python-gpu项目的docker部署
一,docker简介
docker基本关系图:
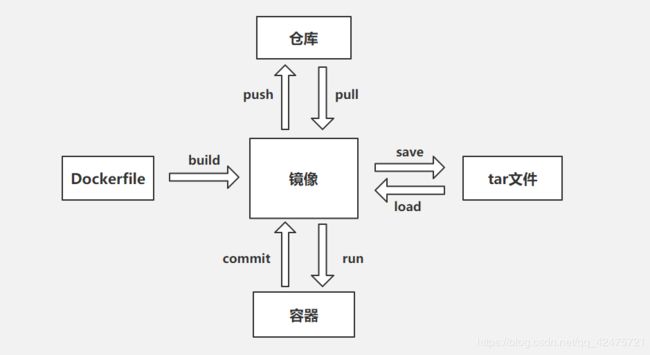
常用指令:
docker pull:从仓库拉取镜像(获取镜像方式一)
docker images:查看本地可用的镜像
docker run -it -d:运行镜像成为一个容器(若你的镜像在以容器启动后没有一个前台进程,加上-it 后不会自动exited)
-d 后台运行 -p 内部:外部端口映射 --name:给容器起别名 -v:映射外部内部文件 -v‘pwd’:/usr/share/nginx/html
docker run -d -p 88:80 --name mynginx -v ‘pwd’:/usr/share/nginx/html nginx:1.13(1.13为指定NGINX的版本)
docker exec:进入容器
exit :退出容器
docker ps:查看运行的容器
docker ps -a : 查看当前系统中容器的列表
docker rm:删除容器
docker commit:将容器提交为镜像
dockerfile: 获取镜像方式二
创建dockerfile文件:
add:将当前文件夹下所有文件复制到 容器/usr/share/nginx/html/ 目录下
docker build -t m2 .
m2:创建的镜像名 .:当前目录
docker save: 将镜像保存为tar文件
docker load:加载tar为镜像(获取镜像方式三)
二,Dockerfile文件示例
Dockerfile 文件可以通过docker build指令构建为一个docker镜像。
Dockerfile文件示例:
FROM tensorflow/tensorflow:1.14.0-gpu-py3 # 需要加载的基础镜像
LABEL maintainer="e-mail" # 说明维护人
ADD ./ /faq_serving # 将当前目录下的所有文件复制到镜像的指定目录,也可以通过挂载的方式将宿主代码映射至容器中
WORKDIR /faq_serving # 指定工作路径
CMD ["/bin/bash", "docker_run.sh"] # 容器运行时的启动项
docker_run.sh:
#!/bin/bash
pip install --upgrade pip >> init_state.txt # 升级pip
pip install -r requirements.txt >> init_state.txt # 安装 requirements.txt中的依赖包
echo "The operating environment is configured" >> init_state.txt
nohup python3 main.py >/dev/null 2>&1 & # 后台运行main.py
Pid=`ps ax|grep main.py|grep -v grep|awk '{print $1}'`
if [ -n "$Pid" ]
then
echo "faq_serving start success!!!" >> init_state.txt
else
echo "faq_serving start fail, see the [/faq_serving/logs/] error log" >> init_state.txt
fi
tail -f /dev/null # 加这句是为了防止容器自动停止运行
最后的 tail -f /dev/null 很关键,因为python程序是以后台挂起的形式运行,所以如果不加这句话的话,容器会因为没有前台进程而自动停止运行, 至于为什么用tail指令,是因为我不会其他的,所以你可以替换为你熟悉的其他可以前台一直挂起的指令。
这个shell文件会安装python程序运行的依赖包,为了查看这些库的安装进度,所以将安装进度相关的输出保存在init_state.txt 文件中,在进入容器后可以通过tail -f init_state.txt 跟踪进度。
三,docker-compose.yml文件
docker-compose文件用处很多,可以方便的制定容器镜像、容器基本配置、多容器组织等。但是在若想通过docker-compose运行gpu项目,需要安装nvidia-docker2.
docker-compose作用是:可以方便的通过docker-compose up -d 和 docker-compose down 这两个指令方便的运行和卸载容器。
docker-compose.yml文件示例:
version: "2.3" # 指定docker-compose.yml版本,注意使用2.3版,否则runtime会报错
services:
faq:
container_name: faq_serving
runtime: "nvidia" # 若需要直接运行docker-compose.yml文件运行容器,则需要先安装nvidia-docker2
environment:
NVIDIA_VISIBLE_DEVICES: all
#NVIDIA_DRIVER_CAPABILITIES: compute,utility
#NVIDIA_REQUIRE_CUDA: "cuda>=9.0"
image:
faq_serving18
ports:
- "8866:8866" 宿主机:容器 端口映射
# 修改volumes :/tmp/pycharm_project_779/config.json 前面的路径,该路径即为需要替换的config文件路径,注意,必须是绝对路径
# 之后修改宿主机上的config文件即可
volumes:
- /opt/cc/qa_bert/config.json:/faq_serving/config.json # 将宿主机的配置文件挂载至容器中
restart: always
四,镜像构建及运行(Dockerfile,docker-compose.yml使用方法)
将Dockerfile,docker-compose.yml这两个文件放在你项目的根目录下
4.1 通过Dockerfile 构建镜像
docker build -t faq_serving18 .
4.2 可以通过两种镜像运行方法运行gpu项目
A. docker run 指令(该方法无需 docker-compose.yml文件)
在最新的docker 19.03版本中可以通过–gpus all 指令直接使用gpu,而无需安装nvidia-docker2
docker run -itd -p 8866:8866 -v /opt/cc/qa_bert/config.json:/faq_serving/config.json --gpus all images_id
-itd 在后台以交互形式运行镜像
-p 宿主机:容器 端口映射
-v 将宿主机文件挂载至容器中
–gpus all 容器可使用gpu
images_id 镜像id,通过docker images查看
4.2 通过docker-compose.yml运行
前提是安装好nvidia-docker2,安装方法在后面
docker-compose up -d
4.3 进入容器配置查看python程序运行状态
4.3.1 查看容器id
docker ps
4.3.2 进入容器
docker exec -it 容器ID bash
4.3.3 通过init_state.txt 查看python3环境配置及python程序启动情况
tail -f init_state.txt
五,配置宿主机gpu使用环境
容器是可以使用宿主机的nvidia环境配置的。
以下是我在gpu服务器上的环境配置:
- cuda:10.0.130 (查看方式:cat /usr/local/cuda/version.txt)
- cudnn:7.6.3 (查看方式:cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2)
运行 cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 后显示如下:
#define CUDNN_MAJOR 7
#define CUDNN_MINOR 6
#define CUDNN_PATCHLEVEL 3
则为 7.6.3 - nvidia显卡驱动版本:410.48 (查看方式:cat /proc/driver/nvidia/version)
- centos 7.3.1611
如何确定你是否能使用gpu,运行下面的代码,如果输出为True,则可以使用GPU
import tensorflow as tf
print(tf.test.is_gpu_available())
六,docker 安装
6.1. 安装docker-ce(建议安装docker 19.03版,上面两种GPU项目运行方法都可使用)
6.1.1 查询docker安装过的包:yum list installed | grep docker
6.1.2 删除安装包:yum remove docker.x86_64 … -y
6.1.3 安装相关依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
6.1.4 设置仓库
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
6.1.5 安装最新版本19.03 docker-ce
yum install docker-ce docker-ce-cli containerd.io
6.1.6 (可选)安装固定版本docker-ce
6.1.6.1 查看可用版本
yum list docker-ce --showduplicates | sort -r
6.1.6.2 安装(以18.09.2为例)
yum install docker-ce-18.09.2 docker-ce-cli-18.09.2 containerd.io
6.1.7 启动docker-ce
systemctl enable docker.service
systemctl start docker
6.2. 安装nvidia-docker2
6.2.1 若已安装nvidia-docker1.0 则删除
6.2.1.1 检测是否安装nvidia-docker1.0
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
6.2.1.2 删除
yum remove nvidia-docker
6.2.2 添加仓库
distribution=$(. /etc/os-release;echo I D ID IDVERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
6.2.3 安装nvidia-docker2,重载Docker daemon configuration
yum install -y nvidia-docker2
pkill -SIGHUP dockerd
两个速度很快的docker源:
- http://f1361db2.m.daocloud.io
- https://y0qd3iq.mirror.aliyuncs.com
方法:
vi /etc/docker/daemon.json
在其后添加:
{
"registry-mirrors":["加速链接"]
}
然后重启docker服务
systemctl docker restart