fastqc是一款基于java的软件,能够对测序数据的质量进行评估。一个样本生成一个报告,当样本量过多时,逐一查看样本质量就稍显不方便,multiqc是一个基于Python的模块, 用于整合其它软件的报告的软件,能将fastqc生成的多个报告整合成一个报告的软件,这样能方便的查看所有测序数据的质量。目前支持以下软件结果的整合:
Pre-alignment tools

Alignment tools

Post-alignment tools


multiqc的安装:
在已经安装Anaconda的情况下,安装MultiQC非常简单,直接在shell命令面板中输入以下命令:
conda install -c biocondamultiqc
multiqc的使用和常用参数:
Usage: multiqc[OPTIONS]
Options:
-f, --force 重写已存在的报告
-s, --fullnames 保留样本名称
-o, --outdir TEXT 报告输出路径
-l, --file-list 提供包含搜索路径列表的文档(每行一个)
-z, --zip-data-dir 压缩数据目录
-p, --export 将报告中的图导出为静态图
-fp, --flat 只使用平面图(静态图)
-ip, --interactive 只使用动图(HighCharts Javascript)
--pdf 输出PDF格式的报告(需要安装Pandoc)
现在用最简单的命令整合fastqc的报告:
(multiqc+fastqc结果报告存放路径+multiqc报告输出路径)
> multiqc /data/home/chj/fastqc_result -o/data/home/chj/multiqc_result
命令执行完毕会生成1个html报告,直接网页打开就可以查看和一个multiqc_data的文件夹,其中包含一些数据基本的统计信息和日志文档。

multiqc整合的fastqc的报告包含以下几个部分:
1 General Statistics:所有样本数据基本情况统计
%Dups——重复reads的比例
%GC——GC含量占总碱基的比例,比例越小越好
Length——测序长度
M Seqs——总测序量(单位:millions)

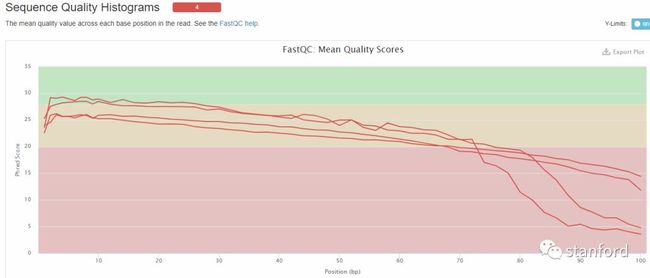
2 Sequence Quality Histograms:每个read各位置碱基的平均测序质量
横坐标——碱基的位置
纵坐标——质量分数
质量分数=-10log10p(p代表错误率),所以当质量分数为40的时候,p就是0.0001。此时说明测序质量非常好。
绿色区间——质量很好,
橙色区间——质量合理。
红色区间——质量不好。
此处可以看出我的4个样本在70个碱基后的测序质量平均线落在红色区间,测序质量不合格。
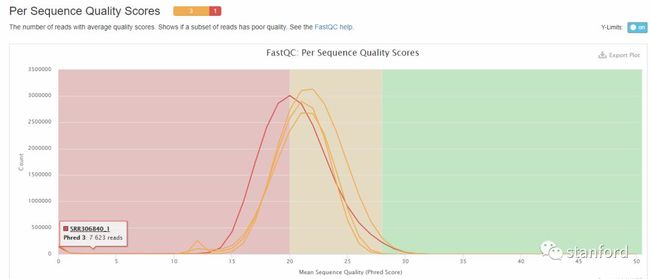
3 PerSequence Quality Scores 具有平均质量分数的reads的数量
横坐标——平均序列质量分数
纵坐标——reads数
绿色区间——质量很好
橙色区间——质量合理
红色区间——质量不好
当峰值小于27时——warning
当峰值小于20时——fail
由此图中可以看出低质量reads占整体reads的比例(估算各颜色区域曲线下面积)
图中可以看出:4个样本中有1个样本的最高峰值在20左右,低质量read数量占总体reads的比例大概在50%,所以这个样本的测序质量是不合格的。
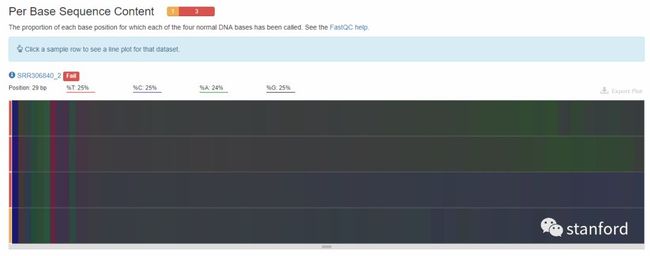
4 Per Base Sequence Content :每个read各位置碱基ATCG的比列
对所有reads的每一个位置,统计ATCG四种碱基的分布,
横坐标——碱基位置,
纵坐标——样本。
%T——红色
%C——蓝色
%A——绿色
%G——紫色
reads每个位置的颜色显示由4种颜色的比例混合而成,哪一个碱基的比例大,则趋近于这个碱基所代表的颜色。
正常情况下每个位置每种碱基出现的概率是相近的。
如果ATGC在任何位置的差值大于10%——warning
如果ATGC在任何位置的差值大于20%——fail
由图中可知:reads的前半部分大概11个bp左右的ATGC含量比例是非常不均匀的,可能有过表达的序列的污染。
5 Per Sequence GC Content :reads的平均GC含量
横坐标——GC含量百分比
纵坐标——数量
正常的样本的GC含量曲线会趋近于正态分布曲线,曲线形状的偏差往往是由于文库的污染或是部分reads构成的子集有偏差(overrepresented reads)。形状接近正态但偏离理论分布的情况提示我们可能有系统偏差。
偏离理论分布的reads超过15%时——warning
偏离理论分布的reads超过30%时——fail

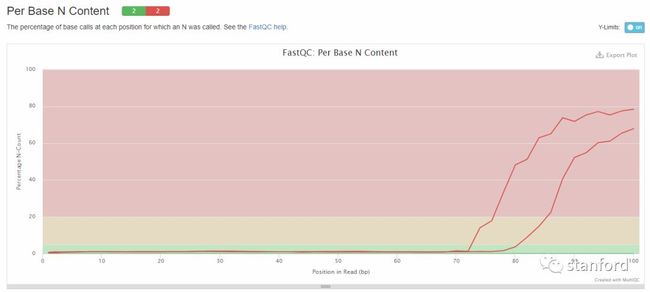
6 Per Base N Content :每条reads各位置N碱基含量比例
当测序仪器不能辨别某条reads的某个位置到底是什么碱基时,就会产生“N”,统计N的比率。正常情况下,N值非常小。
横坐标——read中的位置
纵坐标——N的数量比
当任意位置的N的比例超过5%——warning
当任意位置的N的比例超过20%——fail
由图中看出,有两个样本在70bp后的N碱基的含量大幅增加,甚至达到了80%。
7 Sequence Duplication Levels:每个序列的相对重复水平
横坐标:每个序列的相对重复水平
纵坐标:在文库中的比例
当非unique的reads占总数的比例大于20%时——warning
当非unique的reads占总数的比例大于50%时——fail
测序深度越高,越容易产生一定程度的duplication,这是正常的现象,但如果duplication的程度很高,就提示我们可能有bias的存在。

8 Overrepresented sequences:文库中过表达序列的比例
横坐标——过表达序列的比例
纵坐标——样本
过表达序列的比例>0.1%——warning
过表达序列的比例>1%——warning
一条序列的重复数,因为一个转录组中有非常多的转录本,一条序列再怎么多也不太会占整个转录组的一小部分(比如1%),如果出现这种情况,不是这种转录本巨量表达,就是样品被污染。这个模块列出来大于全部转录组1%的reads序列,但是因为用的是前100,000条reads,所以其实参考意义不大。

9 Adapter Content 接头含量
横坐标——碱基位置
纵坐标——占序列的百分比
>5%——warning
>10%——fail
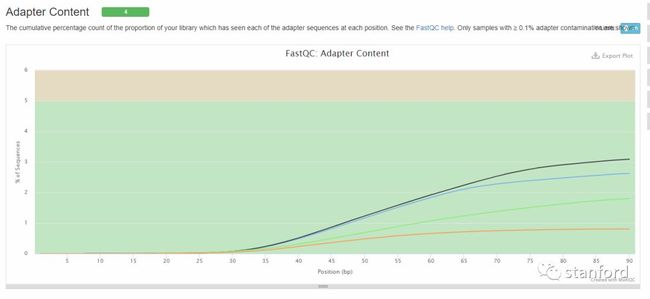
fastqc帮助我们检测测序数据的质量,具体问题具体分析,后续我们还需要去除接头和质量不好的reads,去污染等操作来进行数据过滤。
参考:
https://www.jianshu.com/p/303de2c95239
https://www.jianshu.com/p/14fd4de54402
https://blog.csdn.net/ada0915/article/details/77201871
