水下目标检测比赛学习笔记
水下目标检测比赛学习笔记
- 摘要
- 比赛结束后
- 什么是backbone
- 创建underwater.py,并在/_/_init/_/_.py添加类名,使得自己的数据能够被关联上去
- error:gt_masks_ann.append(ann['segmentation']) keyError:'sementation'
- 修改config.py
- 修改train.py,添加--load_from
- num_classes=5 #类别数4加1(背景)
- 修改dataset_type,以及data_root
- 修改数据集的路径
- imgs_per_gpu=2, 每张GPU同时跑几张图片,越大越好,但受限于显存大小
- workers_per_gpu=2,每张GPU的线程数,单卡时设为0才能跑起来
- 修改epoch数,跑多少个epoch
- CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 使得程序可以看到0,1,2,3,4,5,6,7号GPU,但需要在train.py中把--gpus设为8,才会8块都用上,若是--gpus为1,则即使看到了8块卡也只会使用1块卡。
- raise AssertionError("Invalid device id")
- 写train.sh脚本方便启动train.py,写好多条命令,多个网络一个一个来跑 '\'是换行符
- 在Windows上的pycharm写的sh在linux上运行不了,估计是因为文档格式不一致导致的,解决办法:用MobaXterm连到linux上进行编辑,就可以运行。
- 要下载模型,就把pretrained设为None
- 因为我们把class_num从81(coco数据集的类别数是80+1(背景))改为了5,所以会有size mismatch 在bbox_head 的weight和bias上。
- cascade有3个镜像的backbone,所以共有6个size mismatch
- 在pycharm再添加一个local命令端
- conda activate open-mmlab 不成功,因为lyuan的conda版本比较老(或路径没导入),要用source activate open-mmlab
- 模型训练完后,生成.csv文件
- test的时候,通常用soft_nms,max_per_img=200
- scp 前者 后者 #本地linux和服务器之间传送文件,前者传后者,注意服务器端加ip的写法
- 本地pycharm新添加一个连接服务器的terminal
- def parse_args()如何写
- ModuleNotFoundError: No module named 'mmdet' #没有激活open-mmlab环境
- 训练时用train_pipeline,测试时用test_pipeline,否则会报KeyError: 'ann_info'
- batch_size=imgs_per_gpu
- 软连接 :ln -s /home/lyuan/pycharm_code/mmdetection_4-4/exp exp
- 实验期间,因为修改代码,导致出现了修复不了的bug,重新装了mmdetection
- gcc编译器要和cuda版本对应上:
- DataLoader worker (pid XXXX) is killed by signal: Bus error(Pytorch多workers读取Data Loader)
- raise Exception()的用法
- bug
- raise NotImplementedError (infer_test_to_csv.py fovea_align_gn_ms_r101_fpn_4gpu_2x)
- 按ctrl进去的函数,和执行的函数不一致。可以忽略。
- 没有用validate_per_epoch_single_class.py
- 实验数据分析
- 利用water-Net(DUIENet)对水下图片数据进行增强
- 论文解读:https://editor.csdn.net/md/?articleId=105156527
- 数据集效果对比
- 在验证集上的实验结果:
- 提交测试的实验结果:
- 加入test2kimg进行验证+再训练+再验证+测试
- train_ep12_+train_all_ep2+val_test2kimg_ep2
- 采用water-Net增强的结果:不work,进一步说明了人眼和机器对图片的感觉是不一样的,人眼觉得清晰,机器不一定觉得清晰,人眼好分辨,机器不一定就好分辨。
- 验证集可视化及指标分析:
- 指标来源:
- 指标分析:
- 图像尺寸分析:
- 下一步工作:
- 问题
- 选epoch11再跑train_all比单独跑val要好一点
- final_exp
- config:lr 01 [(4096, 800), (4096, 1200)] #train
- 在val上验证的结果
- htc_train_img_size_800_1200_lr01_ep13_val
- htc_train_img_size_800_1200_lr01_ep12_val.csv
- 跑完test提交后,评测结果比验证结果低0.4%,估计是受test集中2k图的影响较大,在2k图上的表现太差
- htc_train_img_size_800_1200_lr01_ep11_val
- htc_train_img_size_800_1200_lr01_ep10_val
- 在val_test2kimg上验证的结果(加入了2k图,与平台测试更接近):
- htc_train_img_size_800_1200_lr01_ep10_val_test2k
- htc_train_img_size_800_1200_lr01_ep11_val_test2k
- htc_train_img_size_800_1200_lr01_ep12_val_test2k
- htc_train_img_size_800_1200_lr01_ep13_val_test2k
- config: lr0.00125 [(4096, 600), (4096, 1000)] #train
- 在val_test2kimg上验证的结果
- htc_train_img_size_600_800_1000_lr00125_ep10_val_test2k
- htc_train_img_size_600_800_1000_lr00125_ep11_val_test2k
- htc_train_img_size_600_800_1000_lr00125_ep14_val_test2k
- 12,13epoch没有测,12有提交的跑好了,可以请人提交一下。
- config:
- htc_train_img_size_800_1200_lr005_ep10_val_test2k.csv
- htc_train_img_size_800_1200_lr005_ep11_val_test2k
- htc_train_img_size_800_1200_lr005_ep12_val_test2k
- config:train,train+val,lr0.005,第12epoch(train)+5个(train+val)
- htc_ZF101_train_all_val_test2kimg_ep1
- htc_ZF101_train_all_val_test2kimg_ep2
- htc_ZF101_train_all_val_test2kimg_ep3
- htc_ZF101_train_all_val_test2kimg_ep4
- config (baseline)
- htc_ZF101_train_lr005_val_test2kimg_ep10
- htc_ZF101_train_lr005_val_test2kimg_ep11
- htc_ZF101_train_lr005_val_test2kimg_ep12
- htc_ZF101_train_lr005_val_test2kimg_ep13
- htc_ZF101_train_lr005_val_test2kimg_ep14
- config 和上面一个config的test环境应该是一致的
- htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep12
- htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep13
- htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep14
- config
- htc_ZF101_0001_train_lr005_val_test2kimg_test_scale_6_8_10_ep11
- htc_ZF101_0001_train_lr005_val_test2kimg_test_scale_6_8_10_ep12
- config (train,lr01,ep12,+val_test2kimg,ep1-3 lr0.001)见过val_test2kimg
- htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep1
- htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep2
- htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep3
- 问题:
- 明天的工作:
- config:
- htc_ZF101_lr005_train_val_test2king_ep10
- htc_ZF101_lr005_train_val_test2king_ep11
- htc_ZF101_lr005_train_val_test2king_ep12
- htc_ZF101_lr005_train_val_test2king_ZFtest_size_ep12
- htc_ZF101_lr005_train_val_test2king_test_size800_ep12
- 结论:关于img_scale#test,最好的尺度是[(4096,600),(4096,800),(4096,1000)],单独用一个都相差比较大0.5%(800)-1%(1000)
- big_net_exp
- ga_faster_train_ep10_val_test2kimg
- faster_train_ep9_val_test2kimg
- cascade_train_ep9_val_test2kimg
- 发现cascade表现也比较好,因此,测试它其他几个epoch的表现:
- cascade_train_ep8_val_test2kimg
- cascade_train_ep9_val_test2kimg
- cascade_train_ep10_val_test2kimg
- cascade_train_ep11_val_test2kimg
- cascade_train_ep12_val_test2kimg
- cascade_train_ep13_val_test2kimg
- htcZF101_train_ep12_val_test2kimg
- 用目前表现最好的再训练val_test2kimg
- htc_WH101_val_test2kimg_lr0005_ep2_test
- htc_ZF101_train_all_test_ep4
- 模型融合
- 模型融合代码:
- wbf、nms、soft_nms、NMW都尝试了,只有nms可以提升点数,提升0.12%,因此采用nms进行融合。
- nms融合后的评测结果:
- htc单类别检测(有提升)
- 添加配置信息:
- underwater_scallop.py
- init.py
- config.py
- 关于验证的修改
- 扇贝单类别训练
- epoch2 (0.397974)
- epoch5 (0.411469)
- epoch5相比epoch2有进步,lyuan说要多训几个epoch,这相当于是重新训练,至少8个epoch
- result of epoch6-15
- 海胆单类别训练
- result of epoch 9-14
- 海参单类别训练
- 海星
- htc单类别检测最终评测结果(扇贝+海胆+海参+最强预测的海星因为(海星单类相比baseline提升不多,因此就直接用了最强海星预测))
- 赛后对单类别检测进行分析:
- 2k图和非2k图分开测:
- 用评测结果htc_train_ep11_train_all_ep2测非2k图,WH101测2k图
- 用htc_train_ep11_train_all_ep2测非2k图的理由
- 用WH101测2K图的理由:
- 比赛结束,结果
- A榜成绩可以排54/404,B榜排第32
- A榜最好成绩:
- B榜成绩
- 团队成员
- 感谢:
摘要
1、在真实海底图片数据中分辨出不同海产品(海参、海胆、扇贝、海星)的类别以及目标位置。使用
mmdetection 框架,分别测试了 Faster R-CNN、Cascade R-CNN、RetinaNet 几个现阶段主流的目
标检测网络模型,最终出于对目标检测精度的考虑,选择 Cascade R-CNN 作为 baseline。
2、对水下光学图像数据集进行分析,发现图片尺寸分布不均衡,通过将图片缩放到固定范围尺寸,使得模
型准确率提高了 4.7%。
3、 对测试集图片尺寸进行分析,结合检测的可视化结果,发现测试集中有2k图(尺寸为:20481536,25601440),训练好的模型在2k图上表现比较差,因此将测试集中53张2k图进行了标注,放入到训练集中进行补充训练,使得模型准确率提升了 0.8%。
4、对非2k图采用未见过2k图的模型进行检测,对2k图采用见过2k图的模型进行检测,是的模型准确率提升了0.4%。
5、项目评测采用 COCO mAP[@0.5:0.05:0.95] 指标进行计算,检测出的目标数对该指标有明显影响,因
此通过调整自信度阈值之后,使得模型的 mAP 提升了 0.5%。
6、采用单类别检测的方式,对检测结果较差的扇贝、海参、海胆进行单类别训练,最后进行融合,使得模型准确率提升了0.8%。
7、将Faster-RCNN、Cascade-RCNN、htc、单类别检测进行nms模型融合,使得模型准确率提升了0.2%
8、尝试用water-net进行水下图片增强,虽然人眼看增强后图片效果不错,而且在验证集上表现也有1%的提升,但是提交评测之后是掉点的,并不work。
9、尝试了soft_nms、wbf、NMW、nms四种模型融合的方式,只有nms是有提升的。
10、比赛结果:A榜54/404,B榜排第32,最终成绩以B榜为结果,前20名进入复赛,遗憾未能进入复赛,在调参方面还需要进一步总结经验。
比赛结束后
1、再看看mmdetection 的验证,应该是操作有问题
2、再看看分布式训练
3、看看如何用mmdetection搭自己的框架
4、伤碎了心,不再相信图像增强了!!!之后有空的话,可以可视化分析一下增强为啥不work,看了一下增强和htc框出来的框数目差不多,不知道是在模糊图上表现比较差还是在清晰图上表现比较差。进一步说明了人眼和机器对图片的感觉是不一样的,人眼觉得清晰,机器不一定觉得清晰,人眼好分辨,机器不一定就好分辨。
什么是backbone

创建underwater.py,并在//init//.py添加类名,使得自己的数据能够被关联上去



error:gt_masks_ann.append(ann[‘segmentation’]) keyError:‘sementation’
直接注释掉报错行就行,因为这需要mask信息,但是我们是没有mask信息,我们不需要mask
不然会出这样的问题:


修改config.py
修改train.py,添加–load_from


权重是从哪里读取。

num_classes=5 #类别数4加1(背景)
注意cascade网络结果是3个景象的resNet,所以需要修改多个地方

修改dataset_type,以及data_root

修改数据集的路径

imgs_per_gpu=2, 每张GPU同时跑几张图片,越大越好,但受限于显存大小
workers_per_gpu=2,每张GPU的线程数,单卡时设为0才能跑起来


如果出现CUDA out of memory 则把imgs_per_gpu改小一点
修改epoch数,跑多少个epoch

CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 使得程序可以看到0,1,2,3,4,5,6,7号GPU,但需要在train.py中把–gpus设为8,才会8块都用上,若是–gpus为1,则即使看到了8块卡也只会使用1块卡。

raise AssertionError(“Invalid device id”)
AssertionError: Invalid device id
若是CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 数量少于train.py中的gpus数,则会报下面这个错。。

写train.sh脚本方便启动train.py,写好多条命令,多个网络一个一个来跑 ''是换行符

在Windows上的pycharm写的sh在linux上运行不了,估计是因为文档格式不一致导致的,解决办法:用MobaXterm连到linux上进行编辑,就可以运行。

在这里面写的就可以运行。

要下载模型,就把pretrained设为None
因为我们下的那个权重里面有预训练模型
![]()

因为我们把class_num从81(coco数据集的类别数是80+1(背景))改为了5,所以会有size mismatch 在bbox_head 的weight和bias上。
cascade有3个镜像的backbone,所以共有6个size mismatch
size mismatch for bbox_head.0.fc_cls.weight: copying a param with shape torch.Size([81, 1024]) from checkpoint, the shape in current model is torch.Size([5, 1024]).
size mismatch for bbox_head.0.fc_cls.bias: copying a param with shape torch.Size([81]) from checkpoint, the shape in current model is torch.Size([5]).

在pycharm再添加一个local命令端
此方法linux下可行,windows下不行,因为windows下没有ssh,想办法解决额,但按博客做了没能解决。

Windows下可以用以下办法:

conda activate open-mmlab 不成功,因为lyuan的conda版本比较老(或路径没导入),要用source activate open-mmlab

没有找到完全对应的config.py,但是可以训起来.

模型训练完后,生成.csv文件
test的时候,通常用soft_nms,max_per_img=200

![]()
参考:https://blog.csdn.net/yuanlulu/article/details/89762861

scp 前者 后者 #本地linux和服务器之间传送文件,前者传后者,注意服务器端加ip的写法

本地pycharm新添加一个连接服务器的terminal
两种方法:
ssh [email protected]


def parse_args()如何写


ModuleNotFoundError: No module named ‘mmdet’ #没有激活open-mmlab环境

训练时用train_pipeline,测试时用test_pipeline,否则会报KeyError: ‘ann_info’

batch_size=imgs_per_gpu

软连接 :ln -s /home/lyuan/pycharm_code/mmdetection_4-4/exp exp

实验期间,因为修改代码,导致出现了修复不了的bug,重新装了mmdetection
gcc编译器要和cuda版本对应上:
cuda 9.0需要gcc编译器不超过6.0
cuda10.0则gcc版本可以超过
在.out文件中可以看版本信息

DataLoader worker (pid XXXX) is killed by signal: Bus error(Pytorch多workers读取Data Loader)

raise Exception()的用法

bug
raise NotImplementedError (infer_test_to_csv.py fovea_align_gn_ms_r101_fpn_4gpu_2x)


fovea_align_gn_ms_r101_fpn_4gpu_2x不能进行多尺度test,或者单尺度下flip=True,都会报这个错
按ctrl进去的函数,和执行的函数不一致。可以忽略。

没有用validate_per_epoch_single_class.py

因为inference.py中class_names得是列表或者元组才行

因此修改了validate_per_epoch_single_class.py为

原validate_per_epoch.py为:因为是多类,所以model.CLASSES直接返回的是一个列表

实验数据分析
利用water-Net(DUIENet)对水下图片数据进行增强
论文解读:https://editor.csdn.net/md/?articleId=105156527
这是一篇发布在IEEE TRANSACTIONS ON IMAGE PROCESSING 2019
数据集效果对比
原始图片越清晰,增强之后,人眼觉得也越好,但若是原始图片不清晰,增强效果就比较差。
原始的测试集:

增强后的测试集:




在验证集上的实验结果:
同模型,同配置,同预训练权重下,选取epoch12(在验证集上表现最好的epoch)进行,评测,采用water-Net增强后的结果要比不增强的效果好0.9%
原始数据训练:

增强数据训练:

提交测试的实验结果:
在没有将val集加入再训练的情况下,epoch12(在验证集上表现最好的epoch)跑测试集,增强后跑出来的结果掉点1.47%。
原始数据结果:

增强数据结果:

在epoch12的基础上,将训练集+验证集再训练5个epoch的情况下,epoch2跑测试集,增强后也是掉点,掉1.7%
原始数据结果:

增强数据结果:

加入test2kimg进行验证+再训练+再验证+测试
config:
train
epoch12:0.465
与之前的未加入test2kimg的验证结果(0.4954)相差较大,怀疑是在2k图上表现不好。
train_ep12_+train_all_ep2+val_test2kimg_ep2
验证集val_test2kimg上的结果:

在验证集上结果很好,还很开心,结果跑了测试一提交:
enhance_htc_train_all_ep2_val_test2kimg_lr0005_epoch_2_test

epoch4:

epoch5:
![]()
epoch7:
![]()
伤碎了心,不再相信图像增强了!!!之后有空的话,可以可视化分析一下增强为啥不work
采用water-Net增强的结果:不work,进一步说明了人眼和机器对图片的感觉是不一样的,人眼觉得清晰,机器不一定觉得清晰,人眼好分辨,机器不一定就好分辨。
验证集可视化及指标分析:
置信度阈值为0.3:
红框为ground truth,绿框为detection result


但提交的test都是置信度阈值为0.0001的(0.0001是能选的最低的阈值了,还可以用0.000001,但分数提高的不多,只有0.0003%个点),因为框越多分数越高,高1.5~2%个点

分析框多,分高的原因:map是以面积大小进行衡量的,虽然阈值设得很低会导致precision降低,但会使得recall尾巴拉得很长(漏检比较少),因此整体面积更大。

指标来源:


这两个都是自己写的
误检率=1-precision
漏检率=1-recall

指标分析:
原始数据的结果,epoch12在验证集上的评测结果:
置信度阈值取0.0001:

观察在验证集上的评测结果可以发现:
1、某个类别漏检率越低,该类别的ap就越高;海参的漏检率是最高的,因此它的ap要比其他三类低;
2、漏检对mAP的影响要比误检对mAP的影响要大;原因在上面分析过,框多分高
3、IOU增大,漏检率和误检率都在增大,ap在减小。
海参误检率和漏检率高的原因分析:
1、训练集中各个类别数量分布不均衡,海参的数量是最少的。
2、人眼来看,海参的特征容易和水草混在一起。



海胆的话,容易和石头中间的黑洞混在一起:

想到的降低海参漏检率的方法:
1、训练一个单类别检测器,检测海参,从epoch10开始训练(海参数据量比较少,从预训练权重开始训的话,怕过拟合),只检测海参这一个类别。
不知道还有什么可以降低漏检的方法,和老师,师兄讨论一下,
图像尺寸分析:
1.训练集56%是720405的小图,测试集81%是38402160的大图;
2、测试集中有2.62%的20481536的图片和4%的25601440的图片,这两个尺寸的图片训练集上都没有;根据师兄的分析,跑出来的模型在这个两个尺寸的图片上表现比较差。
训练集图像尺寸分布:

测试集尺寸分布:

配置文件中对图片大小进行的处理:
训练时,对输入图片尺寸进行了缩小处理:源码中,4096没有作用,把高缩小到600至1000的范围,保持纵横比

测试时,对输入图片尺寸进行了缩小处理,并且是3个尺度上test:600,800,1000,

下一步工作:
1、调整输入图片尺寸和学习率;弄清楚学习率到底该设多少合适;后面得在处理一下分布式训练时报的错。
2、将test的50张2k图和val,放入训练两个epoch,第一缩小10倍,第二个再缩小十倍,以及测试train+val+test2k,训练2个epoch
4、模型融合,其他几个大的网络也要重头开始训练,尺寸缩放和学习率可以调一调。
5、尝试2k图用跳出来的模型跑,非2k图用原来的老模型+train跑
4、如果学习率跳出来好的话,可以再试试water-net增强的方法。
5、img label、wnd、pytorch、
问题
6、mmdtection (4096,600),(4096,1000)只有600,1000起作用,看一下源码
learning rate小,gpu显存占用小?

选epoch11再跑train_all比单独跑val要好一点
这是跑train_all的结果:

这是单独跑val的结果

final_exp
config:lr 01 [(4096, 800), (4096, 1200)] #train
train,lr01,14个epoch #掉点0.17
img_scale=[(4096, 800), (4096, 1200)] #train
img_scale=[(4096,1000)] #test
在val上验证的结果
htc_train_img_size_800_1200_lr01_ep13_val

htc_train_img_size_800_1200_lr01_ep12_val.csv
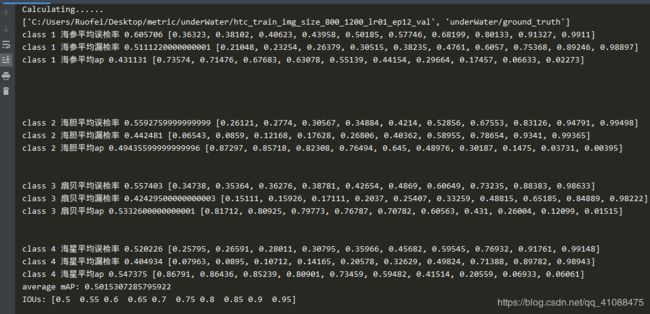

跑完test提交后,评测结果比验证结果低0.4%,估计是受test集中2k图的影响较大,在2k图上的表现太差
htc_train_img_size_800_1200_lr01_ep11_val

htc_train_img_size_800_1200_lr01_ep10_val

在val_test2kimg上验证的结果(加入了2k图,与平台测试更接近):
train,lr01,14个epoch #掉点1.7
img_scale=[(4096, 800), (4096, 1200)] #train
img_scale=[(4096,1000)] #test
htc_train_img_size_800_1200_lr01_ep10_val_test2k

htc_train_img_size_800_1200_lr01_ep11_val_test2k

htc_train_img_size_800_1200_lr01_ep12_val_test2k

在验证集中加入了53张2k的图片,验证的结果就更接近评测结果了。评测结果≈验证结果+0.14
htc_train_img_size_800_1200_lr01_ep13_val_test2k

config: lr0.00125 [(4096, 600), (4096, 1000)] #train
train,lr0.00125,14个epoch :掉点4
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,600),(4096,800),(4096,1000)] #test
在val_test2kimg上验证的结果
htc_train_img_size_600_800_1000_lr00125_ep10_val_test2k

htc_train_img_size_600_800_1000_lr00125_ep11_val_test2k

htc_train_img_size_600_800_1000_lr00125_ep14_val_test2k

12,13epoch没有测,12有提交的跑好了,可以请人提交一下。
config:
train,lr0.005,14个epoch :
img_scale=[(4096, 800), (4096, 1200)] #train
img_scale=[(4096,1000)] #test
htc_train_img_size_800_1200_lr005_ep10_val_test2k.csv

htc_train_img_size_800_1200_lr005_ep11_val_test2k

htc_train_img_size_800_1200_lr005_ep12_val_test2k


config:train,train+val,lr0.005,第12epoch(train)+5个(train+val)
train,train+val,lr0.005,第12epoch(train)+5个(train+val) :
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,1000)] #test
htc_ZF101_train_all_val_test2kimg_ep1

htc_ZF101_train_all_val_test2kimg_ep2

htc_ZF101_train_all_val_test2kimg_ep3

htc_ZF101_train_all_val_test2kimg_ep4
比 ep2,ep3都要高,怀疑过拟合,因为这个是见过验证集的。

config (baseline)
数据路径:/home/lyuan/pycharm_code/mmdetection/exp/htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101
train,lr0.005
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,600),(4096,800),(4096,1000)] #test
htc_ZF101_train_lr005_val_test2kimg_ep10

htc_ZF101_train_lr005_val_test2kimg_ep11
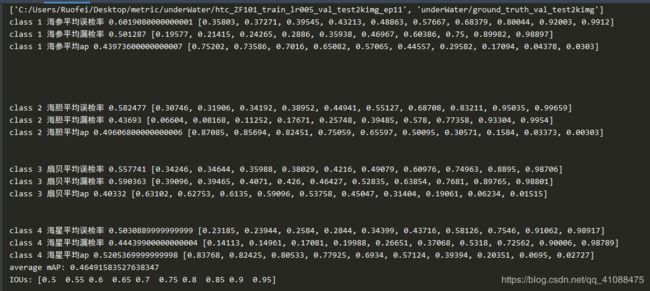
htc_ZF101_train_lr005_val_test2kimg_ep12

htc_ZF101_train_lr005_val_test2kimg_ep13

htc_ZF101_train_lr005_val_test2kimg_ep14

config 和上面一个config的test环境应该是一致的
数据路径:/home/lyuan/pycharm_code/mmdetection/exp/htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101
train,lr0.005
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,600),(4096,800),(4096,1000)] #test
htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep12

htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep13

htc_ZF101_train_lr005_val_test2kimg_test_scale_6_8_10_ep14

config
htc_ZF101_0001_train_lr005 :应和上面那个config没什么区别,0001是指置信度阈值,但置信度阈值对训练没有影响,而且我看了log文件,二者的置信度阈值应该是相等的。
train,lr0.005
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,600),(4096,800),(4096,1000)] #test
htc_ZF101_0001_train_lr005_val_test2kimg_test_scale_6_8_10_ep11

htc_ZF101_0001_train_lr005_val_test2kimg_test_scale_6_8_10_ep12

== 结论 == htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101和htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101_0001二者果然是一样的。
config (train,lr01,ep12,+val_test2kimg,ep1-3 lr0.001)见过val_test2kimg
train,lr01,ep12,+val_test2kimg,ep1 lr0.001
img_scale=[(4096, 800), (4096, 1200)] #train
img_scale=[(4096,1000)] #test
htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep1

htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep2

htc_train_img_size_800_1200_lr01_ep13_val_test2kimg_lr001_ep1_3_val_test2kimg_ep3
可能过拟合了,但得提交了才能知道

问题:
1、在val集上,海参漏检最高的,在vla_test2kimg,扇贝漏检最高。
明天的工作:
1、htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101_ep12_val_test2kimg_lr0005_ep1_3_test_ep1再跑几个epoch,看看上限在哪?学习率再缩小10倍
2、用跑得最好的网络跑vla_test2kimg
config:
ZF101 Tesla P100
train,lr005
img_scale=[(4096, 600), (4096, 1000)] #train
img_scale=[(4096,1000)] #test
htc_ZF101_lr005_train_val_test2king_ep10

htc_ZF101_lr005_train_val_test2king_ep11

htc_ZF101_lr005_train_val_test2king_ep12
img_scale=[(4096,1000)] #test

htc_ZF101_lr005_train_val_test2king_ZFtest_size_ep12
img_scale=[(4096,600),(4096,800),(4096,1000)] #test

htc_ZF101_lr005_train_val_test2king_test_size800_ep12
img_scale=[(4096,800)] #test

结论:关于img_scale#test,最好的尺度是[(4096,600),(4096,800),(4096,1000)],单独用一个都相差比较大0.5%(800)-1%(1000)
big_net_exp
注意:这四个网路跑出来的框数和大小都不一样,排名按时间顺序,越在前的跑得越快
ga_faster_train_ep10_val_test2kimg
老验证集,没有test2kimg
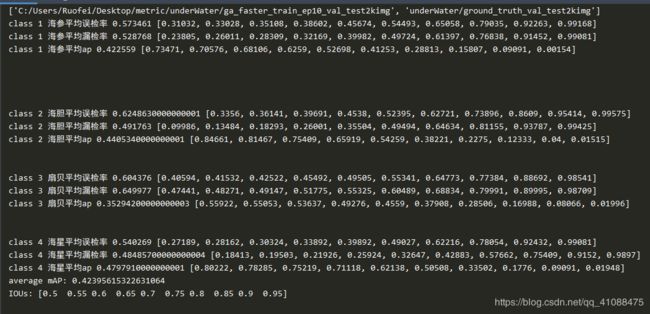
faster_train_ep9_val_test2kimg
老验证集,没有test2kimg
![]()

cascade_train_ep9_val_test2kimg
老验证集,没有test2kimg
![]()

发现cascade表现也比较好,因此,测试它其他几个epoch的表现:
cascade_train_ep8_val_test2kimg

cascade_train_ep9_val_test2kimg
cascade_train_ep10_val_test2kimg
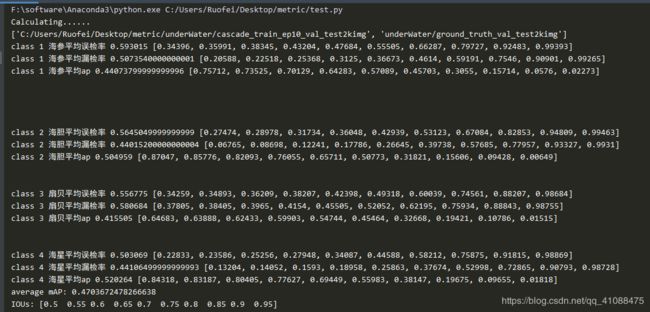
cascade_train_ep11_val_test2kimg

cascade_train_ep12_val_test2kimg

cascade_train_ep13_val_test2kimg

htcZF101_train_ep12_val_test2kimg
老验证集,没有test2kimg
![]()

用目前表现最好的再训练val_test2kimg
htc_WH101_val_test2kimg_lr0005_ep2_test
config:
htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101_ep11+htc_dconv_c3-c5_mstrain_400_1400_x101_64x4d_fpn_ZF101_train_all_ep2+htc_WH101_val_test2kimg_lr0005_ep2

htc_WH101(ZF101_train_epoch11+train_all_epoch2+val_test2kimg_epoch3)

htc_ZF101_train_all_test_ep4
WH48.1那个版本(htc_ZF101_train_all_ep2)中ep2是最强的,其他都没有他强。




模型融合
模型融合代码:
论文:https://arxiv.org/abs/1910.13302
源码:https://github.com/ZFTurbo/Weighted-Boxes-Fusion
wbf、nms、soft_nms、NMW都尝试了,只有nms可以提升点数,提升0.12%,因此采用nms进行融合。
融合所用的单模,前面的数字代表提交后的评测结果

nms融合后的评测结果:

htc单类别检测(有提升)
添加配置信息:
underwater_scallop.py

init.py

config.py
cascade 3处num_classes=2


关于验证的修改
因为inference.py中class_names得是列表或者元组才行
因此修改了validate_per_epoch_single_class.py为
原validate_per_epoch.py为:因为是多类,所以model.CLASSES直接返回的是一个列表
扇贝单类别训练
epoch2 (0.397974)

epoch5 (0.411469)
用ground_truth_val_test2kimg

用grouond_truth_val_testikimg_scallop 二者的计算结果都样。

epoch5相比epoch2有进步,lyuan说要多训几个epoch,这相当于是重新训练,至少8个epoch
result of epoch6-15
未见过验证集

扇贝baseline上的表现:

海胆单类别训练
未见过验证集
result of epoch 9-14

海胆在baseline上的表现

海参单类别训练

海参在baseline上的表现

海星


htc单类别检测最终评测结果(扇贝+海胆+海参+最强预测的海星因为(海星单类相比baseline提升不多,因此就直接用了最强海星预测))

赛后对单类别检测进行分析:
单类别检测非2k图的效果应该是最好的,但没有提交测试,因为这个单类别最后的综合虽然每个类别都跑了val_test2kimg,但是val_test2kimg中的图片数比较少,跑了没多大的意义,没有时间在A榜提交用单类别测非2k图+wh101测2k图,估计效果会不错,所以以后比赛,若是某类别比较差的可以考虑使用单类别检测,提高某一个类别的mAP。
2k图和非2k图分开测:
用评测结果htc_train_ep11_train_all_ep2测非2k图,WH101测2k图
用htc_train_ep12_train_all_ep2测非2k图效果应该更好,主要是时间太紧了,没办法在test了,就用了之前的htc_train_all_ep11的结果

用htc_train_ep11_train_all_ep2测非2k图的理由

未加2K图的验证,用htc_train_ep12_train_all_ep2效果更好。因为上图虽然train_ep11_train_all_ep2_val比train_ep12_train_all_ep2_val好,但是怀疑过拟合,因为train_all是见过验证集的,而在没见过验证集的train_ep11(0.4649)和train_ep12(0.4663)中,train_ep12的表现要更好。但这也不能完全确定,因为train_ep12_train_all_ep2_val(lr:0.0005)和train_ep11_train_all_ep2_val(lr0.0001)训练train_all的时候学习率不一样,所以如果提交次数多的话,两个都提交一下。
结果:ep11(0.4709)训练出来用来测非2k图的和用ep12(0.4703)用来测2k图的提交后在B榜结果相差不大。

用WH101测2K图的理由:
在2k图上我们调的WH101(train_ep11+train_all_ep2+val_test2kimg_ep2)效果比train_ep12+train_all_test2kimg_ep2要更好。

比赛结束,结果
A榜成绩可以排54/404,B榜排第32
A榜最好成绩:
不知不觉被封了,所以排行榜上没有


B榜成绩
用htc_train_lr0.005_epoch11_ep_train_all_lr0.001_ep2检测非2k图+htc_train_lr0.005_epoch11_ep_train_all_lr0.001_ep2_val_test2kimg_lr0.0005_ep2检测2k图。
在这里插入图片描述
团队成员

感谢:
感谢斩风老哥分享的baseline:https://github.com/zhengye1995/underwater-objection-detection
从中学到不少东西,没跑出斩风老哥baseline的结果48.7,自己跑出来是48.1,应该是操作有问题;
感谢导师和师兄提供的帮助和指导;
感谢团队成员lyuan的合作;