Scikit-learn学习笔记
一,必要的库和工具
- Scikit-learn 一个开源项目,python机器学习库
- Numpy python科学计算的基础包之一
- Scipy python中用于科学计算的函数集合
- matplotlib python主要的科学绘图库
- pandas 用于处理和分析数据的python库
- mglearn
二,数据集
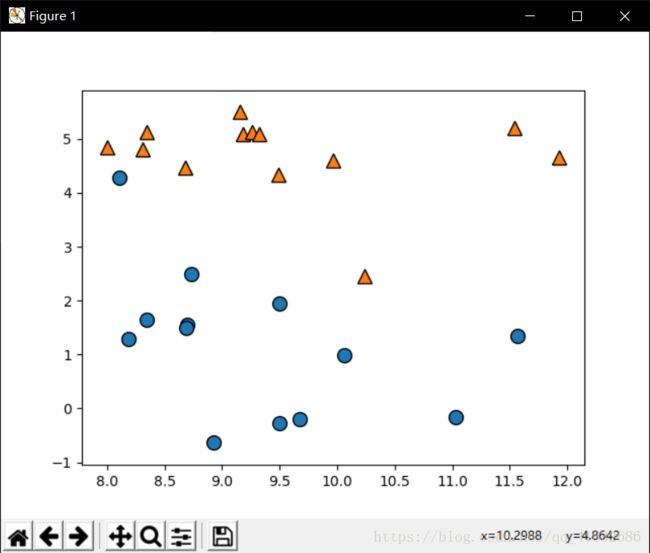
- forge数据集
用于分类
import mglearn
import matplotlib.pyplot as plt
X,y = mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.show()
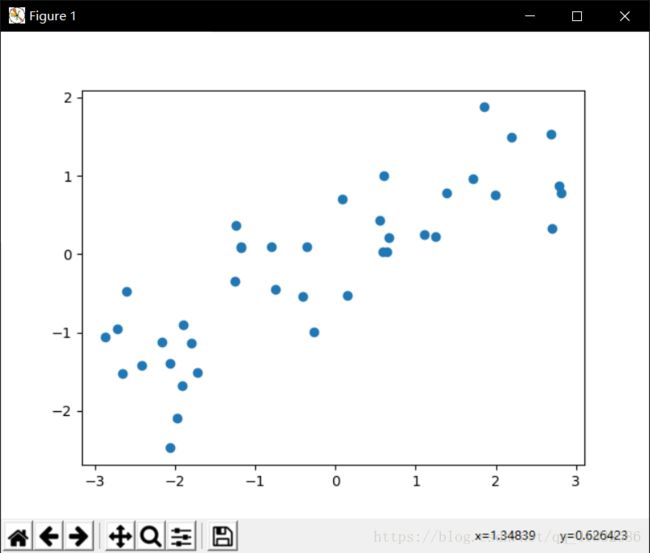
- wave数据集
用于回归
import mglearn
import matplotlib.pyplot as plt
X,y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X,y,'o')
plt.show()
- blobs数据集
from sklearn.svm import LinearSVC
import matplotlib.pyplot as plt
import mglearn
from sklearn.datasets import make_blobs
X,y = make_blobs(random_state=42)
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.show()

- moon数据集
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import mglearn
from sklearn.datasets import make_moons
X,y = make_moons(noise=.2)
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.show()

三,算法
- 回归
- 线性回归
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import mglearn
lr = LinearRegression()
lr.fit(X,y)
print(lr.coef_) #表示权重
print(lr.intercept_) #表示偏置
mglearn.plots.plot_linear_regression_wave()
plt.show()

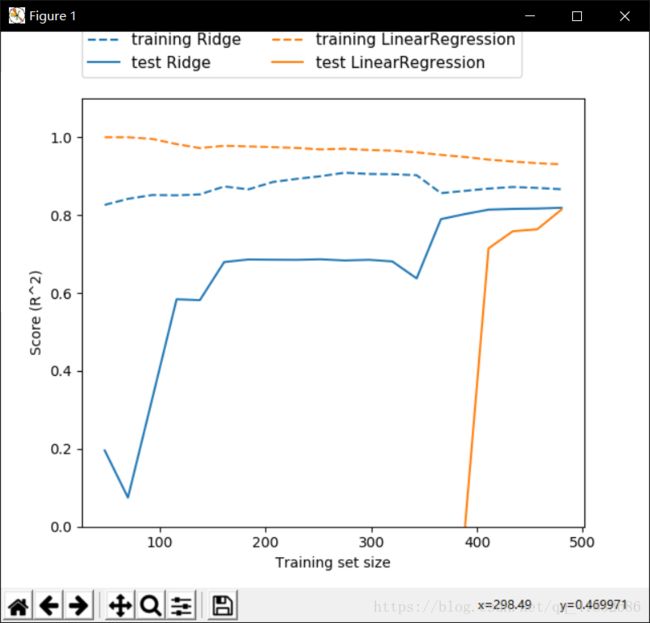
- 岭回归
就是使用L2正则化的线性回归,让每个系数变小,使得每个特征对输出结果的影响减小
from sklearn.linear_model import Ridge
import matplotlib.pyplot as plt
import mglearn
ridge = Ridge(alpha=10)
ridge.fit(X,y)
mglearn.plots.plot_ridge_n_samples()
plt.show()
- lasso
使用L1正则化的线性回归,使得某些系数刚好为0,即忽略某些特征
from sklearn.linear_model import Lasso
import matplotlib.pyplot as plt
import mglearn
lasso = Lasso(alpha=10)
lasso.fit(X,y)
- Logistic回归
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import mglearn
logreg = LogisticRegression(C =1penalty="l1",solver="sag,n_jobs=-1) #solver="sag"选项在处理大数据时,比默认值要快,n_jobs=-1使电脑所有的核运作
logreg.fit(X,y)
-
支持向量机
-
线性支持向量机
from sklearn.svm import LinearSVC
import matplotlib.pyplot as plt
import mglearn
svm = LinearSVC(C=1,penalty="l1")
svm.fit(X,y)
mglearn.plots.plot_linear_svc_regularization()
plt.show()

- 优点:
训练速度快,预测速度快
理解如何进行预测相对容易
缺点:
高维度难以解释系数
- k临近算法
- 分类
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train,y_train)
mglearn.plots.plot_knn_classification(n_neighbors=2)
plt.show()

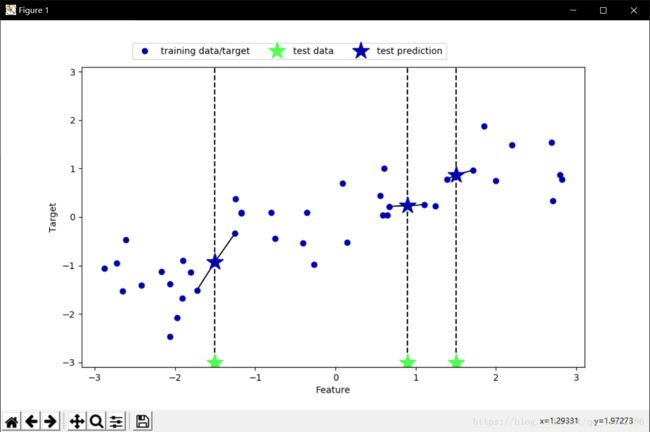
- 回归
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
import mglearn
knn = KNeighborsRegressor(n_neighbors=2)
knn.fit(X_train,y_train)
mglearn.plots.plot_knn_regression(n_neighbors=2)
plt.show()
-
优点:
模型容易理解
构建速度快
不需要过多调试就可以得到不错的性能 -
缺点:
如果训练集很大(特征很多或样本数很大),预测速度比较慢
对数据进行预处理很重要
- 决策树
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import mglearn
from sklearn.datasets import make_moons
tree = DecisionTreeClassifier(max_depth=4)
tree.fit(X,y)
-
优点:
模型容易可视化
不受数据放缩影响 -
缺点:
常常过拟合,泛化性差 -
随机森林
采用了自助采用(bootstrap sample),在节点处,算法选择特征的子集,以此来选择节点,使用max_features来控制选择特征个数
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import mglearn
from sklearn.datasets import make_moons
forest = RandomForestClassifier(n_estimators=100,)
forest.fit(X,y)
- 优点:
不需要反复调参
不需要放缩数据 - 缺点:
对于高维度稀疏数据表现不好 - 梯度提升树(梯度提升机)
from sklearn.ensemble import GradientBoostingClassifier
import matplotlib.pyplot as plt
import mglearn
from sklearn.datasets import make_moons
gbrt = GradientBoostingClassifier(learning_rate=0.1,max_depth=1,random_state=0)
gbrt.fit(X,y)
- 优点:
不用缩放 - 缺点:
需要仔细调参
训练时间长
四. 一些函数
- np.unque(x) 该函数是去除数组中的重复数字,并从小到大排序之后输
- knn快速实西现手写识别
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
digits = load_digits()
param = {'n_neighbors':[1, 2, 3, 4, 5]}
grid_search = GridSearchCV(KNeighborsClassifier(), param, cv=6)
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, random_state=0)
grid_search.fit(X_train, y_train)
print("acc:%.4f" % grid_search.score(X_test, y_test))
print("best parameters:", grid_search.best_params_)
print("best scorce:%.4f" % grid_search.best_score_)
print("best estimator", grid_search.best_estimator_)