GAN,无监督深度学习新前景方法(1,2)
大家好,我是蜂口的龙鹏,在“陌陌”公司担任深度学习算法工程师,曾任职于360AI研究院,长期从事于图像算法处理和深度学习相关的工作。
撰写本手册,主要和大家来探讨GANs这样一种最具前景的无监督学习方法。 虽然生成对抗网络GANs(Generative adversarial networks)已经被提出来好几年了,但我依然对它非常怀疑。尽管生成对抗网络已经在 64x64 分辨率的图像上取得了巨大的进步,却依然无法打消我的疑虑,于是,我开始阅读了相关的数学书籍,我更加怀疑生成对抗网络事实上并没有学习到数据分布。但是这一点在今年有所改观,首先是新颖有趣的架构(如 CycleGAN)的提出和理论性的提升(Wasserstein GAN)促使我在实践中尝试了生成对抗网络,然后它们的效果还算可以,另外在两次应用过生成对抗网络之后,我开始被它深深折服,并且开始坚信我们必须使用生成对抗网络进行对象生成。
GANs的设计思想其实很简单,它就是用两个模型,一个生成模型,一个判别模型。判别模型用于判断一个给定的图片是不是真实的图片(判断该图片是从数据集里获取的真实图片还是生成器生成的图片),生成模型的任务是去创造一个看起来像真的图片一样的图片。而在开始的时候这两个模型都是没有经过训练的,这两个模型一起对抗训练,生成模型产生一张图片去欺骗判别模型,然后判别模型去判断这张图片是真是假,最终在这两个模型训练的过程中,两个模型的能力越来越强,最终达到稳定状态。GANs还可以学习模拟各种数据的分布,例如文本、语音和图像,因此在生成测试数据集时,它是非常有价值的。
如何构建GANs的生成与判别式模型?它的重要原理又是怎样的?它在数据生成、风格迁移和超分辨率重建方面的表现到底如何呢?
**一、**判别式模型和生成式模型
1.1 判别式模型
判别式模型,即Discriminative Model,又被称为条件概率模型,它估计的是条件概率分布(conditional distribution), p(class|context) 。
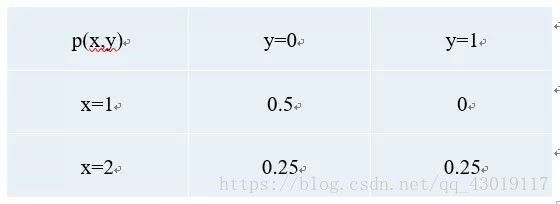
举个例子,我们给定(x,y)对,4个样本。(1,0), (1,0), (2,0), (2, 1),p(y|x)是事件x发生时y的条件概率,它的计算如下:

1.2 生成式模型
即Generative Model ,生成式模型 ,它估计的是联合概率分布(joint probability distribution),p(class, context)=p(class|context)*p(context) 。p(x,y),即事件x与事件y同时发生的概率。同样以上面的样本为例,它的计算如下:
1.3 常见模型
常见的判别式模型有Logistic Regression,Linear Regression,SVM,Traditional Neural Networks
Nearest Neighbor,CRF等。
常见的生成式模型有Naive Bayes,Mixtures of Gaussians, HMMs,Markov Random Fields等。
1.4 比较
判别式模型 ,优点是分类边界灵活 ,学习简单,性能较好 ;缺点是不能得到概率分布 。
生成式模型 ,优点是收敛速度快,可学习分布,可应对隐变量 ;缺点是学习复杂 ,分类性能较差。

上面是一个分类例子,可知判别式模型,有清晰的分界面,而生成式模型,有清晰的概率密度分布。生成式模型,可以转换为判别式模型,反之则不能。
**二、**GAN,即Generative Adversarial Net
它同时包含判别式模型和生成式模型,一个经典的网络结构如下。
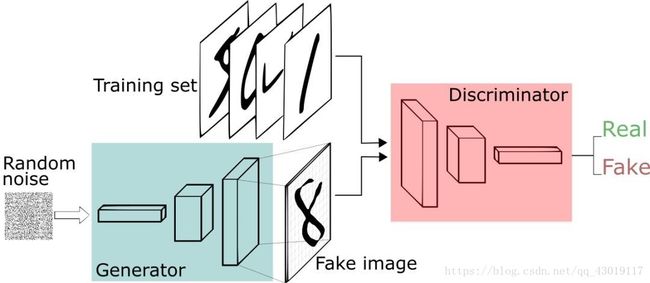
2.1 基本原理
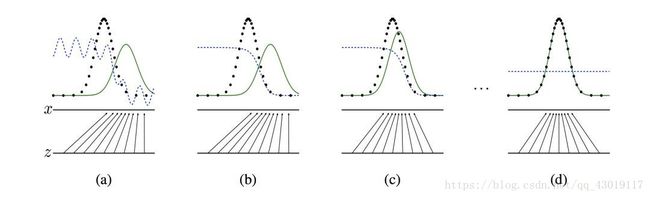
GAN的原理很简单,它包括两个网络,一个生成网络,不断生成数据分布。一个判别网络,判断生成的数据是否为真实数据。上图是原理展示,黑色虚线是真实分布,绿色实线是生成模型的学习过程,蓝色虚线是判别模型的学习过程,两者相互对抗,共同学习到最优状态。
2.2 优化目标与求解
下面是它的优化目标。
![]()
D是判别器,它的学习目标,是最大化上面的式子,而G是生成器,它的学习目标,是最小化上面的式子。上面问题的求解,通过迭代求解D和G来完成。
要求解上面的式子,等价于求解下面的式子。
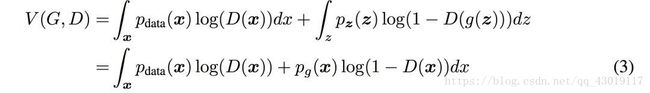
其中D(x)属于(0,1),上式是alog(y) + blog(1−y)的形式,取得最大值的条件是D(x)=a/(a+b),此时等价于下面式子。
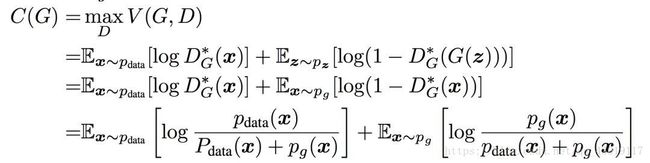
如果用KL散度来描述,上面的式子等于下面的式子。
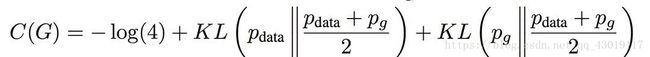
当且仅当pdata(x)=pg(x)时,取得极小值-log4,此时d=0.5,无法分辨真实样本和假样本。
GAN从理论上,被证实存在全局最优解。至于KL散度,大家可以再去补充相关知识,篇幅有限不做赘述。
2.3 如何训练
直接从原始论文中截取伪代码了,可见,就是采用判别式模型和生成式模型分别循环依次迭代的方法,与CNN一样,使用梯度下降来优化。

2.4 GAN的主要问题
GAN从本质上来说,有与CNN不同的特点,因为GAN的训练是依次迭代D和G,如果判别器D学的不好,生成器G得不到正确反馈,就无法稳定学习。如果判别器D学的太好,整个loss迅速下降,G就无法继续学习。
GAN的优化需要生成器和判别器达到纳什均衡,但是因为判别器D和生成器G是分别训练的,纳什平衡并不一定能达到,这是早期GAN难以训练的主要原因。另外,最初的损失函数也不是最优的,这些就留待我们的下篇再细讲吧,下面欣赏一下GAN的一些精彩的应用。
更多精彩分享内容,请翻阅下篇