NLP中的注意力机制
什么是注意力机制
- 从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上
注意力机制的计算过程
第一步:根据Query和key计算权重系数,首先计算Query与key计算相似性或相关性,常用的相似性计算方式:
点积:
![]()
cos相似度:用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小
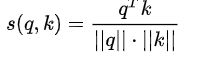
拼接的方式:将两个向量拼接起来,然后利用一个可以学习的权重 w求内积得到相似度
![]()
将相似度计算得到的分值,通过softmax进行归一化处理,得到所有元素权重之和为1的概率分布
第二步:根据权重系数与Value的计算得到针对Query的Attention数值
拼接的方式代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self,query_size,key_size,value_1_size,value_2_size,output_size):
super().__init__()
self.query_size=query_size
self.key_size=key_size
self.value_1_size=value_1_size
self.value_2_size=value_2_size
self.output_size=output_size
self.attn=nn.Linear(self.query_size+self.key_size,value_1_size)
self.attn_combine=nn.Linear(self.query_size+value_2_size,output_size)
def forward(self,Query,Key,Value):
# 将Query与key进行拼接,softmax输出
attn_weights=F.softmax(self.attn(torch.cat((Query[0],key[0]),1)),dim=1)
#输出结果与encode的output进行bmm运算
attn_applied=torch.bmm(attn_weights.unsqueeze(0),Value)
# 之后进行第二步, 通过取[0]是用来降维 需要将Query与第一步的计算结果再进行拼接
output=torch.cat((Query[0],attn_applied[0]),1)
output=self.attn_combine(output).unsqueeze(0)
return output,attn_weights
query_size = 16
key_size = 16
value_1_size = 32
value_2_size = 64
output_size = 64
attn=Attn(query_size,key_size,value_1_size,value_2_size,output_size)
Query=torch.randn(1,1,32)
key=torch.randn(1,1,32)
Value=torch.randn(1,32,64)
output,attn_weights=attn(Query,key,Value)
print(output)
print("----------------------")
print(attn_weights)
计算结果
tensor([[[ 0.3433, 0.3704, 0.5602, 0.2124, 0.1733, -0.1546, -0.0868,
-0.2591, -0.2228, -0.5895, 0.3706, 0.3475, -0.1789, -0.5224,
0.5093, 0.0728, -0.4964, 0.2349, 0.2929, -0.3290, -0.2352,
0.3549, 0.7888, 0.2731, -0.5024, -0.0791, -0.4329, -0.4469,
0.2723, -0.3557, -0.4669, -0.1600, 0.4213, -0.3603, 0.1211,
0.1672, 0.3749, 0.1782, -0.3228, -0.0130, 0.9942, 0.6744,
-0.0406, 0.0243, 0.3250, 0.1717, 0.4306, 0.0465, -0.4716,
0.7407, -0.6401, -0.3244, 0.1458, 0.0838, -0.1512, -0.2992,
-0.0446, 0.0691, 0.0743, -0.0399, -0.2815, 0.1828, -0.6082,
0.1174]]], grad_fn=<UnsqueezeBackward0>)
----------------------
tensor([[0.0385, 0.0480, 0.0089, 0.0096, 0.0132, 0.0802, 0.0262, 0.0347, 0.0210,
0.0246, 0.0162, 0.0238, 0.0474, 0.0308, 0.0175, 0.0220, 0.0505, 0.0124,
0.0886, 0.0550, 0.0191, 0.0201, 0.0612, 0.0210, 0.0302, 0.0297, 0.0129,
0.0220, 0.0144, 0.0693, 0.0123, 0.0189]], grad_fn=<SoftmaxBackward>)