大数据平台架构技术选型与场景运用
内容来源:2017年5月6日,大眼科技CTO张逸在“魅族技术开放日第八期——数据洞察”进行《大数据平台架构技术选型与场景运用》演讲分享。视频地址:https://mp.csdn.net/console/editor/html/104497130

摘要
本次分享将结合多个大数据项目与产品研发的经验,探讨如何基于不同的需求场景搭建通用的大数据平台。内容涵盖数据采集、存储与分析处理等多方面的主流技术、架构决策与技术选型的经验教训。
大数据平台内容
大数据在工作中的角色有三种,当然也有交叉:
- Business—与业务相关,比如用户画像、风险控制等;
- Data Science—与数据科学有关,了解统计学、算法、深度学习这是数据科学家的范畴;
- Data Engineering——与数据工程相关,如何编程实施、实现,解决什么业务问题,这是数据工程师的工作。
数据工程师在业务场景和数据科学家之间搭建起实践的桥梁。本文要分享的大数据平台架构技术选型及场景运用偏向于工程方面。
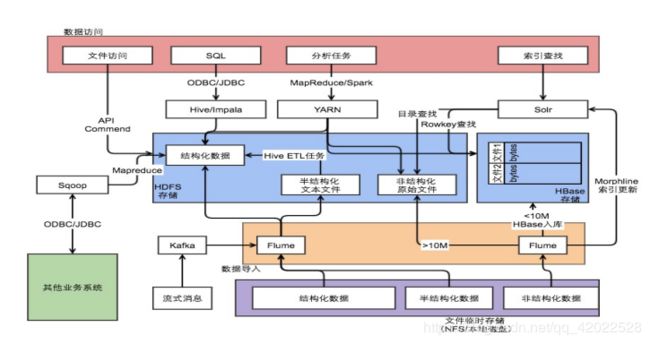
如图所示,大数据平台第一个要素就是数据源,我们要处理的数据源往往是在业务系统上,数据分析的时候可能不会直接对业务的数据源进行处理,而是先经过数据采集。采集到数据之后,基于数据源的特点把这些数据存储下来。最后根据存储的位置做数据分析和处理。
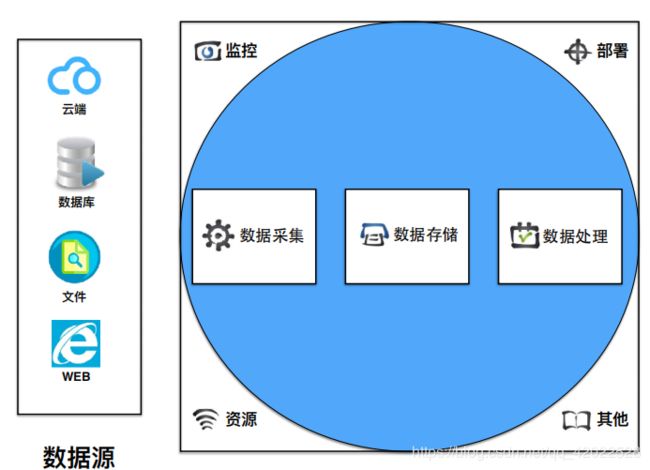
从整个大的生态圈可以看出,要完成数据工程需要大量的资源;数据量很大需要集群;要控制和协调这些资源,需要监控和协调分派;面对大规模的数据怎样部署更方便更容易,比如docker;还牵扯到日志、安全、还可能要和云端结合起来,这些都是大数据圈的边缘,同样都很重要。
数据源的特点
数据源的特点决定了数据采集与数据存储的技术选型。数据源的特点主要有来源、结构、可变性和数据量四大类。
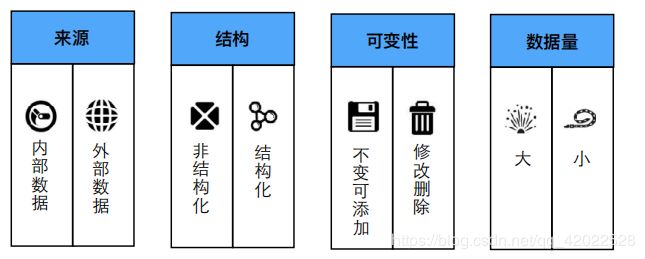
- 来源有内部数据和外部数据,它们的处理方式是不一样的。
- 结构型数据和非结构型数据的选型也是不同的。
- 第三个特点是数据是否具有可变性,分为不变可添加和可以修改删除两种类型。
- 数据量则有大数据量和小数据量之分。
1.内部数据
来自企业内部系统,特点:经过自理(有序)、以结构性数据为主,系统可控制。可以采用主动写入技术(push),比如写入Mysql、Oracle的同时,写入到HDFS中,从而保证变更数据及时被采集。
2.外部数据
企业要做大数据的话肯定不会只局限于企业内部的数据,比如银行做征信,就不能只看银行系统里的交易数据和用户信息,还要到互联网上去拉取外部数据。
外部数据分为两类:
- 一类是要获取的外部数据本身提供API,可以调用API获取,比如微信;
- 另一类是数据本身不提供API,需要通过爬虫爬取过来。

这两类数据都不是我们可控制的,需要我们去获得,它的结构也可能跟我们企业内部数据的结构不一样,还需要进行转换。爬虫爬取的数据结构更乱,因此大数据平台里需要做ETL,由ETL进行数据提取、转换、加载,清洗、去重、去噪。爬虫爬过来的数据往往是非结构性的、文档型的数据,还有视频、音频,这就更麻烦了。
3.结构化数据 & 非结构化数据
非结构化数据和结构化数据在存储的时候选型完全不同。非结构化数据更多会选择文件系统、NoSQL的数据库,而结构化数据考虑到数据的一致性和查询在某些方面做join时的快速性,则会更偏向于选择传统的关系型数据库,或是像TERADATA这样非开源的专业数据库,以及PostgreSQL这种支持分布式的数据库。

4.不变可添加数据
如果数据源的数据是不变的,或者只允许添加(通常,数据分析的事实表,例如银行交易记录等都不允许修改或删除),则采集会变得非常容易,同步时只需要考虑最简单的增量同步策略,维持数据的一致性也相对变得容易。
对于大数据分析来说,我们每天在处理的数据大部分是不可变更的。正如Datomic数据库的设计哲学就是数据为事实(fact),它是不可变的,即数据是曾经发生的事实,事实是不可以被篡改的,哪怕改一个地址,从设计的角度来说也不是改动一个地址,而是新增了一个地址。交易也是如此。
5.可修改可删除
银行的交易记录、保险单的交易记录,互联网的访客访问记录、下单记录等都是不可变的。但是数据源的数据有些可能会修改或删除,尤其是许多维表经常需要变动。要对这样的数据进行分析处理,最简单的办法就是采用直连形式,但直连可能会影响数据分析的效率与性能,且多数数据模型与结构可能不符合业务人员进行数据分析的业务诉求。如果采用数据采集的方式,就要考虑同步问题。
- 小数据量:直连方式,如连接mysql等传统数据库。
- 大数据量:需要一套同步机制。如HDFS以文件(名称节点)为单元备份、修改、重名称、删除备份。轮询扫描数据改、删记录存储文件,用于后续同步依据。
6.大数据量
针对大数据量,如果属于高延迟的业务,可以采用批处理方式,实时分析则需要使用流式处理,将两者结合就是Lambda架构,即有实时处理、又能满足一定的大数据量,这是现在比较流行的大数据处理方式。
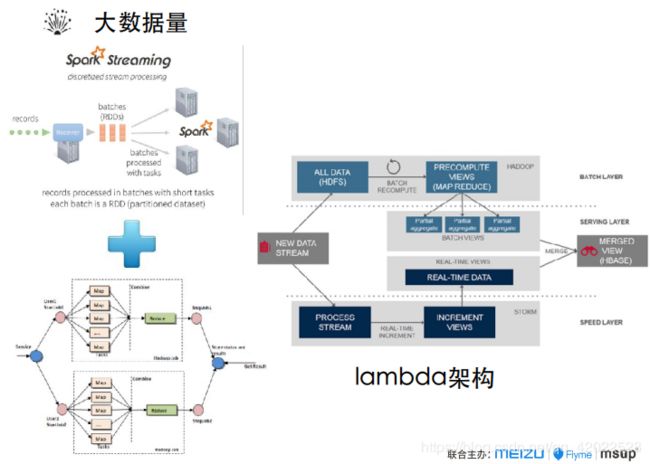
Lambda架构分为了三层,最下层是speed layer,要求速度快,也就是实时。
最上层是batch layer,也就是批处理。
通过中间层serving layer,定期或不定期地把batch views和speed views去做merged,会产生一个结合了batch的数据。它既满足了一定的实时性,又能满足一定的大数据量。这是目前比较流行的一种大数据的处理方式。
7.一个典型的数据加载架构
数据存储的技术选型
数据存储的技术选型依据有三点:
取决于数据源的类型和采集方式。
- 比如非结构化的数据不可能拿一个关系数据库去存储。采集方式如果是流失处理,那么传过来放到Kafka是最好的方式。
取决于采集之后数据的格式和规模。
- 比如数据格式是文档型的,能选的存储方式就是文档型数据库,例如MongoDB;采集后的数据是结构化的,则可以考虑关系型数据库;如果数据量达到很大规模,首选放到HDFS里。
取决于分析数据的应用场景。
- 根据数据的应用场景来判定存储技术选型。
大数据平台特征:相同的业务数据会以多种不同的表现形式,存储在不同类型的数据库中,形成一种poly-db的数据冗余生态。
场景一:舆情分析
做舆情分析的时候客户要求所有数据存放两年,一天600多万,两年就是700多天×600多万,几十亿的数据。而且爬虫爬过来的数据是舆情,做了分词之后得到的可能是大段的网友评论,客户要求对舆情进行查询,做全文本搜索,并要求响应时间控制在10s以内。
我们后来选择用ES,在单机上做了一个简单的测试,大概三亿多条数据,用最坏的查询条件进行搜索,保证这个搜索是全表搜索(基于Lucence创建了索引,使得这种搜索更高效),整个查询时间能控制在几秒以内。
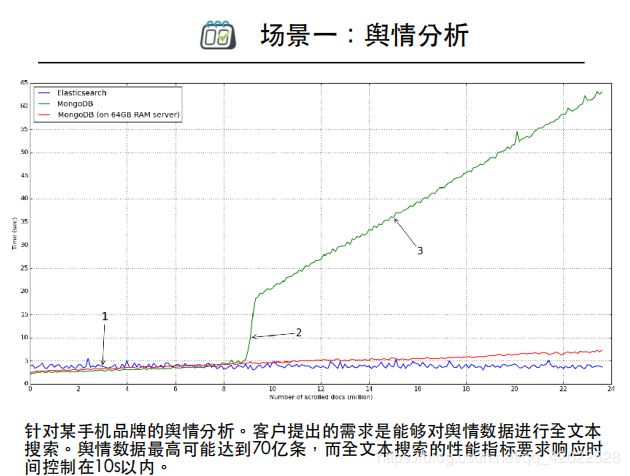

如图所示,爬虫将数据爬到Kafka里,在里面做流处理,去重去噪做语音分析,写到ElasticSearch里。我们做大数据的一个特点是多数据库,会根据不同的场景选择不同的数据库,所以会产生大量的冗余。
场景二:商业智能产品
BI产品主要针对数据集进行的数据分析以聚合运算为主,比如求合、求平均数、求同比、求环比、求其他的平方差或之类的标准方差。我们既要满足大数据量的水平可伸缩,又要满足高性能的聚合运算。选择Parquet列式存储,可以同时满足这两个需求。

聚合运算把数据源采集存储的时候,是基于列的运算,而传统数据库是行式存储。行式存储针对于列的运算需要全表才能拿到,这时选择用parquet。因为parquet是以列式方式做存储,所以做统计分析很快。但parquet执行查询会很慢,没有优势。
场景三:Airbnb的大数据平台
Airbnb的大数据来自两块:一是本身的业务数据在MySQL,二是大量的事件。数据源不同,采集方式也不一样。
基于日志,就用事件写入kafka;如果是针对MySQL,就用Sqoop,写入HDFS里,并建立Hive的集群。还存了一份数据放入亚马逊的S3。

有一部分业务就是对数据合并后放入HDFS做大量的业务查询和业务统计。这时希望用SQL的方式进行查询,会有很多选项,它选择的是Presto。
还有一些流式处理或机器学习要用到Spark,选型就会不同。
数据处理
数据处理分为三大类:
- 第一类是从业务的角度,细分为查询检索、数据挖掘、统计分析、深度分析,其中深度分析分为机器学习和神经网络。
- 第二类是从技术的角度,细分为Batch、SQL、流式处理、machine learning、Deep learning。
- 第三类是编程模型,细分为离线编程模型、内存编程模型、实时编程模型。

结合前文讲述的数据源特点、分类、采集方式、存储选型、数据分析、数据处理,我在这里给出一个总体的大数据平台的架构。值得注意的是,架构图中去掉了监控、资源协调、安全日志等。
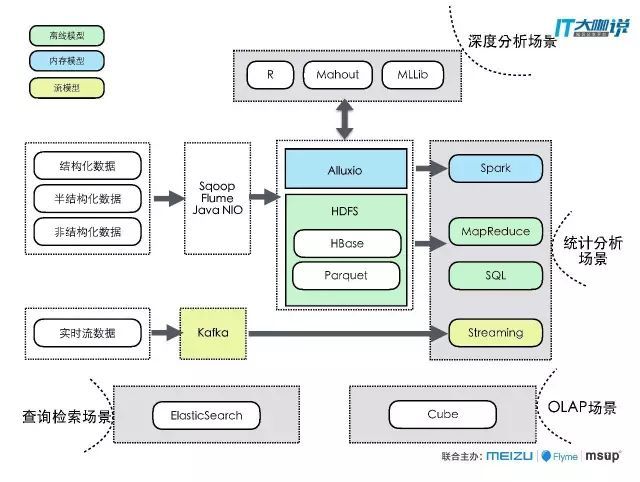
左侧是数据源,有实时流的数据(可能是结构化、非结构化,但其特点是实时的),有离线数据,离线数据一般采用的多为ETL的工具,常见的做法是在大数据平台里使用Sqoop或Flume去同步数据,或调一些NIO的框架去读取加载,然后写到HDFS里面,当然也有一些特别的技术存储的类型,比如HAWQ就是一个支持分布式、支持事务一致性的开源数据库。
从业务场景来看,如果我们做统计分析,就可以使用SQL或MapReduce或streaming或Spark。如果做查询检索,同步写到HDFS的同时还要考虑写到ES里。如果做数据分析,可以建一个Cube,然后再进入OLAP的场景。
这个图基本上把所有的内容都涵盖了,从场景的角度来分析倒推,用什么样的数据源、采用什么样的采集方式、存储成什么样子,能满足离线、内存、实时、流的各种模型,都能从图中得到解答.