AI黑科技:Deepfacelab(人工智能换脸合成技术)的简介、安装、使用方法之详细攻略
AI黑科技:Deepfacelab(人工智能换脸合成技术)的简介、安装、使用方法之详细攻略
目录
Deepfacelab的简介
Deepfacelab的安装
Deepfacelab的使用方法
1、文件及思路理解
2、换脸操作流程
3、FAQ
参考文章
【停更】Deepfacelab 新手教程
Deepfacelab的简介

DeepFaceLab是一个使用运行在NVIDIA / AMD / IntelHD图形加速器上的神经网络替换视频中的面部的程序。DeepFaceLab是一种利用机器学习来取代视频中的人脸的工具。包括预构建的可工作的独立Windows7,8,10二进制文件(look readme.md)。
总结:DeepfaceLab虽然之后命令行界面,但是其也有着不可替代的优点:它对于显卡的要求并不如其他那么高,使用2G显存的显卡即可流畅运转。操作界面有点不友好,但是训练出来效果却是非常不错。对于DeepfaceLab来说,Openfaceswap拥有GUI,保证了使用的简洁,也使得新手更容易上手。但是相对的,其也存在着出错之后难以解决的问题。DeepfaceLab软件适合编程能力较弱,追求高效率的用户。
相关文章
GitHub地址:https://github.com/iperov/DeepFaceLab#deepfacelab-is-a-tool-that-utilizes-machine-learning-to-replace-faces-in-videos
DeepFakes中文网
案例应用
【AI换脸】徐锦江换脸海王、雷神
Deepfacelab的安装
1、硬件要求
系统:Win7, Win10
显卡:GTX 1060以上效果较好,需要安装windows 版本的 VS2015,CUDA9.0和CuDNN7.0.5
优点:基于Faceswap定制的bat处理批版本,硬件要求低,2G显存就可以跑,支持手动截取人脸、集成所需要的素材和库文件,功能强大
缺点:复杂、处理批较多,脸部数据不能和其他deepfakes通用,需要重新截取
总结:适合有一定编程基础、追求效率高的用户
2、软件版本
Prebuilt Windows Releases
Windows builds with all dependencies included are released regularly. Only the NVIDIA GeForce display driver needs to be installed. Prebuilt DeepFaceLab, including GPU and CPU versions, can be downloaded from
https://drive.google.com/open?id=1BCFK_L7lPNwMbEQ_kFPqPpDdFEOd_Dci
Available builds:
DeepFaceLabCUDA9.2SSE - for NVIDIA cards up to GTX1080 and any 64-bit CPU
DeepFaceLabCUDA10.1AVX - for NVIDIA cards up to RTX and CPU with AVX instructions support
DeepFaceLabOpenCLSSE - for AMD/IntelHD cards and any 64-bit CPU
DeepFaceLabCUDA10.1AVX_build_06_20_2019.exe:适用于高达RTX的NVIDIA显卡和支持AVX指令的处理器。
DeepFaceLabCUDA9.2SSE_build_06_20_2019.exe: 适用于GTX1080和任何64位处理器的NVIDIA显卡。
DeepFaceLabCUDA10.1SSE_build_06_20_2019.exe: 适用于GTX1080和任何64位处理器的NVIDIA显卡。
DeepFaceLabOpenCLSSE_build_06_20_2019.exe:适用于AMD显卡和任何64位处理器。
下载时候有多个版本,一个是CPU版,一个是正常版,一般情况用NVIDIA显卡玩不需要下载CPU版本,根据自己电脑算力需求对应下载。一般情况下,台式机游戏级别配置的CPU的速度是GPU的1/10左右,这大概是个平均值。
解压开你会发现Deepfacelab文件夹内有两个文件夹,和一堆bat批处理指令。
英文版

中文版
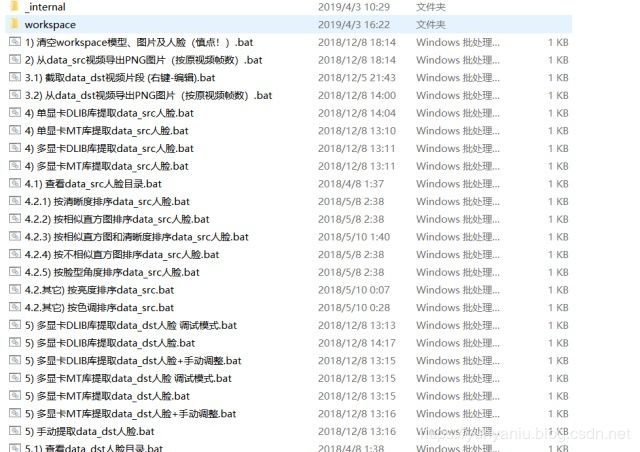


上图这张图是大概2018年6月的版本的列表,新版和旧版总体bat的功能不会差太多(2019/1/3作者更新了1个新算法,目前群内大神测试没太大用)。另外你如果玩熟练了你可以自己弄一些拿到前面来,这样会很方便。记住,bat 批处理文件是可以修改的,文件夹里的只是送你的案例而已

Deepfacelab的使用方法
1、文件及思路理解
所有软件对应的两边素材:
- A即DST 就是原版的视频素材,就是不要脸要身体的素材
- B即SRC 就是要使用到的脸的素材
把两边素材称为A和B的软件,一般都可以互换方向,但是总体操作都是B脸放A上,SRC脸放DST上。DST和SRC素材都可以是图片或者视频。换脸软件的操作是通过SRC脸图集,运算出MDOEL,然后放到DST序列图上,最后把DST序列图连接为视频。
把两边素材称为A和B的软件,一般都可以互换方向,但是总体操作都是B脸放A上,SRC脸放DST上。 AB的软件一般都可以互换方向,但是总体操作都是B脸放A上,SRC脸放DST上,DST和SRC素材都可以是图片或者视频。换脸软件的操作是通过SRC脸图集,运算出MDOEL,然后放到DST序列图上,最后把DST序列图连接为视频。
2、换脸操作流程
- 【手动】把DST视频放到“workspace”文件夹下,并且命名为“data_dst”(后缀名和格式一般不用管)
- 【手动】把SRC素材(明星照片,一般需要700~1500张)放到“workspace\data_src”下
- 【BAT】分解DST视频为图片(需要全帧提取,即Full FPS),BAT序号3.2 你会看到“workspace\data_dst”下有分解出来的图片
- 【BAT】识别DST素材的脸部图片,BAT序号5 有DLIB和MT两种分解方式,一般情况建议DLIB,具体差别什么自己摸索,这够说一篇文章的了,网上可以查
- 【BAT】识别SRC素材的脸部图片,BAT序号4 同上
- 【手动】第4步和第5步分解的人脸素材在“workspace\data_dst\aligned”和“workspace\data_src\aligned”内,你需要把这些人脸不正确识别的内容删除,否则影响MODEL训练结果,如果脸图特别小,或者翻转了,那么基本判定为识别错误,但是要说明的是,DST脸超出画面的半张脸需要留着不要删除,SRC脸超出画面基本没用,直接删除吧。
删除SRC错误脸图前可以使用BAT4.2系列的排序,直方图排序和人脸朝向排序可以较为方便地找出错误人脸,这属于进阶内容,具体不给教程,有需要自己Baidu翻译一下。 - 【BAT】现在你已经有DST的序列帧(图片)素材和SRC的脸部(图片)素材了,你需要运行MODEL训练,BAT序号6 一样也是有好多种MODEL,目前建议新手直接跑H128的MODEL(除非你的显卡比较差,那就跑H64)其他MDOEL算法请看GitHub上的介绍。跑MODEL是可以中断的,在预览界面按回车键,软件会自动保存当前进度,MDOEL文件在“workspace\model”下,不同的MODEL不会重名,建议定期备份MODEL,并建议SRC专人专用MODEL。
- 【BAT】上面MODEL如果是第一次跑,可能需要10+小时才有合理的效果,结束训练后请运行MODEL导出合成图,BAT序号7 这里就根据你的MODEL类型来运行就好了。这里会出现一个问题就是软件会在DOS界面给你好多好多选项,请跳掉文章下面部分学习。
- 【BAT】导出图片后需要把图片转成视频,那么就运行 BAT序号8 就行了,根据你要的最终格式来定。
开始仔细讲解步骤8导出合成图的选项。所有选项直接按回车即使用标注的默认选项(default)
第一个问答是问你要哪个合成模式,可以理解为:普通、普通+直方图匹配、无缝(默认)、无缝+直方图匹配。可能每个视频需要的效果都不一样,一般情况我个人建议用:普通。
第一个问答结束后后面有一堆问题,具体作者给了说明。
出来的图片位置在“workspace\data_dst\merged”
新手可以不调整这些参数,但不调整很可能出来结果不尽人意调整这个?恭喜你,你已经突破新手界限了,Deepfacelab的导出时候的参数调整能力比其他三款都要好。
不论哪款软件,流程结束后建议复制出并分类保留:SRC素材(随便是脸图还是原图)、MODEL(丢了就浪费10小时了)。
3、FAQ
(1)、人脸素材需要多少?
DST:尽量不要少,因为它是有限的且需要被替换的素材
SRC:根据各软件的脸图筛选规则和网上大神的建议,总体来说,SRC脸图最好是大概700~3999的数量,像Deepfacelab的作者,他就认为1500张够了。对于SRC,各种角度、各种表情、各种光照下的内容越多越好,很接近的素材没有用,会增加训练负担。
(2)、手动对齐识别人脸模式如何使用?
回车键:应用当前选择区域并跳转到下一个未识别到人脸的帧
空格键:跳转到下一个未识别到人脸的帧
鼠标滚轮:识别区域框,上滚放大下滚缩小
逗号和句号(要把输入法切换到英文):上一帧下一帧
Q:跳过该模式
老实说,这个功能极其难用,画面还放得死大……
(3)、MODEL是个什么东西?
MODEL是根据各种线条或其他奇怪的数据经过人工智能呈现的随机产生的假数据,就像PS填充里的“智能识别”
你可以从 https://affinelayer.com/pixsrv/ 这个网站里体验一下什么叫MODEL造假
(4)、MODEL使用哪种算法好?
各有千秋,一般Deepfacelab使用H128就好了,其他算法可以看官方在GitHub上写的介绍:https://github.com/iperov/DeepFaceLab
(5)、Batch Size是什么?要设置多大?
Batch Size的意思大概就是一批训练多少个图片素材,一般设置为2的倍数。数字越大越需要更多显存,但是由于处理内容更多,迭代频率会降低。一般情况在Deepfacelab中,不需要手动设置,它会默认设置显卡适配的最大值。
根据网上的内容和本人实际测试,在我们这种64和128尺寸换脸的操作中,越大越好,因为最合理的值目前远超所有民用显卡可承受的范围。
新手建议自动或从大的数值减少直到能够正常运行(比如128→64→32→16…),具体操作方法是在MODEL训练的BAT中添加一行:
@echo off
call _internal\setenv.bat
%PYTHON_EXECUTABLE% %OPENDEEPFACESWAP_ROOT%\main.py train ^
--training-data-src-dir %WORKSPACE%\data_src\aligned ^
--training-data-dst-dir %WORKSPACE%\data_dst\aligned ^
--model-dir %WORKSPACE%\model ^
--model H128
pause
上面是原版,需要加一行“–batch-size ?”并不要忘记上一行的“^”,如下:
@echo off
call _internal\setenv.bat
%PYTHON_EXECUTABLE% %OPENDEEPFACESWAP_ROOT%\main.py train ^
--training-data-src-dir %WORKSPACE%\data_src\aligned ^
--training-data-dst-dir %WORKSPACE%\data_dst\aligned ^
--model-dir %WORKSPACE%\model ^
--model H128 ^
--batch-size 4
pause(6)、MODEL训练过,还可以再次换素材使用吗?
换DST素材:
可以!而且非常建议重复使用。
新建的MODEL大概10小时以上会有较好的结果,之后换其他DST素材,仅需0.5~3小时就会有很好的结果了,前提是SRC素材不能换人。
换SRC素材,那么就需要考虑一下了:
第一种方案:MODEL重复用,不管换DST还是换SRC,就是所有人脸的内容都会被放进MODEL进行训练,结果是训练很快,但是越杂乱的训练后越觉得导出不太像SRC的脸。
第二种方案:新建MODEL重新来(也就是专人专MODEL)这种操作请先把MODEL剪切出去并文件夹分类,这种操作可以合成比较像SRC的情况,但是每次要重新10小时会很累。
第三种方案:结合前两种,先把MODEL练出轮廓后,再复制出来,每个MODEL每个SRC脸专用就好了。
参考文章:
Deepfacelab 新手教程