Python爬虫的数据提取,一篇博客就搞定啦!
数据提取
目录
- 数据提取
- XPath语法和lxml模块
- XPath
- 什么是XPath
- XPath开发工具
- XPath语法
- 选取节点:
- 谓语:
- 通配符
- 选取多个路径:
- 运算符:
- 总结
- 使用方式
- 需要注意的知识点
- lxml库
- 基本使用:
- 从文件中读取html代码:
- 在使用lxml解析html代码时需要注意的点
- 在lxml中使用XPath语法:
- 练习:
- 总结
- lxml结合xpath注意事项:
- 实战:
- 使用requests和xpath爬取正在上映的豆瓣电影
- 电影天堂爬取2020新片精品
XPath语法和lxml模块
XPath
什么是XPath
xpath(XML Path Language) 是一门在XML和HTML文档中查找信息的语言,可以用来在XML和HTML文档中对元素和属性进行遍历
XPath开发工具
- Chrome插件XPath Helper。
- Firefox插件Try XPath。
XPath语法
选取节点:
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
| 表达式 | 描述 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | bookstore | 选取bookstore下所有的子节点 |
| / | 如果是在最前面,代表从根节点选取。否则选择某节点下的某个节点 | /bookstore | 选取根元素下所有的bookstore节点 |
| // | 从全局节点中选择节点,随便在哪个位置 | //book | 从全局节点中找到所有的book节点 |
| @ | 选取某个节点的属性 | //book[@price] | 选择所有拥有price属性的book节点 |
| . | 当前节点 | ./a | 选取当前节点下的a标签 |
谓语:
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 描述 |
|---|---|
| /bookstore/book[1] | 选取bookstore下的第一个子元素 |
| /bookstore/book[last()] | 选取bookstore下的倒数第二个book元素。 |
| bookstore/book[position()< 3] | 选取bookstore下前面两个子元素。 |
| //book[@price] | 选取所有拥有price属性的book元素 |
| //book[@price=10] | 选取所有属性price等于10的book元素 |
| //book[contains(@price,10)] | 模糊匹配,选取所有拥有price属性的,而且该price属性值包含10的book元素 |
通配符
*表示通配符。
| 通配符 | 描述 | 示例 | 结果 |
|---|---|---|---|
| * | 匹配任意节点 | /bookstore/* | 选取bookstore下的所有子元素。 |
| @* | 匹配节点中的任何属性 | //book[@*] | 选取所有带有属性的book元素。 |
选取多个路径:
通过在路径表达式中使用“|”运算符,可以选取若干个路径。
示例如下:
//bookstore/book | //book/title
# 选取所有book元素以及book元素下所有的title元素
运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
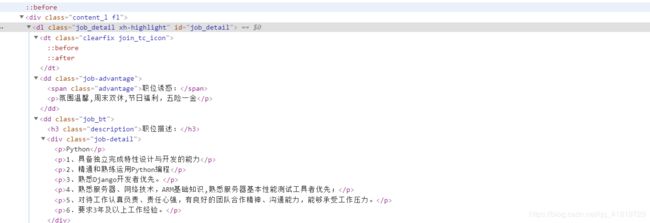
实例:
//dl[@class = 'job_detail' and @id='job_detail']
对应查找到的div:
总结
使用方式
使用//获取整个页面中的html元素,然后写标签名,再然后写谓词进行提取目标信息。比如:
//div[@class='job_detail']
需要注意的知识点
-
/和//的区别:/代表只获取子节点。//获取子孙节点。一般使用//居多,视具体需要决定使用哪种选择 -
contains:有时候某个属性中包含了多个值,那么可以使用contains()函数。进行模糊选择。如://div[contains(@class,'job_detail','job-location')] -
谓词中的下标是从1开始,不是从0开始的,如选择当前html页面中body的第一个div:
/html/body/div[1]
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:pip install lxml
基本使用:
我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全。示例代码如下:
# 使用 lxml 的 etree 库
from lxml import etree
text = '''
- first item
- second item
- third item
- fourth item
- fifth item # 注意,此处缺少一个
闭合标签
'''
#利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text)
# 按字符串序列化HTML文档
result = etree.tostring(html)
print(result)
输入结果如下:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first itema>li>
<li class="item-1"><a href="link2.html">second itema>li>
<li class="item-inactive"><a href="link3.html">third itema>li>
<li class="item-1"><a href="link4.html">fourth itema>li>
<li class="item-0"><a href="link5.html">fifth itema>li>
ul>
div>
body>html>
可以看到。lxml会自动修改HTML代码。例子中不仅补全了li标签,还添加了body,html标签。
从文件中读取html代码:
除了直接使用字符串进行解析,lxml还支持从文件中读取内容。我们新建一个hello.html文件:
<div>
<ul>
<li class="item-0"><a href="link1.html">first itema>li>
<li class="item-1"><a href="link2.html">second itema>li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third itemspan>a>li>
<li class="item-1"><a href="link4.html">fourth itema>li>
<li class="item-0"><a href="link5.html">fifth itema>li>
ul>
div>
然后利用etree.parse()方法来读取文件。示例代码如下:
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
输入结果和之前是相同的。
在使用lxml解析html代码时需要注意的点
-
解析html字符串:使用
lxml.etree.HTML进行解析,并且通过etree.tostring将解析的内容转换为字符串。直接解析出来的字符串会有编码问题,所以需要编码处理:def parse_text(text): htmlElement = etree.HTML(text) print(etree.tostring(htmlElement,encoding='utf-8').decode('utf-8')) # 需要 -
解析html文件,使用
lxml.etree.parse进行解析,这个函数默认使用的解析器是XML解析器,所以如果碰到一些不规范的html代码的时候会解析错误:lxml.etree.XMLSyntaxError: Opening and ending tag mismatch: input line 52 and div, line 68, column 23这时候需要自己创建
HTMLParser,即HTML解析器,并且在parse方法中指定该HTML解析器:def parse_excepted_file(file_name): # 当解析的内容有缺失的时候,可以手动设置解析器来解决报错 parser = etree.HTMLParser(encoding='utf-8') # 定义HTML解析器 htmlElement=etree.parse(file_name,parser=parser) # parser默认为xml的解析器,我们手动更改为Html的解析器 print(etree.tostring(htmlElement,encoding='utf-8').decode('utf-8'))
在lxml中使用XPath语法:
-
获取所有li标签:
from lxml import etree html = etree.parse('hello.html') print type(html) # 显示etree.parse() 返回类型 result = html.xpath('//li') print(result) # 打印- 标签的元素集合
-
获取所有li元素下的所有class属性的值:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/@class') print(result) -
获取li标签下href为
www.baidu.com的a标签:from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a[@href="www.baidu.com"]') print(result) -
获取li标签下所有span标签:
from lxml import etree html = etree.parse('hello.html') #result = html.xpath('//li/span') #注意这么写是不对的: #因为 / 是用来获取子元素的,而 并不是- 的子元素,所以,要用双斜杠
result = html.xpath('//li//span') print(result) -
获取li标签下的a标签里的所有class:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li/a//@class') print(result) -
获取最后一个li的a的href属性对应的值:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()]/a/@href') # 谓语 [last()] 可以找到最后一个元素 print(result) -
获取倒数第二个li元素的内容:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()-1]/a') # text 方法可以获取元素内容 print(result[0].text) -
获取倒数第二个li元素的内容的第二种方式:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()-1]/a/text()') print(result)
练习:
使用xpath爬取腾讯招聘网信息。要求为获取每个职位的详情信息。
"""
可以使用两种方式记录相关信息:
1. 字典+列表:被注释的部分
2. 列表+字典:选中的方案
"""
# job_dict = {"job_title":[],"job_detail":[],"job_department":[],"job_location":[],"job_publish_time":[]}
positions=[]
recruit_list = html.xpath("//div[@class = 'recruit-list']")
for recruit in recruit_list:
# 在//之前加一个点,代表是在当前元素下获取
title = recruit.xpath(".//h4[@class='recruit-title']//text()")[0] # 注意获取到的html元素集合的第一个元素
detail = recruit.xpath(".//p[@class='recruit-text']//text()")[0]
department = recruit.xpath(".//span[3]//text()")[0]
location = recruit.xpath(".//span[2]//text()")[0]
publish_time = recruit.xpath(".//span[4]//text()")[0]
# for i,j,k,z,w in zip(title,detail,department,location,publish_time):
# job_dict["job_title"].append(i)
# job_dict["job_detail"].append(j)
# job_dict["job_department"].append(k)
# job_dict["job_location"].append(z)
# job_dict["job_publish_time"].append(w)
position={
'job_title':title,
'job_detail':detail,
'job_department':department,
'job_location':location,
'job_publish_time':publish_time
}
positions.append(position)
# print("*"*25+"title"+"*"*25)
# print(job_dict["job_title"])
# print("*"*25+"detail"+"*"*25)
# print(job_dict["job_detail"])
# print("*"*25+"location"+"*"*25)
# print(job_dict["job_location"])
# print("*"*25+"department"+"*"*25)
# print(job_dict["job_department"])
# print("*"*25+"publish_time"+"*"*25)
# print(job_dict["job_publish_time"])
for p in positions:
print(p)
相关腾讯招聘网的html:
<div data-v-288d7ecc="" class="correlation-degree">
<div data-v-288d7ecc="" class="recruit-wrap recruit-margin">
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">CSIG17-AI开放平台高级测试工程师h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">CSIGspan>|
<span data-v-288d7ecc="">深圳,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">负责腾讯云叮当语音助手相关ToB业务质量保障工作及叮当开放平台质量保障工作,腾讯云叮当开放平台对外输出腾讯在AI领域特别是人机对话场景中的各项领先技术,在各种行业方向上和多家优质企业进行了深度的合作,包括腾讯车联网,智能家居,智能音箱,智能穿戴,智能机器人,文旅等领域都有合作。具体工作内容如下: 1、负责腾讯云叮当开放平台的质量保障及ToB业务定制需求的质量保障工作,负责全流程质量管控,包括参与需求分析,帮助完善需求与开发设计实现,合理设计测试计划,实施测试活动,跟进缺陷,协助研发分析定位问题; 2、负责产品相关的测试方案,测试工具平台,后台服务的接口自动化测试以及自动化监控用例建设,自动化测试架构设计及实现工作; 3、保证被测系统的质量,并通过测试流程和方法创新,提升研发的质量和效率 4、担任测试架构师角色,推动产品代码可测性建设及产品架构可测试性拆解,应用并落地分层测试相关技术,对后台服务进行代码审查,实施灰盒、白盒测试方法挖掘问题。 腾讯云叮当参考网址:dingdang.qq.comp>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1167336852961628160" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">36960-推荐架构后台开发工程师(北京)h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">PCGspan>|
<span data-v-288d7ecc="">北京,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">负责腾讯视频主app各场景、矩阵产品推荐系统的后台服务架构设计和实现, 建设高效/灵活/易用的统一融合的综合视频推荐架构;负 责各场景框架后台优化与技术探索;p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1253971408753532928" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">25926-NLP算法高级工程师(深圳)h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">IEGspan>|
<span data-v-288d7ecc="">深圳,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">负责腾讯游戏中恶意内容的分析与对抗; 负责上下文语义理解、内容理解和行为理解、情感分析等内容分析与挖掘;p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1253957413631959040" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">29777-企业数据智能高级研发工程师h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">CSIGspan>|
<span data-v-288d7ecc="">深圳,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">1、负责能源、工业、交通、传媒、运营商、终端等泛企业行业的数据智能产品研发; 2、设计并实现面向以上行业的数据智能产品,包括私有云和公有云版本; 3、打造面向以上行业的智慧大脑,提供一体化的数据中台和AI中台,快速构建行业应用,提升企业竞争力;p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1253914711825588224" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">CSIG07-游戏加速后台开发工程师(深圳)h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">CSIGspan>|
<span data-v-288d7ecc="">深圳,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">负责游戏加速产品智能加速后台业务系统的设计与开发; 负责游戏加速产品智能加速网络平台的架构设计与优化; 负责游戏加速产品运营系统的设计与优化;p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1123176283514081280" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">CSIG07-云平台安全工程师(北京)h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">CSIGspan>|
<span data-v-288d7ecc="">北京,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">负责公有云和专有云场景下的边界安全产品研发; 参与建设云平台的流量安全解决方案;p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1123176404893044736" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon in">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon facebook">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon twitter">a>
li>
ul>
<div data-v-114c7c2f="" class="link-wrapper">
<div data-v-114c7c2f="" class="link-text">岗位链接div>
<div data-v-114c7c2f="" class="link-ground">
<input data-v-114c7c2f="" readonly="readonly" id="" class="link input-text">
<div data-v-114c7c2f="" class="copy">复制链接div>div>
div>
div>
div>
div>
<div data-v-288d7ecc="" class="recruit-collection">
<span data-v-288d7ecc="" class="icon-collection">span>
<span data-v-288d7ecc="" class="collection-text">收藏span>div>
div>
<div data-v-288d7ecc="" class="recruit-list">
<a data-v-288d7ecc="" class="recruit-list-link">
<h4 data-v-288d7ecc="" class="recruit-title">CSIG07-基础安全威胁情报分析师h4>
<p data-v-288d7ecc="" class="recruit-tips">
<span data-v-288d7ecc="">CSIGspan>|
<span data-v-288d7ecc="">深圳,中国span>|
<span data-v-288d7ecc="">技术span>|
<span data-v-288d7ecc="">2020年04月25日span>p>
<p data-v-288d7ecc="" class="recruit-text">1.负责基础情报的生产和运营,以打造业界的领先威胁情报能力,服务于内外部产品 2.负责基础情报衍生产品的开发、运营和商业化p>a>
<div data-v-114c7c2f="" data-v-288d7ecc="" class="recruit-share">
<div data-v-114c7c2f="" class="recruit-content">
<span data-v-114c7c2f="" class="share">span>
<span data-v-114c7c2f="" class="share-text">分享span>
<div data-v-114c7c2f="" id="share-detail" class="share-list">
<div data-v-114c7c2f="" class="share-title">分享div>
<div data-v-114c7c2f="" class="close-btn">div>
<div data-v-114c7c2f="" id="1123176419774435328" class="qr-code" style="display: none;">div>
<ul data-v-114c7c2f="" class="share-gound">
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon qq">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="javascript:;" class="share-icon wechat">a>
li>
<li data-v-114c7c2f="" class="share-item">
<a data-v-114c7c2f="" href="" target="_blank" class="share-icon micro-blog">a>
li>