer() —— 强制性地把缓冲区内的响应正文数据发送到客户端;
- isCommitted() —— 返回一个boolean类型的值,如果为true,表示缓冲区内的数据已经提交给客户,即数据已经发送到客户端;
- getOutputStream() —— 返回一个ServletOutputStream对象,Servlet用它来输出二进制的正文数据;
- getWriter() —— 返回一个PrinterWriter对象,Servlet用它来输出字符串形式的正文数据;
为了提高输出数据的效率,ServletOutputStream和PrintWriter首先把数据写到缓冲区内。当缓冲区内的数据被提交给客户后,ServletResponse的isComitted方法返回true。
生命周期:ServletResponse接口只在Servlet的service方法或过滤器的doFilter方法作用域内有效,除非它关联的ServletResponse接口调用了startAsync方法启用异步处理,此时ServletResponse接口会一直有效,直到调用AsyncContext的complete方法。另外,web容器通常会为了性能而不销毁ServletResponse接口对象,而是重复利用ServletResponse接口对象。
Listener:
当触发某个事件,如servlet context初始化完成时,需要做一些事情,servlet规范中定义了若干个Listener用于监听这些事件。
作用:用于对特定对象的生命周期和特定事件进行响应处理,主要用于对Session,request,context等进行监控。
监听域对象自身的创建和销毁的事件监听器
- ServletContextListener:ServletContext的创建和销毁:contextInitialized方法和contextDestroyed方法,作为定时器、加载全局属性对象、创建全局数据库连接、加载缓存信息等
- HttpSessionListener:HttpSession的创建和销毁:sessionCreated和sessionDestroyed方法,可用于统计在线人数、记录访问日志等
- ServletRequestListener: ServletRequest的创建和销毁:requestInitialized和requestDestroyed方法
监听域对象中的属性的增加和删除的事件监听器
- ServletContextAttributeListener、HttpSessionAttributeListener、ServletRequestAttributeListener接口。
- 实现方法:attributeAdded、attributeRemoved、attributeReplaced
监听绑定到HttpSeesion域中的某个对象的状态的事件监听器(创建普通JavaBean)
- HttpSession中的对象状态:绑定→解除绑定;钝化→活化
- 实现接口及方法:HttpSessionBindingListener接口(valueBound和valueUnbound方法)、HttpSessionActivationListener接口(sessionWillPassivate和sessionDidActivate方法)
1.8web.xml:
Tomcat在激活、加载、部署web应用时,会解析加载${CATALINA_HOME}/conf目录下所有web应用通用的web.xml,然后解析加载web应用目录中的WEB-INF/web.xml。
其实根据他们的位置,我们就可以知道,conf/web.xml文件中的设定会应用于所有的web应用程序,而某些web应用程序的WEB-INF/web.xml中的设定只应用于该应用程序本身。
如果没有WEB-INF/web.xml文件,tomcat会输出找不到的消息,但仍然会部署并使用web应用程序,servlet规范的作者想要实现一种能迅速并简易设定新范围的方法,以用作测试,因此,这个web.xml并不是必要的,不过通常最好还是让每一个上线的web应用程序都有一个自己的WEB-INF/web.xml。
web.xml中可以配置web应用名称,图标,描述,ServletContext上下文参数,Fliter配置,Listener配置,Servlet配置,会话超时配置,MIME类型配置等等。
1.9监听器(listener)、过滤器(filter)、拦截器(inceptor)。
拦截器为springmvc或者struct实现,不在这里讲。图里面的拦截器是struct的,没有参考价值。
Servlet过滤器---简介
Servlet 编写过滤器
作用:在客户端的请求访问后端资源之前,拦截这些请求。在服务器的响应发送回客户端之前,处理这些响应。
Servlet过滤器从字面上的字意理解为经过一层次的过滤处理才达到使用的要求,而其实Servlet过滤器就是服务器与客户端请求与响应的中间层组件,在实际项目开发中Servlet过滤器主要用于对浏览器的请求进行过滤处理,将过滤后的请求再转给下一个资源。
简单来说Servlet的Filter是:
● 声明式的:通过在web.xml配置文件中声明,允许添加、删除过滤器,而无需改动任何应用程序代码或jsp页面。
● 灵活的:过滤器可用于客户端的直接调用执行预处理和后期的处理工作,通过过滤链可以实现一些灵活的功能。
● 可移植的:由于现今各个web容器都是以Servlet的规范进行设计的,因此Servlet过滤器同样是跨容器的。
● 可重用的:基于其可移植性和声明式的配置方式,Filter是可重用的。
过滤器是采用了“链”的方式进行处理的,Filter接受用户的请求,并决定将请求转发给链中的下一个组件,或者终止请求直接向客户端返回一个响应。如果请求被转发了,它将被传递给链中的下一个过滤器(以web.xml过滤器的配置顺序为标准)。这个请求在通过过滤链并被服务器处理之后,一个响应将以相反的顺序通过该链发送回去。这样,请求和响应都得到了处理。
要编写一个过滤器必须实现Filter接口。实现其接口规定的方法。
实现javax.servlet.Filter接口
实现init方法,读取过滤器的初始化参数
实现doFilter方法,完成对请求或响应的过滤
调用FilterChain接口对象的doFilter方法,向后续的过滤器传递请求或响应。如果不调用chain.doFilter,请求就会被过滤掉。
public void doFilter(ServletRequest req, ServletResponse resp,
FilterChain chain) throws IOException, ServletException {
//获取请求信息(测试时可以通过get方式在URL中添加name)
//http://localhost:8080/servlet_demo/helloword?name=123
String name = req.getParameter("name");
// 过滤器核心代码逻辑
System.out.println("过滤器获取请求参数:"+name);
System.out.println("第二个过滤器执行--网站名称:www.runoob.com");
if("123".equals(name)){
// 把请求传回过滤链
chain.doFilter(req, resp);
}else{
//设置返回内容类型
resp.setContentType("text/html;charset=GBK");
//在页面输出响应信息
PrintWriter out = resp.getWriter();
out.print("name不正确,请求被拦截,不能访问web资源");
System.out.println("name不正确,请求被拦截,不能访问web资源");
}
}适用场景:1.日志记录和审核过滤器(Logging and Auditing Filters)。
- 身份验证过滤器(Authentication Filters)。
- 数据压缩过滤器(Data compression Filters)。
- 加密过滤器(Encryption Filters)。
- 触发资源访问事件过滤器。
- 图像转换过滤器(Image Conversion Filters)。
Servlet监听器详解及举例:
监听原理
1、存在事件源
2、提供监听器
3、为事件源注册监听器
4、操作事件源,产生事件对象,将事件对象传递给监听器,并且执行监听器相应监听方法
(监听器和Servlet、Filter不同,不需要url配置,监听器执行不是由用户访问的,监听器 是由事件源自动调用的,也是在web.xml配置)
Servlet监听器分为三大类
1、数据域对象创建和销毁监听器
2、数据域对象和属性变更监听器
3、绑定到 HttpSession 域中的某个对象的状态的事件监听器
(一)数据域对象创建销毁监听器 — 监听三个与对象 (三个监听器)
1、ServletContextListener : 用来监听ServletContext对象的创建和销毁
应用:
第一个:在服务器启动时,对一些对象进行初始化,并且将对象保存ServletContext数据范围内(因为在监听器内可以获得事件源对象) — 全局数据
- 例如:创建数据库连接池
第二个:对框架进行初始化 例如:Spring框架初始化通过ServletContextListener (因为监听器代码在服务器启动时执行)
- Spring框架(配置文件随服务器启动加载) org.springframework.web.context.ContextLoaderListener
第三个:实现任务调度,启动定时程序 (Timer、TimerTask) 使一个程序,定时执行
比如说每天晚上十二点给过生日的人进行生日祝福,中国移动对账户进行同步,会在服务器使用较少的时间,例如凌晨之类,启动一段程序,进行同步
java.util.Timer 一种线程设施,用于安排以后在后台线程中执行的任务。可安排任务执行一次,或者定期重复执行。
Timer提供了启动定时任务方法 schedule
* schedule(TimerTask task, Date firstTime, long period) 用来在指定一个时间启动定时器,定期循环执行
* schedule(TimerTask task, long delay, long period) 用来在当前时间delay多少毫秒后启动定时器
停止定时器,timer.cancel取消任务
2、HttpSession 数据对象创建和销毁监听器 —– HttpSessionListener
Session何时创建:request.getSession()
Session何时销毁:关闭服务器,Session过期,session.invalidate
*Session过期时间通过web.xml配置(tomcat配置文件中),默认时间30分钟
3、HttpServletRequest对象的创建和销毁监听器 —- ServletRequestListener
Request何时创建:请求发起时创建
Request何时销毁:响应结束时销毁
注意(创建销毁次数由请求次数决定):
使用forward —- request创建销毁几次 —– 一次
使用sendRedirect —- request创建销毁两次 (两次请求)
(二)ServletContext/HttpSession/ServletRequest中保存数据 创建、修改、移除监听器
(三)被绑定Session对象,自我状态感知监听器
使用场景:1.在线人数,总访问次数。
Spring 的 ApplicationContext 提供了支持事件和代码中监听器的功能。
我们可以创建 bean 用来监听在 ApplicationContext 中发布的事件。ApplicationEvent 类和
在 ApplicationContext 接口中处理的事件,如果一个 bean 实现了 ApplicationListener 接口,
当一个 ApplicationEvent 被发布以后,bean 会自动被通知。
Spring 提供了以下 5 中标准的事件:
1.上下文更新事件(ContextRefreshedEvent):该事件会在 ApplicationContext 被初始化或
者更新时发布。也可以在调用 ConfigurableApplicationContext 接口中的 refresh()方法时被
触发。
2.上下文开始事件(ContextStartedEvent):当容器调用 ConfigurableApplicationContext
的 Start()方法开始/重新开始容器时触发该事件。
3.上下文停止事件(ContextStoppedEvent):当容器调用 ConfigurableApplicationContext
的 Stop()方法停止容器时触发该事件。
4.上下文关闭事件(ContextClosedEvent):当 ApplicationContext 被关闭时触发该事件。
容器被关闭时,其管理的所有单例 Bean 都被销毁。
5.请求处理事件(RequestHandledEvent):在 Web 应用中,当一个 http 请求(request)
结束触发该事件。
除了上面介绍的事件以外,还可以通过扩展 ApplicationEvent 类来开发自定义的事件。
拦截器见3.5

1.10跨域问题
ajax跨域,这应该是最全的解决方案了
什么情况下会跨域,如何进行跨域
cookie如何跨域。
1.11request和response区别和常见方法。
Request和Response的区别:
Request 和 Response 对象起到了服务器与客户机之间的信息传递作用。Request 对象用于接收客户端浏览器提交的数据,而 Response 对象的功能则是将服务器端的数据发送到客户端浏览器。
一、Request对象的五个集合:
QueryString:用以获取客户端附在url地址后的查询字符串中的信息。
例如:stra=Request.QueryString ["strUserld"]
Form:用以获取客户端在FORM表单中所输入的信息。(表单的method属性值需要为POST)
例如:stra=Request.Form["strUserld"]
Cookies:用以获取客户端的Cookie信息。
例如:stra=Request.Cookies["strUserld"]
ServerVariables:用以获取客户端发出的HTTP请求信息中的头信息及服务器端环境变量信息。
例如:stra=Request.ServerVariables["REMOTE_ADDR"],返回客户端IP地址
ClientCertificate:用以获取客户端的身份验证信息
例如:stra=Request.ClientCertificate["VALIDFORM"],对于要求安全验证的网站,返回有效起始日期。
二、Response对象
Response对象用于动态响应客户端请示,控制发送给用户的信息,并将动态生成响应。Response对象提供了一个数据集合cookie,它用于在客户端写入cookie值。若指定的cookie不存在,则创建它。若存在,则将自动进行更新。结果返回给客户端浏览器。
语法格式:Response.Cookies(CookieName)[(key)|.attribute]=value。这里的CookiesName是指定的Cookie的名称,如果指定了Key,则该Cookie就是一个字典,Attribute属性包括Domain,Expires,HasKeys,Path,Secure。
response的方法:
Write:向客户端发送浏览器能够处理的各种数据,包括:html代码,脚本程序等。
Redirect:response.redirect("url")的作用是在服务器端重定向于另一个网页。
End:用来终止脚本程序。
Clear:要说到Clear方法,就必须提到response的Buffer属性,Buffer属性用来设置服务器端是否将页面先输出到缓冲区。语法为:Response.Buffer=True/False
Flush:当Buffer的值为True时,Flush方法用于将缓冲区中的当前页面内容立刻输出到客户端。
HTTP协议中request和response常用方法
一、request的常用方法:
1、获取请求的方式 getMethod()
2、目录的路径 getContextPath()
3、获取servlet路径 getServletString()
4、获得get请求参数 getQueryString()
5、获取请求的url getRequestURL()
getRequestURI()
6、获得协议版本 getProtocol()
7、获取客户的ip getRemoteAddr()
8、获取请求参数的通用方式
1、getParameter(Sring name)
2、根据参数的名称获得参数的数组 getParameterValues(String name)
3、获取所有请求参数的名称 getParameterNames()
4、获得所有参数的集合 getParameterMap()
9、获取session 对象 getSession()
二、response的常用方法
1、告诉浏览器数据类型 setContentType()
2、设置respon的编码格式 setCharacterEnconding()
3、返回服务器的预设错误网址并显示错误信息 sendError()
4、重定向页面 sendRedirect()
5、获取通向浏览器的字节流 getOutputStream()
6、获取通向浏览器的字符流 getWriter()
7、回传路径 encodeRedirectURL()
8、setHeader()设置消息头
9、setStatus()设置状态
10、addCookie()添加Cookie
request属性 request.getAttribute()
1)request.getParameter()取得是通过容器的实现来取得通过类似post,get等方式传入的数据,request.setAttribute()和getAttribute()只是在web容器内部流转,仅仅是请求处理阶段。
HttpServletRequest类有setAttribute()方法,而没有setParameter()方法。
1.12跳转和转发
java重定向与请求转发的区别
请求转发:
request.getRequestDispatcher().forward();
重定向:
response.sendRedirect();
例如:
请求转发:
request.getRequestDispatcher("/student_list.jsp").forward(request,response);
重定向:
response.sendRedirect(request.getContextPath + "/student_list.jsp")
转发过程:客户端首先发送一个请求到服务器,服务器匹配Servlet,并指定执行。当这个Servlet执行完后,它要调用getRequestDispacther()方法,把请求转发给指定的Servlet_list.jsp,整个流程都是在服务端完成的,而且是在同一个请求里面完成的,因此Servlet和jsp共享同一个request,在Servlet里面放的所有东西,在student_list.jsp中都能取出来。因此,student_list.jsp能把结果getAttribute()出来,getAttribute()出来后执行完把结果返回给客户端,整个过程是一个请求,一个响应。
重定向过程:客户端发送一个请求到服务器端,服务器匹配Servlet,这都和请求转发一样。Servlet处理完之后调用了sendRedirect()这个方法,这个方法是response方法。所以,当这个Servlet处理完后,看到response.sendRedirect()方法,立即向客户端返回个响应,响应行告诉客户端你必须再重新发送一个请求,去访问student_list.jsp,紧接着客户端收到这个请求后,立刻发出一个新的请求,去请求student_list.jsp,在这两个请求互不干扰、相互独立,在前面request里面setAttribute()的任何东西,在后面的request里面都获得不了。因此,在sendRedirect()里面是两个请求,两个响应。
Forward是在服务器端的跳转,就是客户端一个请求给服务器,服务器直接将请求相关参数的信息原封不动的传递到该服务器的其他jsp或Servlet去处理。而sendRedirect()是客户端的跳转,服务器会返回客户端一个响应报头和新的URL地址,原来的参数信息如果服务器没有特殊处理就不存在了,浏览器会访问新的URL所指向的Servlet或jsp,这可能不是原来服务器上的webService了。
总结:
1、转发是在服务器端完成的,重定向是在客户端发生的;
2、转发的速度快,重定向速度慢;
3、转发是同一次请求,重定向是两次请求;
4、转发地址栏没有变化,重定向地址栏有变化;
5、转发必须是在同一台服务器下完成,重定向可以在不同的服务器下完成。