ELK下Logstash性能调优
介绍
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,还有强大的插件功能,常用于日志处理。
Logstash优化
Logstash建议在修改配置项以提高性能的时候,每次只修改一个配置项并观察其性能和资源消耗(cpu、io、内存)。性能检查项包括:
1、检查input和output设备
1)、CPU
2)、Memory
3)、io
1、磁盘io
2、网络io
2、检查jvm堆
3、检查工作线程设置
Logstash优点
1、可伸缩性
节拍应该在一组Logstash节点之间进行负载平衡。
建议至少使用两个Logstash节点以实现高可用性。
每个Logstash节点只部署一个Beats输入是很常见的,但每个Logstash节点也可以部署多个Beats输入,以便为不同的数据源公开独立的端点。
2、弹性
Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹性,确保磁盘冗余非常重要。对于内部部署,建议您配置RAID。在云或容器化环境中运行时,建议您使用具有反映数据SLA的复制策略的永久磁盘。
3、可过滤
对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
4、可扩展插件生态系统,提供超过200个插件,以及创建和贡献自己的灵活性。
Logstash缺点
Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
Logstash的使用
logstash有两种方式运行,分别是命令行的方式、定义配置文件方式
1、使用命令行运行一个简单的logstash程序
#logstash/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
在控制台输入 abc ,控制台会输出如下内容:
{
"message" => "abc",
"@version" => "1",
"@timestamp" => "2016-08-20T03:33:00.769Z",
"host" => "iZ23tzjZ"
}
2、配置语法讲解
最基本的配置文件定义,必须包含input 和 output。
修改logstash.conf文件,如下:
# 最基本的配置文件定义,必须包含input 和 output。
input{
stdin{ }
}
output{
stdout{
codec=>rubydebug
}
}
# 如果需要对数据进操作,则需要加上filter段
input{
stdin{ }
}
filter{
# 里面可以包含各种数据处理的插件,如文本格式处理 grok、键值定义 kv、字段添加、
# geoip 获取地理位置信息等等...
}
output{
stdout{
codec=>rubydebug
}
}
# 可以定义多个输入源与多个输出位置
input{
stdin{ }
file{
path => ["/var/log/message"]
type => "system"
start_position => "beginning"
}
}
output{
stdout{
codec=>rubydebug
}
file {
path => "/var/datalog/mysystem.log.gz"
gzip => true
}
}
运行命令:
logstash -f logstash.conf
Logstash持久化到磁盘
当发生异常情况,比如logstash重启,有可能发生数据丢失,可以选择logstash持久化到磁盘,修改之前重启logstash数据丢失,修改之后重启logstash数据不丢失。以下是具体操作:
在config/logstash.yml中进行配置以下内容
queue.type: persisted
path.queue: /usr/share/logstash/data #队列存储路径;如果队列类型为persisted,则生效
queue.page_capacity: 250mb #队列为持久化,单个队列大小
queue.max_events: 0 #当启用持久化队列时,队列中未读事件的最大数量,0为不限制
queue.max_bytes: 1024mb #队列最大容量
queue.checkpoint.acks: 1024 #在启用持久队列时强制执行检查点的最大数量,0为不限制
queue.checkpoint.writes: 1024 #在启用持久队列时强制执行检查点之前的最大数量的写入事件,0为不限制
queue.checkpoint.interval: 1000 #当启用持久队列时,在头页面上强制一个检查点的时间间隔
修改完后,重启logstash
测试步骤:模拟数据写入logstash,重启Logstash
测试结果:数据量没有变少,数据没有丢失
优化input,filter,output的线程模型。
增大 filter和output worker 数量 通过启动参数配置 -w 48 (等于cpu核数)
logstash正则解析极其消耗计算资源,而我们的业务要求大量的正则解析,因此filter是我们的瓶颈。
官方建议线程数设置大于核数,因为存在I/O等待。
考虑到我们当前节点同时部署了ES节点,ES对CPU要求性极高,因此设置为等于核数。
增大 woker 的 batch_size 150 -> 3000 通过启动参数配置 -b 3000
batch_size 参数决定 logstash 每次调用ES bulk index API时传输的数据量,考虑到我们节点机256G内存,应该增大内存消耗换取更好的性能。
增大logstash 堆内存 1G -> 16G
logstash是将输入存储在内存之中,worker数量 * batch_size = n * heap (n 代表正比例系数)
worker * batch_size / flush_size = ES bulk index api 调用次数
logstash的优化相关配置
默认配置 —> pipeline.output.workers: 1官方建议是等于 CPU 内核数
可优化为 ---> pipeline.output.workers: 不超过pipeline 线程数
默认配置 —>** pipeline.workers:** 2
可优化为 —> pipeline.workers: CPU 内核数(或几倍 cpu 内核数)
实际 output 时的线程数
默认配置 —> pipeline.output.workers: 1
可优化为 —> pipeline.output.workers: 不超过 pipeline 线程数
每次发送的事件数
默认配置 ---> pipeline.batch.size: 125
可优化为 ---> pipeline.batch.size: 1000
发送延时
默认配置 ---> pipeline.batch.delay: 5
可优化为 ---> pipeline.batch.size: 10
# pipeline线程数,官方建议是等于CPU内核数
pipeline.workers: 24
# 实际output时的线程数
pipeline.output.workers: 24
# 每次发送的事件数
pipeline.batch.size: 3000
# 发送延时
pipeline.batch.delay: 5
PS:由于我们的ES集群数据量较大(>28T),所以具体配置数值视自身生产环境
在查看logstash日志过程中,我们看到了大量的以下报错
[2017-03-18T09:46:21,043][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 429 ({"type"=>"es_rejected_execution_exception", "reason"=>"rejected execution of org.elasticsearch.transport.TransportService$6@6918cf2e on EsThreadPoolExecutor[bulk, queue capacity = 50, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@55337655[Running, pool size = 24, active threads = 24, queued tasks = 50, completed tasks = 1767887463]]"})
[2017-03-18T09:46:21,043][ERROR][logstash.outputs.elasticsearch] Retrying individual actions
查询官网,确认为时ES的写入遇到了瓶颈
注意:当batch.size增大,es处理的事件数就会变少,写入也就愉快了。此问题用一下办法解决
就是你的bulk线程池处理不过来你的请求。处理方案:调整你es集群的bulk队列大小(默认为50),或增加你的es内存
解决办法 :
官方的建议是提高每次批处理的数量,调节传输间歇时间。当batch.size增大,es处理的事件数就会变少,写入也就愉快了。
vim /etc/logstash/logstash.yml
#
pipeline.workers: 24
pipeline.output.workers: 24
pipeline.batch.size: 10000
pipeline.batch.delay: 10
具体的worker/output.workers数量建议等于CPU数,batch.size/batch.delay根据实际的数据量逐渐增大来测试最优值。
总结
- 通过设置 -w 参数指定 pipeline worker 数量,也可直接修改配置文件 logstash.yml。这会提高 filter 和 output 的线程数,如果需要的话,将其设置为 cpu 核心数的几倍是安全的,线程在 I/O 上是空闲的。
- 默认每个输出在一个 pipeline worker 线程上活动,可以在输出 output 中设置 workers 设置,不要将该值设置大于
pipeline worker 数。 - 还可以设置输出的 batch_size 数,例如 ES 输出与 batch size 一致。
- filter 设置 multiline 后,pipline worker 会自动将为 1,如果使用 filebeat,建议在 beat中就使用 multiline,如果使用 logstash 作为 shipper,建议在 input 中设置 multiline,不要在filter 中设置 multiline
采集端
通过设置过滤器,仅保留xcom中包含Routing-async的日志
发送到redis使用批量提交batch=>true
Logstash配置max_open_files=>20000
Logstash配置sincedb_path=>sincedb_trace
Logstash配置congestion_threshold=>5000000
Logstash性能测试,模拟数据量1千万条
Logstash有kibana专门的模拟数据插件,以及速率分析工具
操作步骤:
配置Logstash目录下面的pipeline/logstash.conf,配置完重启Logstash
input{
generator {
count => 10000000 # 模拟数据1千万条
message =>'INFO 2018-07-30 0911 springfox.documentation.spring.web.readers.operation.CachingOperationNameGenerator[startingWith:40] - Generating unique operation named: getUsingGET1$i' # 模拟数据具体内容
codec=>multiline { #multiline插件,用于合并事件
pattern => "^\s" #匹配空格
what=>"previous" #当匹配到空格,合并到上一个事件,如果是next,则合并到下一个事件
}
type=>"probe_log" #类型名称
}
}
filter {
grok {
match =>{ "message" => "%{LOGLEVEL:level}\s%{TIMESTAMP_ISO8601:timestamp}\s%{JAVACLASS:class}[%{WORD:method}:%{NUMBER:line}]\s-\s(?([\s\S]*))" } #通过正则表达式匹配日志
}
date {
match => [ "timestamp" , "yyyy-MM-dd HHss", "ISO8601" ] #匹配timestamp字段
target => "@timestamp" #覆盖@timestamp
}
mutate {
remove_field => "timestamp" #移除timestamp字段
}
}
output {
elasticsearch{ #输出到elasticsearch
hosts => ["192.168.2.227:9200"]
index => "logstash-api-%{+YYYY.MM.dd}"
}
1千万条数据测试结果
模拟数据量1千万条
通过kibana的monitoring监控
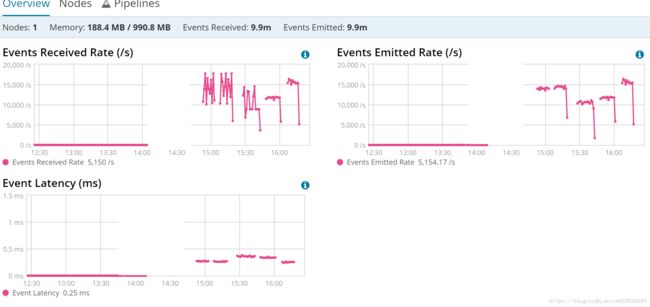
后面四个分别为:使用持久队列过滤、使用持久队列不过滤、使用内存队列过滤、使用内存队列不过滤的情况,估算出下面一张表

扩展
【日志处理】logstash性能优化配置
2W条数据用时4秒完成,每秒5000条左右,昨天是同时写入到文件和标准输出,看起来是output的问题,这块性能应当可以满足性能要求了
后继我会继续把结果输出到tcp,kafka来测试经过grok后的性能
Logstash读写性能调整优化
logstash吞吐率优化
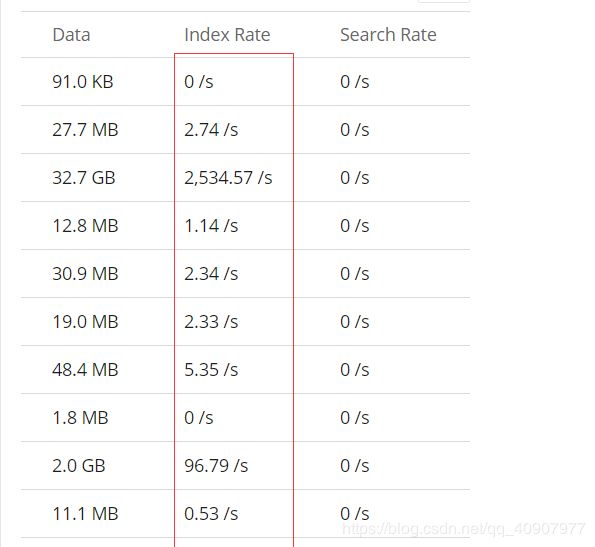
转载来源链接: http://www.leiyawu.com/2018/04/13/logstash优化/
问题一
最近发现kibana的日志传的很慢,常常查不到日志,由于所有的日志收集都只传输到了一个logstash进行收集和过滤,于是怀疑是否是由于logstash的吞吐量存在瓶颈。一看,还真是到了瓶颈。
优化过程
经过查询logstash完整配置文件,有几个参数需要调整
# pipeline线程数,官方建议是等于CPU内核数
pipeline.workers: 24
# 实际output时的线程数
pipeline.output.workers: 24
# 每次发送的事件数
pipeline.batch.size: 3000
# 发送延时
pipeline.batch.delay: 5
PS:由于我们的ES集群数据量较大(>28T),所以具体配置数值视自身生产环境
优化结果
ES的吞吐由每秒9817/s提升到41183/s,具体可以通过x-pack的monitor查看。
问题二
在查看logstash日志过程中,我们看到了大量的以下报错
[2017-03-18T09:46:21,043][INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 429 ({"type"=>"es_rejected_execution_exception", "reason"=>"rejected execution of org.elasticsearch.transport.TransportService$6@6918cf2e on EsThreadPoolExecutor[bulk, queue capacity = 50, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@55337655[Running, pool size = 24, active threads = 24, queued tasks = 50, completed tasks = 1767887463]]"})
[2017-03-18T09:46:21,043][ERROR][logstash.outputs.elasticsearch] Retrying individual actions
查询官网,确认为时ES的写入遇到了瓶颈
Make sure to watch for TOO_MANY_REQUESTS (429) response codes (EsRejectedExecutionException with the Java client), which is the way that Elasticsearch tells you that it cannot keep up with the current indexing rate. When it happens, you should pause indexing a bit before trying again, ideally with randomized exponential backoff.
我们首先想到的是来调整ES的线程数,但是官网写到”Don’t Touch There Settings!”, 那怎么办?于是乎官方建议我们修改logstash的参数pipeline.batch.size
在ES5.0以后,es将bulk、flush、get、index、search等线程池完全分离,自身的写入不会影响其他功能的性能。
来查询一下ES当前的线程情况:
GET _nodes/stats/thread_pool?pretty
{
"_nodes": {
"total": 6,
"successful": 6,
"failed": 0
},
"cluster_name": "dev-elasticstack5.0",
"nodes": {
"nnfCv8FrSh-p223gsbJVMA": {
"timestamp": 1489804973926,
"name": "node-3",
"transport_address": "192.168.3.***:9301",
"host": "192.168.3.***",
"ip": "192.168.3.***:9301",
"roles": [
"master",
"data",
"ingest"
],
"attributes": {
"rack": "r1"
},
"thread_pool": {
"bulk": {
"threads": 24,
"queue": 214,
"active": 24,
"rejected": 30804543,
"largest": 24,
"completed": 1047606679
},
......
"watcher": {
"threads": 0,
"queue": 0,
"active": 0,
"rejected": 0,
"largest": 0,
"completed": 0
}
}
}
}
}
其中:”bulk”模板的线程数24,当前活跃的线程数24,证明所有的线程是busy的状态,queue队列214,rejected为30804543。那么问题就找到了,所有的线程都在忙,队列堵满后再有进程写入就会被拒绝,而当前拒绝数为30804543。
优化方案
问题找到了,如何优化呢。官方的建议是提高每次批处理的数量,调节传输间歇时间。当batch.size增大,es处理的事件数就会变少,写入也就越快了
vim /etc/logstash/logstash.yml
#
pipeline.workers: 24
pipeline.output.workers: 24
pipeline.batch.size: 10000
pipeline.batch.delay: 10
具体的worker/output.workers数量建议等于CPU数,batch.size/batch.delay根据实际的数据量逐渐增大来测试最优值。
logstash获取时间的问题
https://elasticsearch.cn/question/3838
注意 :系统的locale设置不是english,因此logstash用到的joda无法理解Dec这样的月份格式。 要写出来,不然报错。
正确写法 :
date {
target => "runtime"
locale => en
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
logstash学习(四)—— 多管道
多管道配置
如果需要在同一个进程运行多个管道(pipeline),可以配置logstash的pipelines.yml文件,该文件在logstash/config目录下。配置文件的结构如下:
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: my-other-pipeline
path.config: "/etc/different/path/p2.cfg"
queue.type: persisted
启动
在logstash的bin目录下:
# ./logstash
在没有参数的情况下启动logstash时,它将读取pipelines.yml文件并实例化文件中指定的所有管道,当使用-e或-f时,Logstash会忽略pipelines.yml文件,并记录对此的警告。
参考链接 :
Logstash的介绍、原理、优缺点、使用、持久化到磁盘、性能测试 :https://blog.csdn.net/u010739163/article/details/82022327?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
Logstash 日志管理工具 : http://www.ttlsa.com/log-system/installing-logstash-on-rhel-and-centos/
Logstash性能调优 : https://blog.csdn.net/it_lihongmin/article/details/79728812
Logstash读写性能调整优化 : https://www.cnblogs.com/zlslch/p/6624606.html
logstashlogstash 的优化相关配置及性能的检查 : http://www.aieve.cn/article/1573442554169
logstash学习(四)—— 多管道 : https://www.dazhuanlan.com/2019/10/16/5da647d483047/
logstash优化 : https://www.jianshu.com/p/8b0428a7214b
logstash吞吐率优化 : https://www.leiyawu.com/2018/04/13/logstash%E4%BC%98%E5%8C%96/
日志处理】logstash性能优化配置 : https://www.cnblogs.com/junneyang/p/5476849.html
记录一次ELK集群优化 : https://blog.csdn.net/davinciyxw/article/details/77449392