Python自学笔记:Ch2 Python爬虫入门
本文可以作为爬虫入门的知识回顾。
一、网络数据获取
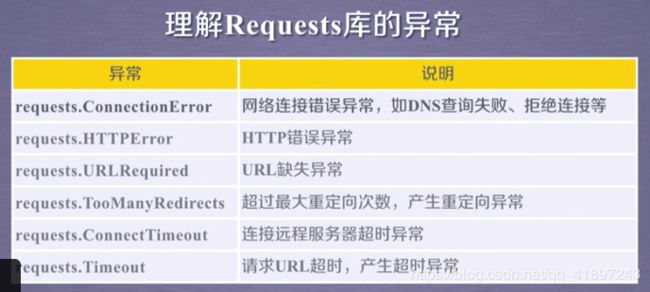
1.Requests库


>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> type(r)
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
u'{"type":"User"...'
>>> r.json()
{u'private_gists': 419, u'total_private_repos': 77, ...}
- status_code查看状态码;
- 状态码200表示访问成功;
- r.encoding:如果headers中不存在charset,则认为编码为ISO-8859-1;
- r.apparent_encoding:根据网页内容分析出编码方式;
2.爬豆瓣的例子
豆瓣现在有了反爬机制,直接爬取会返回状态码418,需要设置headers。
(1)为什么要设置headers?
在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
(2) headers在哪里找?
谷歌或者火狐浏览器,在网页面上点击右键,–>检查–>剩余按照图中显示操作,需要按Fn+F5刷新出网页来。
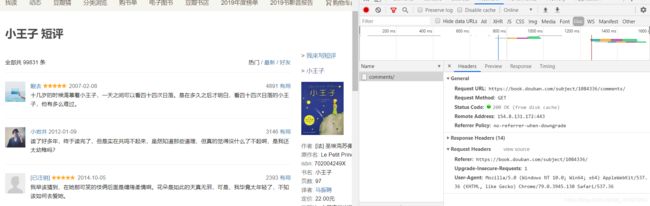
(3)headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
import requests
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
r = requests.get('https://book.douban.com/subject/1084336/comments/',headers=headers)
print(r.status_code)
print(r.text)
3.获取二进制文件
import requests
r = requests.get('https://www.baidu.com/img/bd_logo1.png')
with open('baidu.png', 'wb') as fp:
fp.write(r.content)
4.通用代码框架

import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
二、网页数据内容解析
1.BeautifulSoup库
BeautifulSoup库可以从HTML或XML文件中提取数据。BeautifulSoup()函数传入定义的字符串,BeautifulSoup对象有四种:Tag(标签,如< b >)、NavigableString(Tag里的字符串,如The Little Prince)、BeautifulSoup和Comment(NavigableString的一个子类)。
from bs4 import BeautifulSoup
markup = 'The Little Prince
'
soup = BeautifulSoup(markup,"lxml")
# 访问相应标签中的内容
print(soup.b)
print(soup.p)
# 类型是Tag
print(type(soup.b))
# 获得Tag属性的名字
tag = soup.p
print(tag.name)
print(soup.b.name)
# 获得Tag属性,一个Tag可以有多个属性
print(tag.attrs)
# 字典进行Tag属性操作
print(tag['class'])
# NavigableString对象可以用String来表示
print(tag.string)
print(type(tag.string))
# 寻找所有b标签的内容
print(soup.find_all('b'))
运行结果:
The Little Prince
The Little Prince
p
b
{'class': ['title']}
['title']
The Little Prince
[The Little Prince]
综合例子:
import requests
from bs4 import BeautifulSoup
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
r = requests.get('https://book.douban.com/subject/1084336/comments/',headers=headers)
soup = BeautifulSoup(r.text,"lxml")
# 寻找所有评论,评论行标签是span,属性是short
# find_all返回的是列表
pattern = soup.find_all('span','short')
for item in pattern:
print(item.string)
2.re正则表达式
正则表达式回顾:. 表示换行符以外的任意字符,*代表重复0或多次,加括号代表分组。
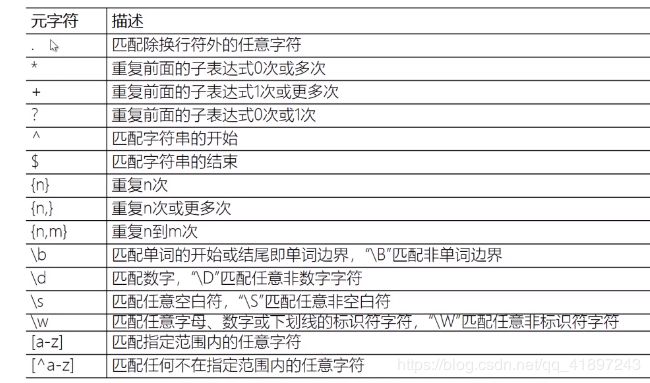
正则表达式匹配验证:regex101.com
import requests
from bs4 import BeautifulSoup
import re
s = 0
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
r = requests.get('https://book.douban.com/subject/1084336/comments/',headers=headers)
soup = BeautifulSoup(r.text,"lxml")
pattern = re.compile('三、爬取动态网页
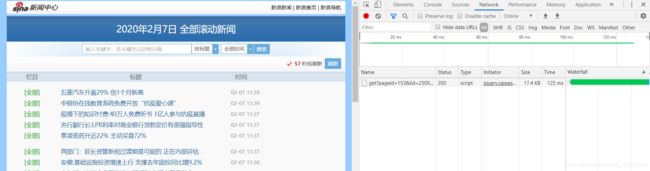
复制刷新后的URL:
import requests
r = requests.get('https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.09175927184067789&callback=jQuery111202855330483105005_1581046587196&_=1581046587203')
print(r.status_code)
# Unicode字符编解码转中文
print(r.text.encode('utf-8').decode('unicode-escape'))
四、Scrapy框架
1.结构解析
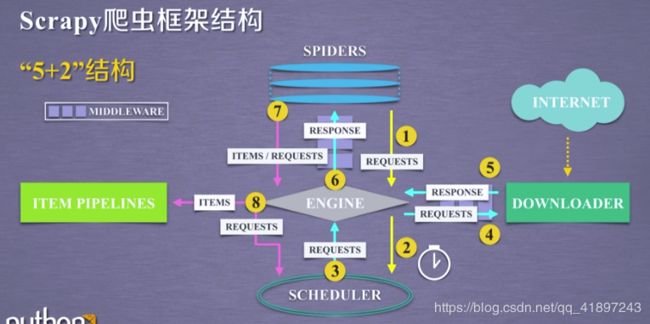


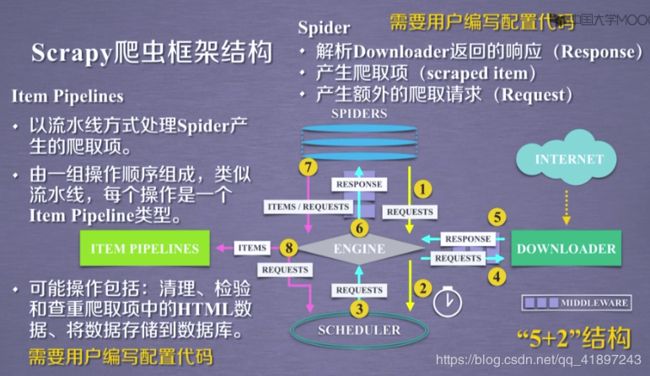

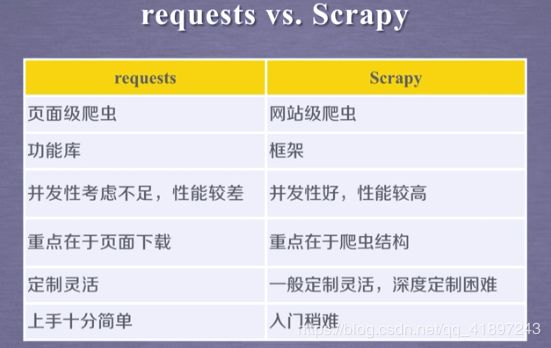
2.常用命令
scrapy < command > [options] [args]
