数据分析与挖掘案例之使用python抓取豆瓣top250电影数据进行分析
使用python抓取豆瓣top250电影数据进行分析
抓取豆瓣Top250电影数据的链接和电影名称
代码如下:
import urllib.request as urlrequest
from bs4 import BeautifulSoup
import re
import csv,codecs
top250_url ='https://movie.douban.com/top250?start={}&filter='
movie_name='名称'
movie_assess='评价人数'
movie_score='评分'
movie_url ='链接'
movie_intro='介绍'
movie_num =0
#print('{} {} {} {} {}'.format(movie_name,movie_assess,movie_score,movie_url,movie_intro))
with open('top250_movie.csv','w',encoding='utf8') as outputfile:
#outputfile.write(codecs.BOM_UTF8)
writer = csv.writer(outputfile)
#writer.writerow(["movie_num","movie_name","movie_assess","movie_score","movie_url","movie_intro"])
outputfile.write("movie_num#movie_name#movie_year#movie_country#movie_type#movie_director#movie_assess#movie_score#movie_url#movie_intro\n")
for list in range(10):
movies_content = urlrequest.urlopen(top250_url.format(list*25)).read()
movies_html = movies_content.decode('utf8')
moviessoup = BeautifulSoup(movies_html,'html.parser')
all_list = moviessoup.find_all(class_='item')
#print(all_list)
for item in all_list:
item_data=item.find(class_='pic')
movie_url = item_data.find('a')['href']
movie_name = item_data.find('img')['alt']
item_info = item.find(class_='star')
info = item.find('div', attrs={'class': 'star'})
#find_all 将star标签中的所有span 存入一个列表中
movie_assess =info.find_all('span')[3].get_text()[:-3]
movie_score = item_info.find('span',attrs={'class':'rating_num'}).get_text()
try:
movie_intro = item.find(class_='quote').find(class_='inq').get_text()
except Exception as e:
movie_intro='None'
movie_num =movie_num+1
#print(movie_assess)
#print(item_assissent)
# item_assisent = item_data.find(name='span',attrs={'property':'v:average'})
#抓取电影上映年份、 导演、主演等信息
movie_actor_infos_html = item.find(class_='bd')
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
movie_actor_infos = movie_actor_infos_html.find('p').get_text().strip().split('\n')
actor_infos1 = movie_actor_infos[0].split('\xa0\xa0\xa0')
movie_director = actor_infos1[0][3:]
#print(movie_director)
movie_role = movie_actor_infos[1]
movie_year_area = movie_actor_infos[1].lstrip().split('\xa0/\xa0')
movie_year = movie_year_area[0]
#print(movie_year)
movie_country = movie_year_area[1]
#print(movie_country)
movie_type = movie_year_area[2]
#print(movie_type)
#print('{} {} {} {} {} {} {} {} {} {}'.format(movie_num,movie_name,movie_year,movie_country,movie_type,movie_director,movie_assess,movie_score,movie_url,movie_intro))
#writer.writerow([movie_num,movie_name,movie_assess,movie_score,movie_url,movie_intro])
if movie_type =='':
movie_type='NULL'
outputfile.write('{}#{}#{}#{}#{}#{}#{}#{}#{}#{}\n'.format(movie_num,movie_name,movie_year,movie_country,movie_type,movie_director,movie_assess,movie_score,movie_url,movie_intro))
运行代码生成top250_movie.csv文件
文件下载:
链接:https://pan.baidu.com/s/1-5Hp__s3IyOxJRskixBXEA
提取码:pnuv
如下:

打开top250_movie.csv 文件:
import numpy as np
import pandas as pd
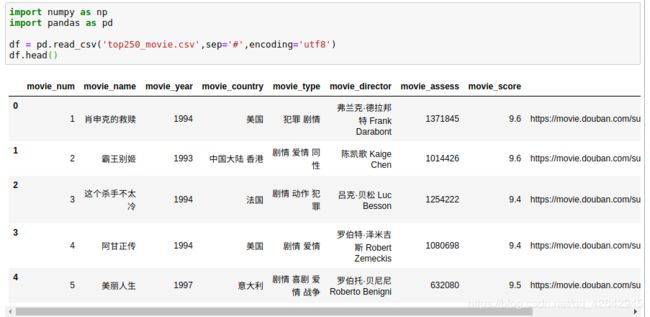
df = pd.read_csv('top250_movie.csv',sep='#',encoding='utf8')
df.head()
![]()
查看数据基本信息
df.info()

共有250行 10个字段,没有缺失值
重复值检查
df.duplicated().value_counts()
#检查是否有重名电影
len(df.movie_name.unique())

没有重复项也没有重名的电影
查看国家或地区参与电影制作的排名情况
对于 country 列,有些电影由多个国家或地区联合制作:
country =df['movie_country'].str.split(' ').apply(pd.Series)
country
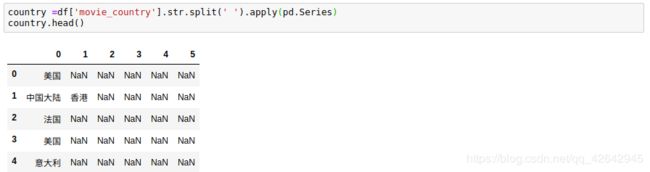
我们可以看到,有些国家甚至有6个国家或地区参与制作,对于这么多的空值,可以通过先按列计数,将空值 NaN 替换为“0”,再按行汇总。我们统计每个区域里相同国家的总数
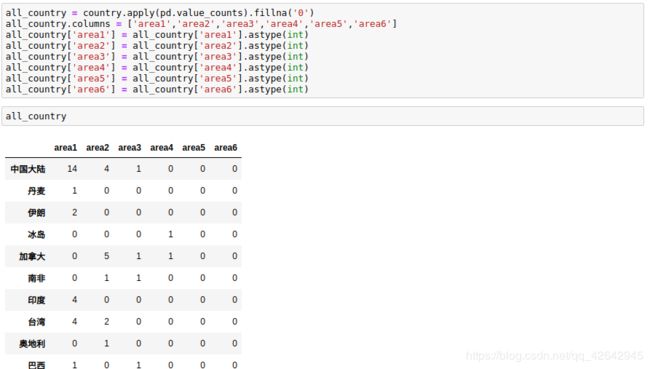
all_country = country.apply(pd.value_counts).fillna('0')
all_country.columns = ['area1','area2','area3','area4','area5','area6']
all_country['area1'] = all_country['area1'].astype(int)
all_country['area2'] = all_country['area2'].astype(int)
all_country['area3'] = all_country['area3'].astype(int)
all_country['area4'] = all_country['area4'].astype(int)
all_country['area5'] = all_country['area5'].astype(int)
all_country['area6'] = all_country['area6'].astype(int)
得到如下结果
接下来我们可以计算每个国家参与制作电影总数排名情况
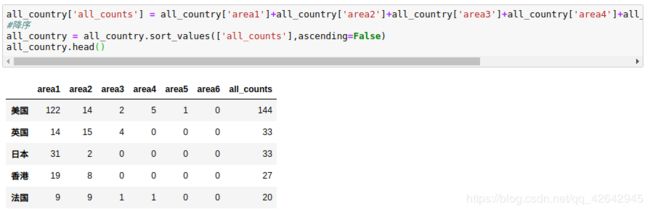
all_country['all_counts'] = all_country['area1']+all_country['area2']+all_country['area3']+all_country['area4']+all_country['area5']+all_country['area6']
#降序
all_country = all_country.sort_values(['all_counts'],ascending=False)
all_country.head()
得到一个国家或地区参与制作电影数的排名情况
关于电影类型的字段分析
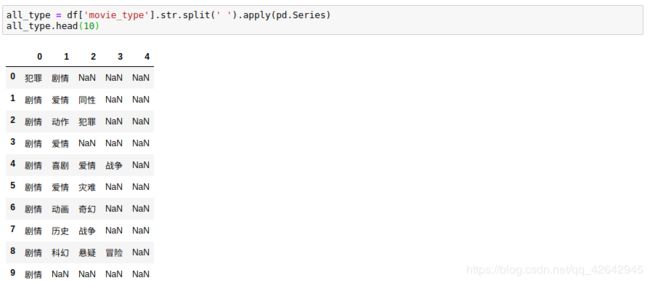
all_type = df['movie_type'].str.split(' ').apply(pd.Series)
all_type.head(10)
得到如下结果
all_type = df['movie_type'].str.split(' ').apply(pd.Series)
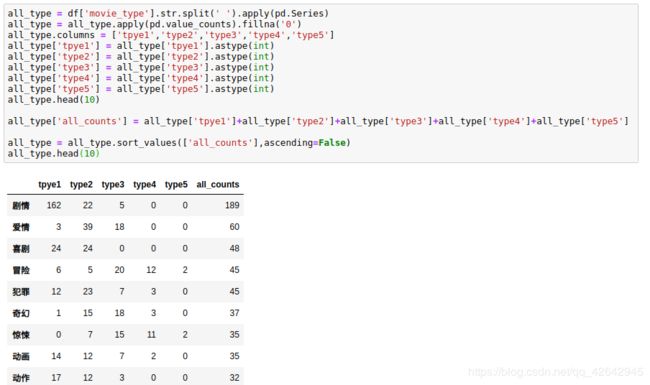
all_type = all_type.apply(pd.value_counts).fillna('0')
all_type.columns = ['tpye1','type2','type3','type4','type5']
all_type['tpye1'] = all_type['tpye1'].astype(int)
all_type['type2'] = all_type['type2'].astype(int)
all_type['type3'] = all_type['type3'].astype(int)
all_type['type4'] = all_type['type4'].astype(int)
all_type['type5'] = all_type['type5'].astype(int)
all_type.head(10)
all_type['all_counts'] = all_type['tpye1']+all_type['type2']+all_type['type3']+all_type['type4']+all_type['type5']
all_type = all_type.sort_values(['all_counts'],ascending=False)
all_type.head(10)
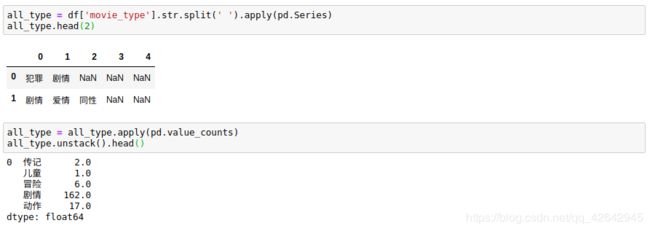
也可以通过 unstack 函数将行“旋转”为列,重排数据:
all_type = all_type.apply(pd.value_counts)
all_type.unstack().head()
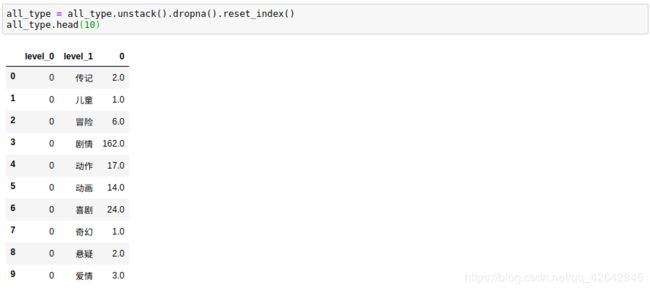
此时数据为 Series ,去掉空值,并通过 reset_index() 转化为 Dataframe :
all_type = all_type.unstack().dropna().reset_index()
all_type.head(10)
all_type.columns =['level_0','level_1','counts']
all_type_m = all_type.drop(['level_0'],axis=1).groupby('level_1').sum()
all_type_m.sort_values(['counts'],ascending=False)
#获取电影类型数量前10的类型
all_type_m.head(10)
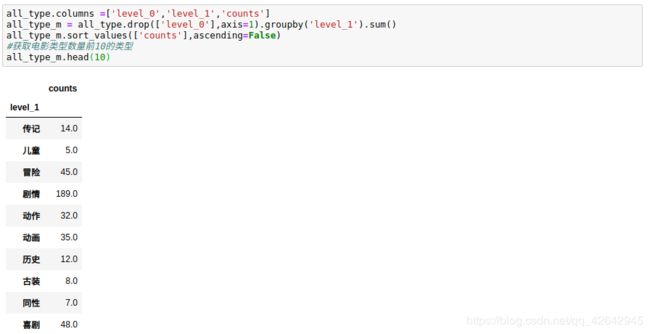
处理时间
year_= df['movie_year'].str.split('(').apply(pd.Series)[0].str.strip()
year_split = pd.to_datetime(year_).dt.year
df['movie_year'] = year_split
df.head(10)
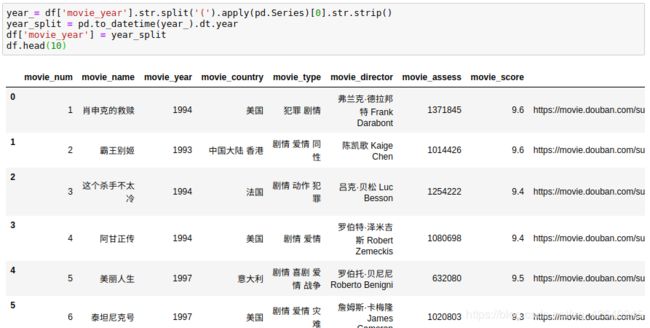
上榜次数最多的导演
# value_counts()返回一个Series 序列
director = df['movie_director'].value_counts()
#director.index 可以查看下标 director.values可以查看值
#series 转dataframe 可以使用字典的方式
myDirector = pd.DataFrame({'name':director.index,'counts':director.values})
#这样就生成了字段为‘name’ 和‘counts’的两列
得到结果如下
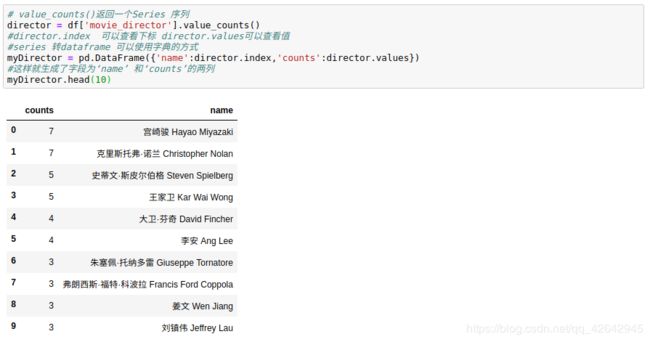
评分和排名的关系
#排名和评分的关系
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
#配置中文字体和修改字体大小
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['font.size'] = 20
plt.figure(figsize=(20,5))
plt.subplot(1,2,1)
plt.scatter(df['movie_score'],df['movie_num'])
plt.xlabel('movie_score')
plt.ylabel('movie rank')
#修改y轴为倒序
plt.gca().invert_yaxis()
#集中趋势的直方图
plt.subplot(1,2,2)
plt.hist(df['movie_score'],bins=15)
#电影排名和评分的相关性检测
df['movie_score'].corr(df['movie_num'])
#out[35]:-0.69237508495035771
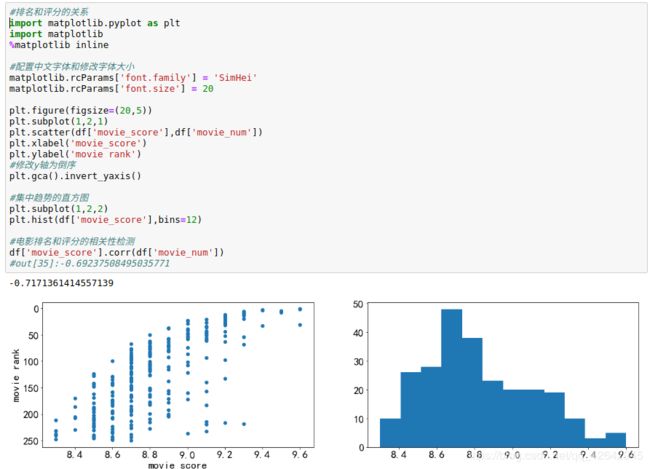
评分大多是集中在 8.3 - 9.2 之间,随评分的升高,豆瓣Top250排名名次也提前,Pearson相关系数为
-0.6923,为强相关性
国家或者地区上榜数的排名情况
country_rank = pd.DataFrame({'counts':all_country['all_counts']})
country_rank
country_rank.sort_values(by='counts',ascending=False).plot(kind='bar',figsize=(14,6))
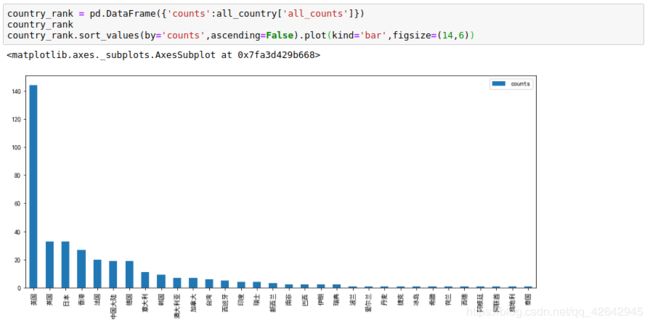
上榜数最多的国家是美国,中国大陆 排名第七