精心整理的8道Python面试题!是否难到你了
每年的3-4月份是跳槽的高峰期,无论是应聘Python web开发,爬虫工程师,或是数据分析,还是自动化运维,都涉及到一些基础的知识!我挑了一些Python的基础面试题,看看你能不能的答上来,也许面试的同学用的着!
NO.1
Python这么好
说说它的特性吧
关键特性
Python是一种解释型语言,这意味着,与C,C++不同,Python不需要在运行之前进行编译。它是边运行边解释。
Python是动态类型化的,这意味着当你声明它们或类似的东西时,你不需要声明变量的类型。你可以x=1 ,然后x="abc"没有错误。
Python非常适合面向对象编程,因为它允许定义类以及组合和继承。Python没有访问修饰符(如C ++的public,private).
在Python中函数是一等对象,这意味着它们可以在运行时动态创建,能赋值给变量或者作为参数传给函数,还能能作为函数的返回值
Python代码容易上手,开发速度很快,但运行速度通常比编译语言慢。幸运的是,Python允许包含基于C的扩展,所以瓶颈可以被优化掉,比如,numpy包就是一个很好的例子,它非常快,因为它所做的很多运算在底部都是用C编
写的!
在这里还是要推荐下我自己建的Python开发学习群:483546416,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2018最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴
NO.2
Python中的赋值
浅拷贝和深拷贝的区别
深浅拷贝区别
1).对象的赋值
Python中对象的赋值实际上是简单的对象引用也就是说,当你创建一个对象,然后把它复制给另一个变量的时候,Python并没有拷贝这个对象,而是拷贝了这个对象的引用。
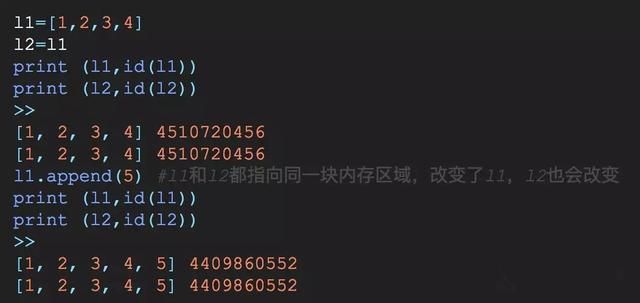
2).浅拷贝
一般使用copy.copy(),可以进行对象的浅拷贝.它复制了对象但对于对象中的元素,依然使用原始的引用.
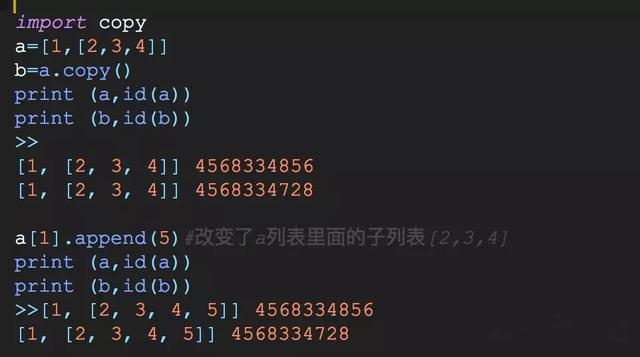
使用copy对a进行浅拷贝,b复制了a的对象,但是b里面的[2,3,4]和a里面的[2,3,4]其实都是指向同一块内存地址,所以改变了a[1]之后,b里面的b[1]也发生了改变!
3).深度拷贝
深度拷贝需要用copy.deepcopy()进行深拷贝。它会复制一个容器对象,以及它里面的所有元素(包含元素的子元素)
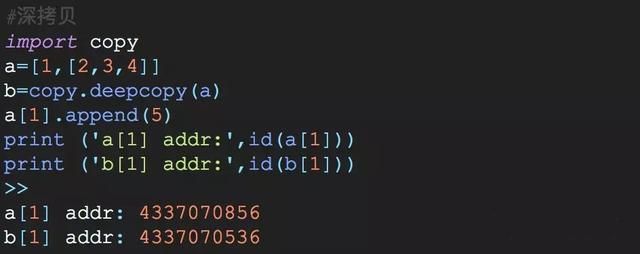
当对a列表进行深度拷贝之后,b复制了a的对象,但是b里面的[2,3,4]和a里面的[2,3,4]其实都是指向不同的内存地址.
a[1].append(5) print (a) print (b)>> [1, [2, 3, 4, 5]]#因为是深度拷贝,改变了a[1],b[1]内容不会改变 [1, [2, 3, 4]]
NO.3
Python中的==
和is的区别
==和is
Python中==和is的区别
is是判读对象标识符是否一致,而==是判读两个对象的内容是否相等!
x is y 相当于 id(x)==id(y)
==是检查两个对象的内容是否相等,会调用对象的内部__eq__().

NO.4
线程如何在Python
中实现
多线程问题
线程如何在Python中实现
Python有一个多线程包threading,可以使用多线程来加快你的代码。但是Python有一个叫做Global Interpreter Lock(GIL)的构造。GIL确保只有一个'线程'可以在任何时候执行。
线程获取GIL,做一些工作,然后将GIL传递到下一个线程。这种情况发生得非常快,所以对于人眼而言,它可能看起来像你的线程并行执行,但它们实际上只是轮流使用相同的CPU内核。因此GIL的存在使得Python中的多线程无法真正的利用多核的优势来提高性能。
对于IO密集型操作,在等待操作系统返回的时候会释放GIL;再比如爬虫因为有等待的服务器的响应时间,可以利用多线程来加速!但是对于CPU密集型操作,只能通过多进程Multiprocess来加速。
NO.5
Python中的
猴子补丁式啥
猴子补丁
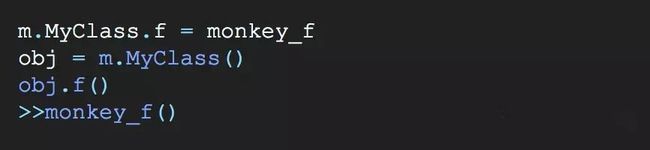
Python中的猴子补丁是什么?
考虑下面的例子:
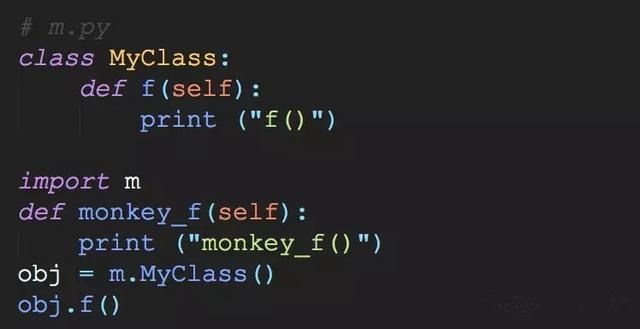
>>
f()
猴子补丁:
是一种非常Pythonic的用法,即函数在python中可以像使用变量一样对它进行赋值等操作,我们可以在运行时动态替换模块,俗称手法称为猴子补丁!我们通过对MyClass.f 重新赋值,动态的改变了输出的结果.
NO.6
Python中的
负数index
负值索引
Python中的负数index是用来做什么的?
Python中的序列是索引的,它由正数和负数组成。正的数字使用'0'作为第一个索引,'1'作为第二个索引。
负数的索引从'-1'开始,表示序列中的最后一个索引,'-2'作为倒数第二个索引,序列像正数一样向前。
负数索引也可以用来非常方便的切片,比如:
s='abcdedf'
print (s[1:-1])
>>bcded
NO.7
类里面的new
和init的区别
new/init区别
说说__new__和__init__的区别
__init__为初始化方法,而__new__方法才是是真正的构造函数。只有继承了object的新式类才有__new__.
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供,__new__必须要有返回值,返回实例化出来的实例。
__init__有一个参数self,就是这个__new__返回的实例, 先运行__new__ 然后才运行__init__.
__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值.
NO.8
Python中的
参数
*args和**kwargs
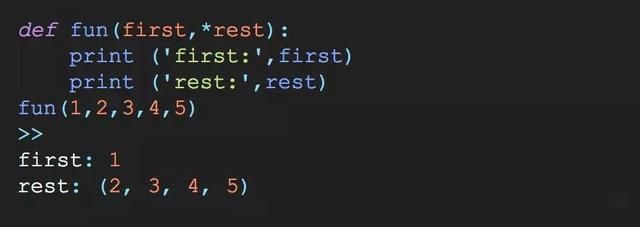
Python中的*args,**kwargs的用法
*args是可变参数,一般用来表示我们不能确定多少参数将被传递给函数,或者如果我们想用列表或元组的方式传递给函数.
**kwars是可变关键字参数,当我们不知道有多少关键字参数会传递给一个函数时,或者想把一个字典作为关键字参数时使用
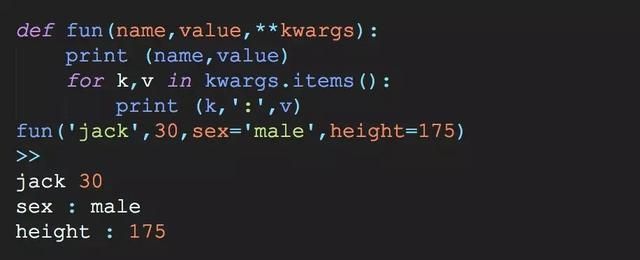
注:*args和**kwargs可以同时在函数的定义中,但是*args必须在**kwargs前面.
更多Python面试题,,私信回复:学习资料。与更多人一起学习Python。
很多人想要了解Python实现人脸识别,今天我们就来讲下
人脸识别,乍一听还是高大上的东西.
今天我们就分享下怎么玩?
不需要一大坨代码,只要你会装……包.
当然,我们的重点不是装包,归根结底,还是怎么玩.
Ok,那么,我们开始
一、需要安装什么?
1.OpenCV 一个图像处理的强大的包.官网 http://opencv.org/,最新的版本3.3.0
不需要最新的版本直接brew install opencv3,我这里装好是3.2.0的
如果需要最新的版本3.3.0的话,请按照这里安装 http://www.pyimagesearch.com/2016/12/19/install-opencv-3-on-macos-with-homebrew-the-easy-way/
2.Python2.7或者Python3.x
3.依赖包NumPY. 可以pip install numpy
4.依赖包face recognition.主角就是他了.pip install face recognition
注意事项参照地址 https://github.com/ageitgey/face_recognition
二、怎么玩
我们首先给定一张被照片

2.从摄像头捕捉的图像里获取检测出头像,跟上面的照片的图片进行对比.
先看下结果:

从截下来的图片来看. 我自己因为没有放图片上去进行识别,所以是unknown的. 手机上的图片被识别到了写上chu(名字) 标签.
代码:
import face_recognition import cv2 import time #获取摄像头video_capture = cv2.VideoCapture(0)# 加载图片obama_image = face_recognition.load_image_file("IMG_20170723_213850R.jpg") # 图片先识别一遍人脸,后面用来比较obama_face_encoding = face_recognition.face_encodings(obama_image)[0]# 初始化变量face_locations = [] face_encodings = [] face_names = [] process_this_frame = Truewhile True: # 从摄像头获取图像 ret, frame = video_capture.read() # 缩放1/4大小,方便快速处理 small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25) # 保证只处理一遍 if process_this_frame: #找出所有的人脸 face_locations = face_recognition.face_locations(small_frame) face_encodings = face_recognition.face_encodings(small_frame, face_locations) face_names = [] for face_encoding in face_encodings: # 判断是否匹配给定的人脸 match = face_recognition.compare_faces([obama_face_encoding], face_encoding) name = "Unknown" if match[0]: name = "CHU" face_names.append(name) process_this_frame = not process_this_frame # 把识别到和为识别到的人脸进行标记 for (top, right, bottom, left), name in zip(face_locations, face_names): # 原来是1/4的大小,现在放大4倍 top *= 4 right *= 4 bottom *= 4 left *= 4 # 给脸部画框 cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # 脸部下面显示标签 cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), 2) font = cv2.FONT_HERSHEY_DUPLEX cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.5, (255, 255, 255), 3) #识别到时候进行抓屏 for name in face_names: if name=="CHU": cv2.imwrite('img-%d.png'%int(time.time()), frame) # 显示加了头像框视频 cv2.imshow('Video', frame) # Hit 'q' on the keyboard to quit! if cv2.waitKey(1) & 0xFF == ord('q'): break# 释放摄像头句柄video_capture.release() cv2.destroyAllWindows()
如果我的分享对你有帮助,与你分享更多Python方面的知识。