Java1.5 引入了 java.util.concurrent 包,其中 Collection 类的实现允许在运行过程中修改集合对象。实际上, Java 的集合框架是[迭代器设计模式]的一个很好的实现。
为什么需要使用 ConcurrentHashMap ?
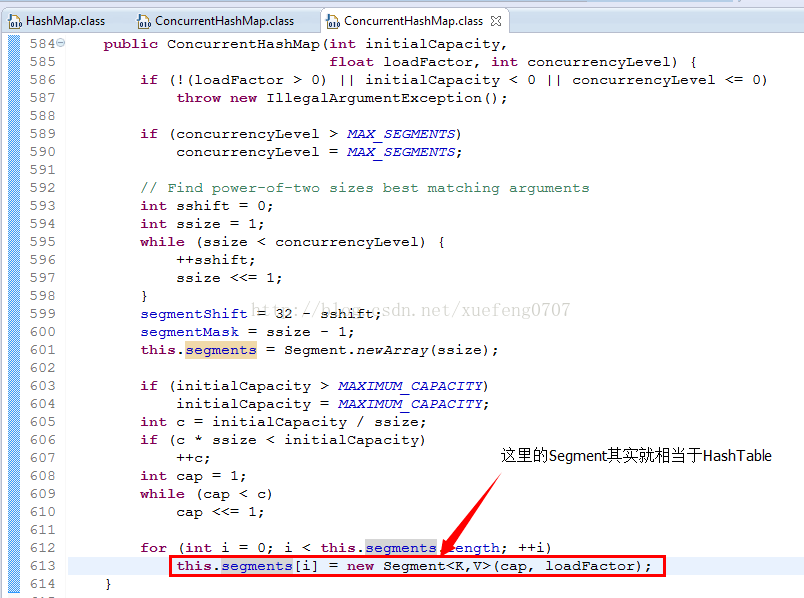
HashMap 不是线程安全的,因此多线程操作需要注意,通常使用 HashTable 或者 Collections.synchronizedMap() 来返回线程安全的 HashMap ,但是这两种方法都是对所有方法实现同步,导致读写性能比较低,而 ConcurrentHashMap 引入“分段锁”的概念,可以理解为把一个大的 Map 差分成小的 HashTable ,根据 key.hashCode() 来决定把 key 放到哪个 HashTable 中去。
就是把 Map 分成了N个 Segment , put 和 get 的时候,都是现根据 key.hashCode() 算出放到哪个Segment中:
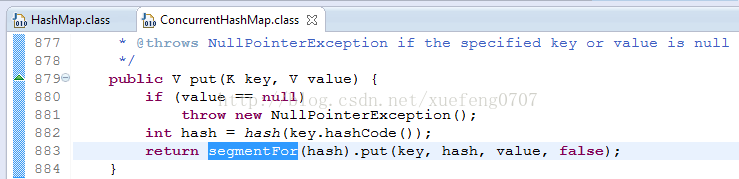
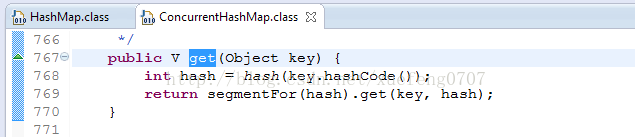
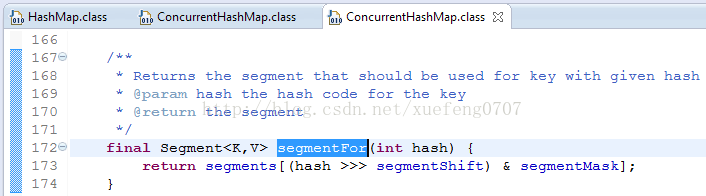
对比:
ConcurrentHashMap 与 HashMap 很相似,但是它支持在运行时修改集合对象。
例子:
ConcurrentHashMapExample.java
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
//ConcurrentHashMap
Map myMap = new ConcurrentHashMap();
myMap.put("1", "1");
myMap.put("2", "1");
myMap.put("3", "1");
myMap.put("4", "1");
myMap.put("5", "1");
myMap.put("6", "1");
System.out.println("ConcurrentHashMap before iterator: "+myMap);
Iterator it = myMap.keySet().iterator();
while(it.hasNext()){
String key = it.next();
if(key.equals("3")) myMap.put(key+"new", "new3");
}
System.out.println("ConcurrentHashMap after iterator: "+myMap);
//HashMap
myMap = new HashMap();
myMap.put("1", "1");
myMap.put("2", "1");
myMap.put("3", "1");
myMap.put("4", "1");
myMap.put("5", "1");
myMap.put("6", "1");
System.out.println("HashMap before iterator: "+myMap);
Iterator it1 = myMap.keySet().iterator();
while(it1.hasNext()){
String key = it1.next();
if(key.equals("3")) myMap.put(key+"new", "new3");
}
System.out.println("HashMap after iterator: "+myMap);
}
}
输出如下:
ConcurrentHashMap before iterator: {1=1, 5=1, 6=1, 3=1, 4=1, 2=1}
ConcurrentHashMap after iterator: {1=1, 3new=new3, 5=1, 6=1, 3=1, 4=1, 2=1}
HashMap before iterator: {3=1, 2=1, 1=1, 6=1, 5=1, 4=1}
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextEntry(HashMap.java:793)
at java.util.HashMap$KeyIterator.next(HashMap.java:828)
at com.test.ConcurrentHashMapExample.main(ConcurrentHashMapExample.java:44)
明显 ConcurrentHashMap 可以支持向 map 中添加新元素,而 HashMap 则抛出了 ConcurrentModificationException。
介绍 ConcurrentHashMap:
ConcurrentHashMap (简称 CHM )是在 Java 1.5作为 Hashtable 的替代选择新引入的,是 concurrent 包的重要成员。在 Java 1.5之前,如果想要实现一个可以在多线程和并发的程序中安全使用的 Map ,只能在 HashTable 和 synchronized Map 中选择,因为 HashMap 并不是线程安全的。但再引入了 CHM 之后,我们有了更好的选择。 CHM 不但是线程安全的,而且比 HashTable 和 synchronizedMap 的性能要好。相对于 HashTable 和 synchronizedMap 锁住了整个 Map , CHM 只锁住部分 Map 。 CHM 允许并发的读操作,同时通过同步锁在写操作时保持数据完整性。
Java 中 ConcurrentHashMap 的实现:
CHM 引入了分割,并提供了 HashTable 支持的所有的功能。在 CHM 中,支持多线程对 Map 做读操作,并且不需要任何的 blocking --因为 CHM 将 Map 分割成了不同的部分,在执行风行操作时只锁住一部分。根据默认的并发级别, Map 被分割成16个部分,并且由不同的锁控制。这意味着,同时最多可以有16个写线程操作 Map 。
另外一个重点是在迭代遍历 CHM 时, keySet 返回的 iterator 是弱一直和 fail-safe 的,可能不会返回某些最近的改变,并且在遍历中,如果已经遍历的数组上的内容发生了变化,是不会抛出 ConcurrentModificationException 的异常。
什么时候使用 ConcurrentHashMap ?(待求证)
CHM 适用于读者数量超过写者时,当写者数量大于等于读者时, CHM 的性能是低于 Hashtable 和 synchronized Map 的。这是因为当锁住了整个Map时,读操作要等待对同一部分执行写操作的线程结束。 CHM 适用于做 cache ,在程序启动时初始化,之后可以被多个请求线程访问。正如 Javadoc 说明的那样, CHM 是 HashTable 一个很好的替代,但要记住, CHM 的比 HashTable 的同步性稍弱。
ConcurrentHashMap 小总结:
*** CHM 允许并发的读和线程安全的更新操作
***在执行写操作时, CHM 只锁住部分的 Map
***并发的更新是通过内部根据并发级别将 Map 分割成小部分实现的
***高的并发级别会造成时间和空间的浪费,低的并发级别在写线程多时会引起线程间的竞争
*** CHM 的所有操作都是线程安全
*** CHM 返回的迭代器是弱一致性, fail-safe 并且不会抛出 ConcurrentModificationException 异常
*** CHM 不允许 null 的键值
***可以使用 CHM 代替 HashTable,但要记住 CHM 不会锁住整个 Map
HashMap 与 ConcurrentHashMap对比:
HashMap 的结构:
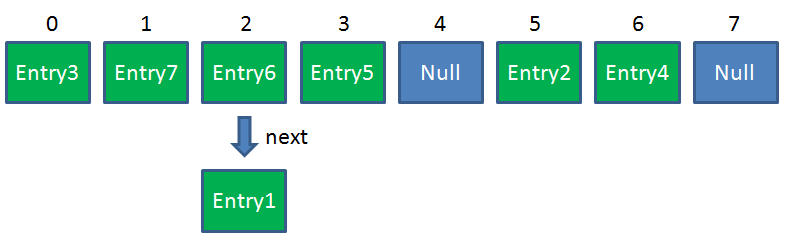
简单来说, HashMap 是一个Entry对象的数组。数组中的每一个 Entry 元素,又是一个链表的头节点。
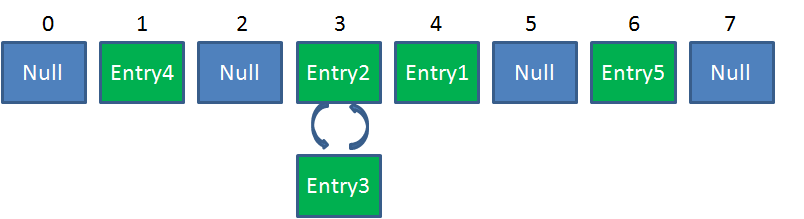
Hashmap 不是线程安全的。在高并发环境下做插入操作,有可能出现下面的环形链表:
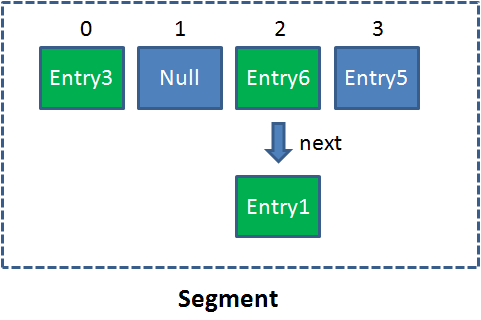
Segment 是什么呢? Segment 本身就相当于一个 HashMap 对象。
同 HashMap 一样, Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点。
单一的 Segment 结构如下:
像这样的 Segment 对象,在 ConcurrentHashMap 集合中有多少个呢?有2的N次方个,共同保存在一个名为 segments 的数组当中。
因此整个ConcurrentHashMap的结构如下:
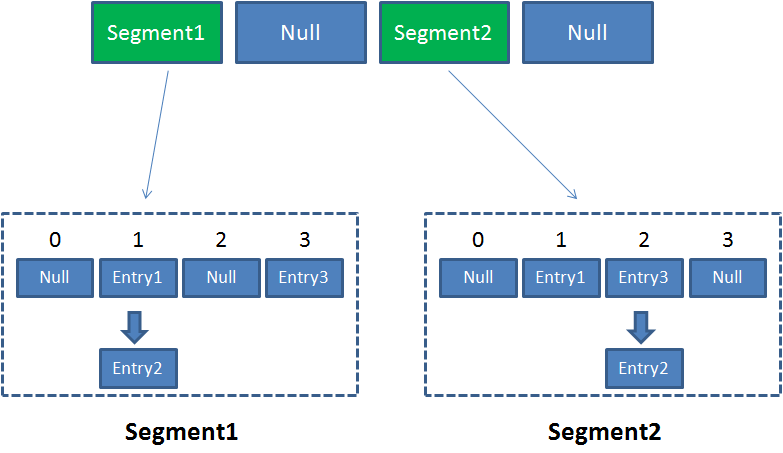
可以说,ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。
附上 ConcurrentHashMap 遍历方式:
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
Java 中遍历 Map 的四种方式,这里使用的是 ConcurrentHashMap,
-
可以替换为 HashMap
*/
public class IteratorMap {
public static void main(String[] args) {
Map
init(map);//方式一:在 for-each 循环中使用 entries 来遍历 System.out.println("方式一:在 for-each 循环中使用 entries 来遍历"); for(Map.Entry}
/**
- 初始化 Map
- @param map
*/
private static void init(Map
if(map == null) {
throw new RuntimeException("参数为空,无法执行初始化");
}
for(int i = 0; i < 10; i ++) {
map.put(String.valueOf(i), String.valueOf(i));
}
}
}
运行结果:
方式一:在 for-each 循环中使用 entries 来遍历
Key = 0, Value = 0
Key = 1, Value = 1
Key = 2, Value = 2
Key = 3, Value = 3
Key = 4, Value = 4
Key = 5, Value = 5
Key = 6, Value = 6
Key = 7, Value = 7
Key = 8, Value = 8
Key = 9, Value = 9
方法二:在 for-each 循环中遍历 keys 或 values ,这种方式适用于需要值或者键的情况
key = 0
key = 1
key = 2
key = 3
key = 4
key = 5
key = 6
key = 7
key = 8
key = 9
value = 0
value = 1
value = 2
value = 3
value = 4
value = 5
value = 6
value = 7
value = 8
value = 9
使用Iterator遍历,并且使用泛型:
Key = 0, Value = 0
Key = 1, Value = 1
Key = 2, Value = 2
Key = 3, Value = 3
Key = 4, Value = 4
Key = 5, Value = 5
Key = 6, Value = 6
Key = 7, Value = 7
Key = 8, Value = 8
Key = 9, Value = 9
使用Iterator遍历,并且不使用泛型
Key = 1, Value = 1
Key = 2, Value = 2
Key = 3, Value = 3
Key = 4, Value = 4
Key = 5, Value = 5
Key = 6, Value = 6
Key = 7, Value = 7
Key = 8, Value = 8
Key = 9, Value = 9
方式四:通过键找值遍历
Key = 1, Value = 1
Key = 2, Value = 2
Key = 3, Value = 3
Key = 4, Value = 4
Key = 5, Value = 5
Key = 6, Value = 6
Key = 7, Value = 7
Key = 8, Value = 8
Key = 9, Value = 9
实现可以参考:https://blog.csdn.net/xuefeng0707/article/details/40834595