Windows下搭建PySpark环境
Windows下搭建PySpark环境
文章目录
- Windows下搭建PySpark环境
- 前言
- 方法一
- 安装单机版Hadoop
- 安装单机版Spark
- PySpark环境整合
- 方法二
- 测试PySpark
- PySpark运行简单实例
- 参考文章
前言
现阶段的实验需要用到 PySpark 来搭建机器学习模型,正常情况下应该是在 Linux 系统上是进行搭建。然而在虚拟机的 Linux 上运行起来又实在是太慢,所以只能将就着在 Windows 系统上搭建 PySpark 的环境先使用着。
这里介绍两种搭建 PySpark 环境的方法:
- 常规法(安装Hadoop、Spark)
- pip安装法
在以下的操作中用到命令行的时候,按 Win+R 键,输入 cmd 然后回车,就可以进入命令行了。每个阶段的命令行每次使用完毕之后,正常关闭命令行窗口即可。
方法一
常规安装 Pyspark 的方法是先安装 JDK,接着是 Hadoop,然后安装 Spark,最后配置一下 PySpark 的环境就可以了。
和方法二相比,方法一的整个过程显得漫长且比较繁琐,请一定要保持耐心,不要输错任何一行命令。
安装单机版Hadoop
Hadoop的底层语言是 Java,在使用 Hadoop 之前,得先把 JDK 配置一下,可以参考这篇博客的第一部分,把 JDK 配置好。 Windows下配置IDEA开发环境
配置完 JDK 之后,就可以开始配置 Hadoop 了。Windows 安装 Hadoop 的流程可以参考我的另一篇博客 Windows下配置单机Hadoop环境
去年写博客的时候对 Hadoop 还不太熟悉,博客名字是单机环境,实际上配置的是伪分布式环境。
这里我们只需要配置单机版 Hadoop 就可以了,我们只需要完成前三步,下载 Hadoop,下载配置文件,配置环境变量。
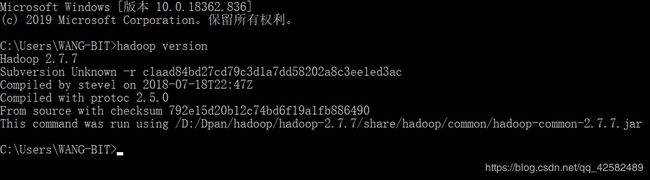
前三步完成后,单机版 Hadoop 就配置完成了。我们在命令行界面输入“hadoop version”,能正常提示出 Hadoop 的版本信息,这一步就确认完成了。
安装单机版Spark
Spark的安装大致上和 Hadoop 差不多,不过我们最后只需要用到 Spark 的 PySpark 包,所以我们不需要去配置 Scala 这些东西,严格意义上说我们只需要单机版 Spark,配置个环境变量就可以了。
同样地,我们去北理工的镜像站下载 Spark Spark北理工镜像
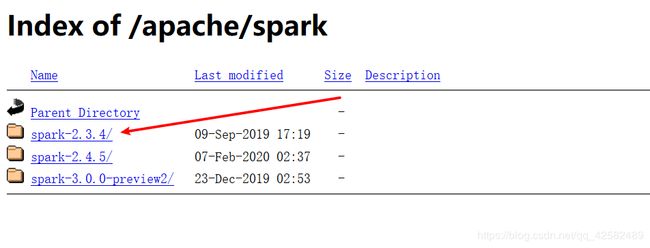
镜像站提供了几个稳定版本,这里我们选择的是 spark-2.3.4,点击进入目录
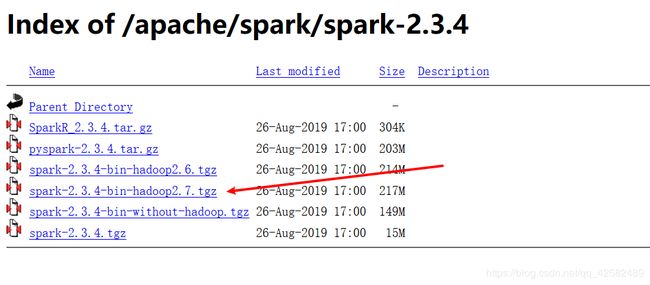
因为我们上一步安装的 Hadoop 版本是 2.7.7,所以这里我们选择和 Hadoop-2.7.7 兼容的 版本。
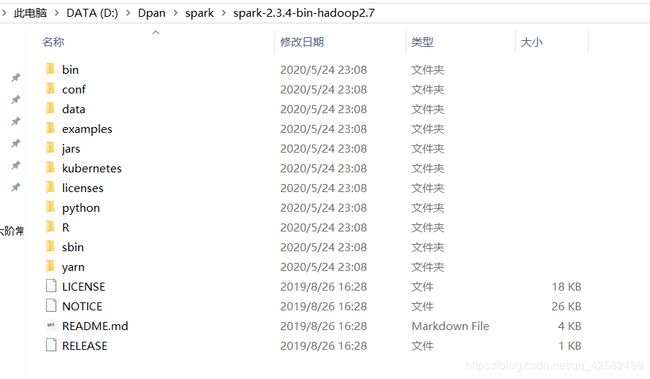
镜像站的下载一般都很快,下载完成后,把 Spark 的压缩包解压到自己想要的安装位置,比如我的安装位置是“D:\Dpan\spark”,解压完成的界面如下。
解压完成后,直接去配置 spark 的环境变量,和 Hadoop 配置环境变量的方式是一样的。
- 新建 SPARK_HOME 环境变量,变量的值就是 spark 包解压的地址。比如我的是“D:\Dpan\spark\spark-2.3.4-bin-hadoop2.7”
- 向 path 变量中加入“%SPARK_HOME%\bin”。注意,这里的 %SPARK_HOME%\bin,是固定的短语,不要乱写。
配置完成之后,在命令行界面输入“spark-shell”,耐心等待两分钟。如果命令行正常出现了 spark 的 shell 信息,单机版 spark 环境就配置成功了。
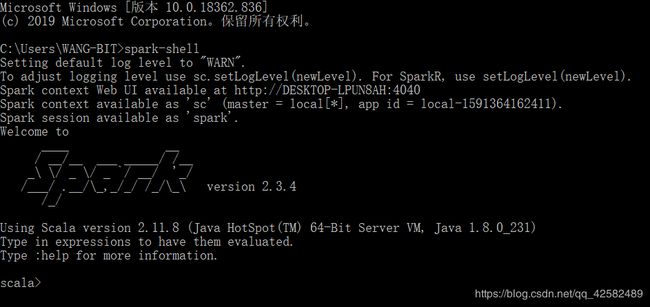
如果出现类似缺少 winutil 或者 hivesession 等错误,请检查hadoop/bin文件夹是否替换成功。如果确实替换了 hadoop/bin,还出现错误,自行百度安装 cygwin,安装完 cygwin 就应该没有问题了。
PySpark环境整合
整个 PySpark 的环境整合是比较简单的,不需要再去安装别的新东西了。
我们通过文件资源管理,进入之前 spark 的安装目录。将安装目录下的 python/lib 目录下的两个压缩包进行复制,pyspark.zip、py4j-0.10.7-src.zip。
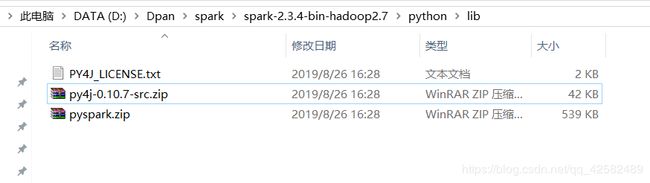
然后进入 自己的 Python 安装目录/Lib/site-packages 目录下,粘贴,然后解压。解压完成后可以顺便把这两个压缩包删除了。
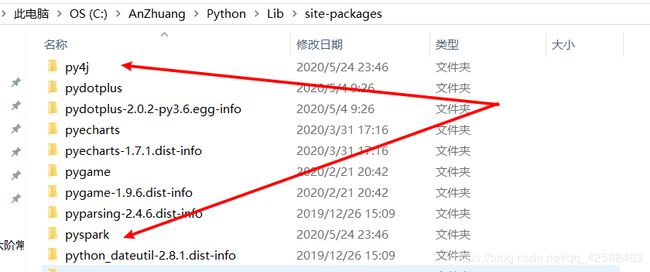
到这里,PySpark的环境就配置完成了。
方法二
pip 是一个 Python 包安装与管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。我们通过 pip 来进行 Python 包的安装绝对是十分便捷的。
pip的安装这里我们不做介绍,没有安装 pip 的请自行百度安装即可。
打开命令行窗口,在窗口内输入“pip --verison”,如果出现了 pip 的版本提示信息,那么你电脑上的 pip 就是成功安装了。
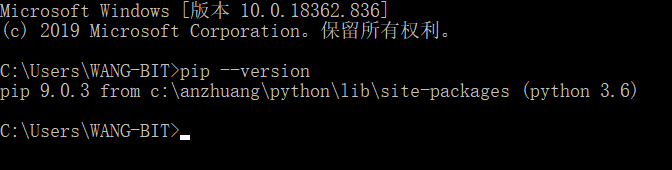
通过 pip 安装 PySpark 就像安装其他 Python 包一样简单。在命令行窗口内输入一下代码,回车即可安装。
pip install pyspark
当然,为了提高安装速度,我们可以使用清华源来进行安装
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
耐心等待安装完成,在最后出现‘Success’的字样,就表示安装成功了。
测试PySpark
前面介绍了两种方法配置 PySpark 的环境,配置完成后我们来进行检验。
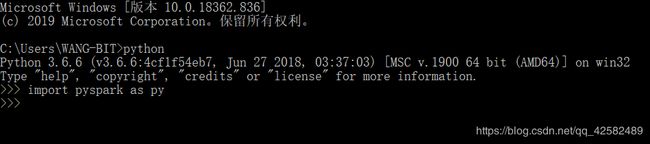
在命令行输入“python”,进入 python 命令行。输入“import pyspark as py”,回车。没有报错,就证明 pyspark 的环境配置成功了,可以正常使用了。
PySpark运行简单实例
打开自己平时用来写 Python 代码的 IDE。比如我用的是 PyCharm2019。
在里面新建一个 Python 文件,输入以下代码。这段代码就是经典的 WordCount ,用 PySpark 来运行。
from pyspark import SparkConf, SparkContext
# 创建 SparkConf 和 SparkContext
conf = SparkConf().setMaster("local").setAppName("lichao-wordcount")
sc = SparkContext(conf=conf).getOrCreate()
# 输入的数据
data = ["hello", "world", "hello", "word", "count", "count", "hello"]
# 将 Collection 的 data 转化为 spark 中的 rdd 并进行操作
rdd = sc.parallelize(data)
resultRdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# rdd 转为 collecton 并打印
resultColl = resultRdd.collect()
for line in resultColl:
print(line)
# 结束
sc.stop()
运行代码,耐心等待,查看结果。
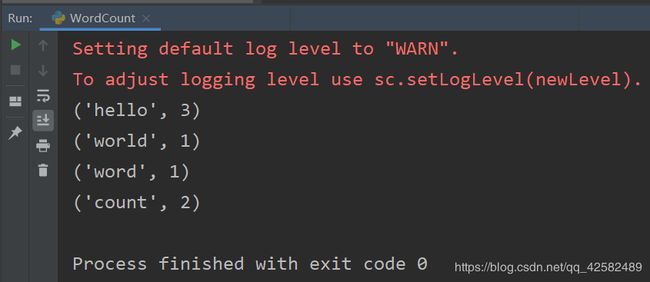
至此,Windows 下 PySpark的环境已经配置完毕了,我们还运行了一个实例。环境配置完毕,快快去学习 PySpark 的使用方法,把这个工具用起来把。
参考文章
Python学习—PySpark环境搭建
Windows下配置单机Hadoop环境
pycharm修改pip源为清华源-提高下载速度