lvs之DR模式
介绍:
lvs即是linux虚拟服务器,是一个虚拟的服务器集群系统
特点:很好的伸缩性,很好的可靠性,很好的可管理性
四种模式:
VS/NAT:通过网络地址转换将一组服务器构成一个高性能,高可用的虚拟服务器
VS/DR:通过直接路由实现虚拟服务
VS/TUN:通过ip隧道实现虚拟服务器
还有二度开发的第四种模式(FULL NAT)
DR模式的简单原理:
客户端向目标vip发出请求,lvs接收 ,LVS根据负载均衡算法选择一台活跃的的节点,将此节点的ip所在网卡的mac地址作为目标mac地址,发送到局域网里
节点在局域网中收到这个帧,拆开后发现目标IP(VIP)与本地匹配,于是处理这个报文.随后重新封装报文,发送到局域网.此时IP包的目标ip是客户端,源ip是自己的vip地址。
原理图:

实验一:基础的轮询
1,实验主机
server1 172.25.254.1 调度器
server2 172.25.245.2 RS服务器
server3 172.25.254.3 RS服务器
server4 172.25.254.4 备用调度器
2,注意yum源的增加
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.254.154/rhel6.5/LoadBalancer
enable=1
gpgcheck=0
3,工具的安装
server1:yum install ipvsadm -y
4,添加策略
调度器server1:
添加ip号作为调度器
![]()
设为基本的轮叫的模式并查看

RS服务器server2和server3(两个配置相同):
安装http服务并开启http服务,同时编写测试页面

server3:添加调度器ip
![]()
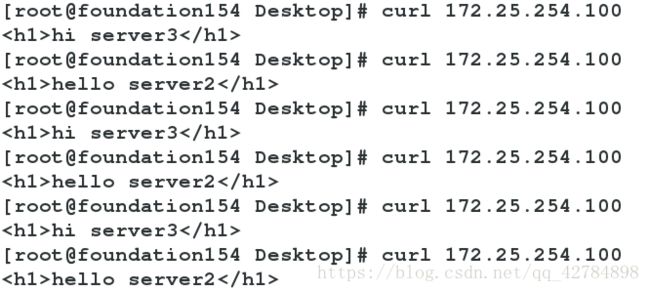
实验效果:实现两个服务器轮流服务
设置火墙:
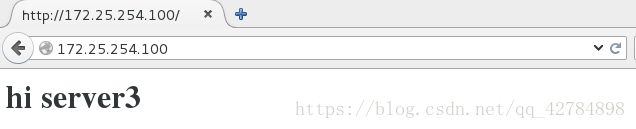
浏览器测试:

yum install arptables_jf -y
控制IN和OUT保证访问的是服务器本身并保存策略

ipvsadm -ln可以查看策略
现在即可通过测试端访问调度器,命令为curl 172.25.254.100,其中curl不受缓存影响
注意:这里为了测试结果,server2和server3的发布目录不一样,而实际上他们应该完全一样,即在一定的时间内访问两次淘宝,网页没有任何变化,而实际上服务器可能已经变化了
出现的问题
(1)当RS节点出现问题,还是会把会话连续转发到RS上
(2)当调度器出现问题,整个网络会出现故障
解决办法:
针对(1)所以需要一种健康检查机制定时检查RS是否正常,不正常的时候删除,恢复正常了再添加
针对(2)还需要再架一台调度器作为备用
所以需要lvs+keepalived配和,来实现RS节点健康检查和lvs的高可用功能
实验2:ldirectord服务,解决RS服务器挂掉问题
解决办法:当RS服务器出现问题,ldirectord进程将其从ipvs表中移除
而一旦realserver再次上线,ldirector会将其重新添加到ipvs表中
1)调度器server1:配置yum源
在原本的基础上家加入下面内容
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.254.154/rhel6.5/HighAvailability
enabled=1
gpgcheck=0

2)yum install ldirectord-3.9.5-3.1.x86_64.rpm -y
![]()
cp /usr/share/doc/ldirectord-3.9.5/ldirectord.cf /etc/ha.d/
cd /etc/ha.d/
vim ldirectord.cf

内容如下:
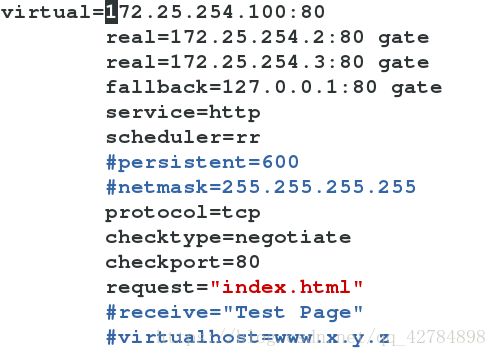
说明:fallback代表当后端没有正常的服务器,则走回环接口访问服务器本身
scheduler代表实施轮询策略
/etc/init.d/ldirectord start
注意:在生效以后,当清除策略,重启ldirectord上以后,策略重新启动

补充:rpm -qa xx查看是否安装 rpm -qpl xx 显示安装的位置
安装httpd服务并开启80端口,配置文件是/etc/httpd/conf/httpd.conf
![]()
![]()
写一个发布页面来鉴别啦比如:系统正在维护中.........
并且在本地测验一下效果如下:

宕掉其中一个时,依然正常工作,宕掉全部时,调度器可以工作
以上实现了安全检查,但是当调度器出现问题,那幺系统依旧崩溃
测试:
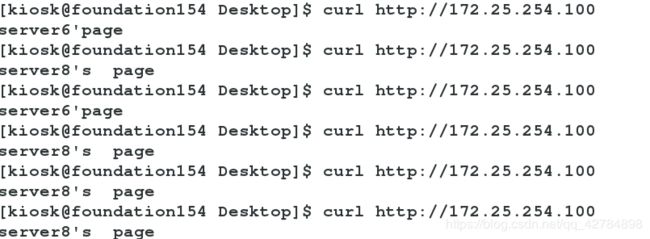
宕掉一个+宕掉全部:

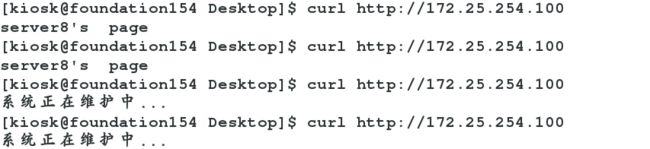
很顺利!but总是不是那幺顺利写到这里,记录一下:
问题是:ipvsadm -ln确实查询到两个服务器,但是做不到轮询,但是配置文件并没有做任何改变 怎麼肥四?
调度器查看是这样的:

本地访问server6是这样的:

但是物理机访问确是有问题的:

ldirectord本来就是用来踢除后台的链接不到的服务器,此时可以找到却访问不了为什幺不踢除呢,并显示调度器的页面呢?
另外打开server8是可以访问的,说明不是调度器的问题:图如下

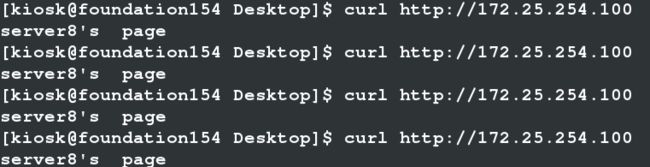
tell me why?若有缘看到这里,求解答,我还会回来的!
实验3:应用keepalived高可用集群管理实现两个调度器以主备方式进行工作
说明:因为ldirectord与keepalived存在冲突,所以必须将lidirectort停掉
获取源码文件,并用scp命令传给server1

server1获取keepalived文件并解压
yum install openssl-devel -y
server1:
yum install gcc -y当没有安装会出现一定的报错
进入解压目录进行编译./configure-->make-->make install
./configure --with-init=SYSV --prefix=/usr/local/keepalived
make进行编译
make install进行安装
做四项软链接
ln -s /usr/local/keepalived/etc/keepalived/ /etc/
ln -s /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
ln -s /usr/local/keepalived/sbin/keepalived /sbin/
ln -s /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
可以查看连接
![]()
加可执行权限

yum install mailx用于接收文件
配置文件:/etc/keepalived/keepalived.conf内容如下图(配置文件详解https://mp.csdn.net/postedit/98347222)
! Configuration File for keepalived
global_defs { 全局定义
notification_email { 设置报警邮箱
root@localhost
}
notification_email_from [email protected]
smtp_server 127.0.0.1 设置smtp server的地址
smtp_connect_timeout 30
router_id LVS_DEVEL #是Keepalived服务器的路由标识在一个局域网内,这个标识(router_id)是唯一的vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 { #VRRP实例定义区块名字是VI_1
state MASTER
interface eth0
virtual_router_id 51 #虚拟路由ID标识,这个标识最好是一个数字,在一个keepalived.conf配置中是唯一的, MASTER和BACKUP配置中相同实例的virtual_router_id必须是一致的.priority 100 #priority为优先级 越大越优先
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.100
}
}virtual_server 172.25.254.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 50
protocol TCPreal_server 172.25.254.6 80 {
weight 1
TCP_CHECK {connect_timeout 3
retry 3
delay_before_retry 3
}
}real_server 172.25.254.8 80 {
weight 1
TCP_CHECK {connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
删除原本的ip:ip addr del 172.25.254.100/24 dev eth0
编辑完配置文件,开启服务/etc/init.d/keepalived start
至此server1配置完成
备用的调度器server4:
yum源可以从server1上复制过来
yum install ipvsadm -y
四项连接

可以将配置文件直接从主调度器复制过来
模式改为BACKUP,优先级改变不要比主的优先级高不然会出现冲突


实验效果:
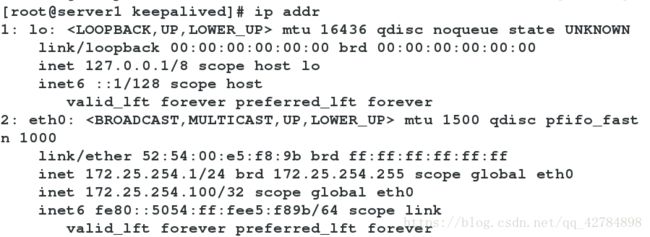

当调度器server1出现问题,查看server4的日志,记录由备用变为主要
(cat /var/log/messages 即可看到所处的主备,ip addr 即可看到VIP的漂移)
实验四:当备用调度器一直处于准备状态,造成资源浪费,现配置srever4与server1互为主备
互为主备模式,既维护系统安全,又不浪费资源
RS服务器server2和server3配置一样
RS服务器端server2:yum instll vsftpd
/ect/init.d/vsftpd start
cd /var/ftp/
touch server
调度器server1:
vim /etc/keepalived/keepalived.conf配置主要文件内容如下:
更改完配置文件请重启服务/ect/init.d/keepalived restart
ipvsadm -l查看策略
RS服务器server2:
ip addr add 172.25.254.200/32 dev eth0
vim /etc/sysconfig/arptables添加策略,内容如下
/etc/init.d/arptables_jf restart重启服务
arptables -L查看火墙策略
RS服务器server3与server2相同
测试结果:
在物理机上以lftp 172.25.254.200来测试结果
同时在server1上ipvsadm -lnc可以查看访问的哪个端口以及访问的次数
拓展:
解决多组Keepalived服务器在一个局域网的冲突问题
当在同一个局域网内部署了多组Keepalived服务器对,而又未使用专门的心跳线通信时,可能会发生高可用接管的严重故障问题。之前已经讲解过 Keepalived高可用功能是通过VRRP协议实现的,VRRP协议默认通过IP多播的形式实现高可用对之间的通信,如果同一个局域网内存在多组 Keepalived服务器对,就会造成IP多播地址冲突问题,导致接管错乱,不同组的Keepalived都会使用默认的224.0.0.18作为多播 地址。此时的解决办法是,在同组的Keepalived服务器所有的配置文件里指定独一无二的多播地址,配置如下:
global_defs { #全局配置
router_id LVS_19 #服务标识
vrrp_mcast_group4 224.0.0.19 #这个就是指定多播地址的配置
}
#提示:
1)不同实例的通信认证密码也最好不同,以确保接管正常。
2)另一款高可用软件Heartbeat,如果采用多播方式实现主备通信,同样会有多播地址冲突问题。
开发检测Keepalived裂脑的脚本
在备节点上执行脚本,如果可以ping通主节点并且备节点有VIP就报警,让人员介入检查是否裂脑。
#!/bin/bash
lb01_vip=192.168.0.240
lb01_ip=192.168.0.221
while true
do
ping -c 2 -W 3 $lb01_ip &>/dev/null
if [ $? -eq 0 -a `ip a | grep "$lb01_vip" | wc -l` -eq 1 ];then
echo "ha is split brain.warning."
else
echo "ha is OK"
fi
sleep 5
done
可以将此脚本整合到Nagios或Zabbix监控服务里,进行监控报警。