【python--爬虫】彼岸图网高清壁纸爬虫
前言
你还在为壁纸太过老土被盆友嘲笑而苦恼吗?
你还在为找不到高清壁纸而烦恼吗?
你还在为壁纸网站的收费而感到囊中羞涩吗?
NO,NO,NO!!!
人生苦短,山东数十萌新变身高富帅的梦想,你可以复制!
是时候换个壁纸啦!
 展示一张天依小可爱的壁纸
展示一张天依小可爱的壁纸
前提准备
本次我们要爬取的网站是彼岸图网,网址链接:http://pic.netbian.com。
需要各位读者大大提前准备好以下环境:
1.python3.7(版本为3的就可以了)
2.火狐浏览器(这个版本没要求)
4.requests库(这个版本也没啥要求)
5.lxml库(博主使用的4.3.3)
网页分析
我们先打开彼岸图网,网址链接:http://pic.netbian.com。
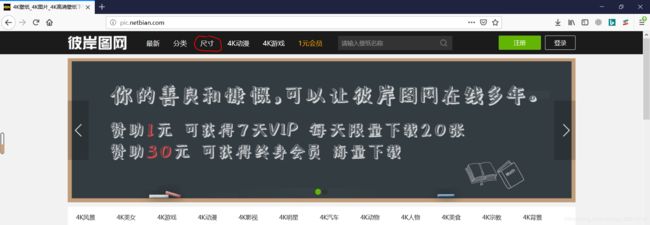 点击【尺寸】,然后选择【4K壁纸】,就可以打开这个页面,
点击【尺寸】,然后选择【4K壁纸】,就可以打开这个页面,
页面链接:http://pic.netbian.com/e/search/result/?searchid=1224
这个页面上的图片就是我们要爬取的图片。我们将这种页面叫做:主页面。
往下滑,可以看到一共有535页
![]() 我们点击第二页,看看url有啥变化
我们点击第二页,看看url有啥变化
![]()
再次点击第三页,
![]()
再点击第四页
![]()
发现一个规律,第n页的url就是
http://pic.netbian.com/e/search/result/index.php?page=n-1&searchid=1224
我们尝试通过这个规律,看看能不能通过url:
http://pic.netbian.com/e/search/result/index.php?page=0&searchid=1224
打开第一页
打开了,页面内容也是一致的。这么这个url规律是对的。我们把打开主页面的url叫做主页面url。
现在点击图片,打开图片详情页。一般我们把图片详情页叫做子页面,子页面的url叫做子url。
演示使用的url是:http://pic.netbian.com/tupian/24455.html
右键图片,【查看元素】可以跳转到图片的代码处
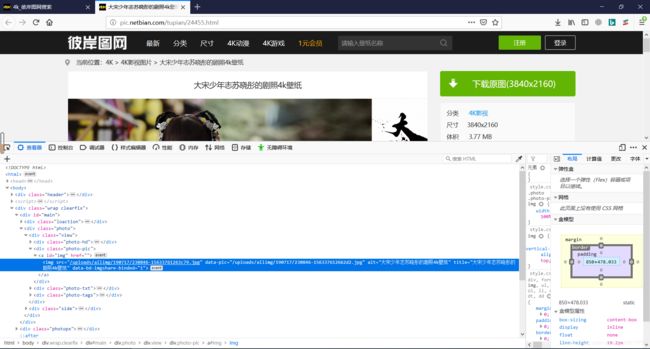 得到了图片的url: /uploads/allimg/190717/230846-15633761263c79.jpg
得到了图片的url: /uploads/allimg/190717/230846-15633761263c79.jpg
发现这个url不是一个完整的url。证明还需要知道一个主url。
注意:这里说的是主url,不是打开主页面的主页面url。一般网站的主url,就是网站的网址。
比如说当前的这个网站的网址是:http://pic.netbian.com,那么这个主url就是:http://pic.netbian.com
我们把主url和图片的url拼接到一起得到一个完整的url。
http://pic.netbian.com/uploads/allimg/190717/230846-15633761263c79.jpg,
在浏览器打开验证
成功打开了,证明url没问题。现在再去确认这个url是本来就存在于网页代码中,还是js加载出来的。
先返回子页面
接着在按【ctrl】+【u】,打开网页的源代码。
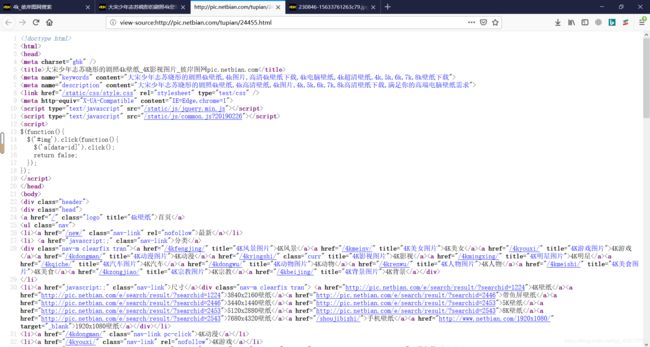 这么多,一行一行的找肯定不现实,我们使用页面查找功能,按【ctrl】+【F】调出查找功能。
这么多,一行一行的找肯定不现实,我们使用页面查找功能,按【ctrl】+【F】调出查找功能。
在输入框中输入我们之前提取出来的图片url【/uploads/allimg/190717/230846-15633761263c79.jpg】按确认进行查找
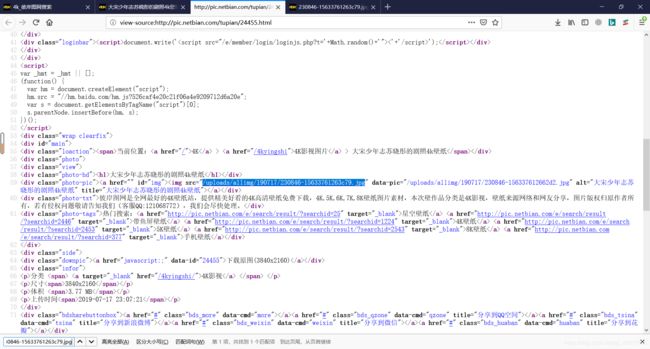 蓝色的部分就是找到的网址,可以证明图片的url就是存在于网页代码中的。
蓝色的部分就是找到的网址,可以证明图片的url就是存在于网页代码中的。
总结下:
主页面url的规律是:
第n页的url就是:http://pic.netbian.com/e/search/result/index.php?page=n-1&searchid=1224
由主页面可以得到图片详情页,我们要爬取的图片就存在于图片详情页的网页源代码中。
实战代码
首先我们在存放代码的文件夹中创建一个名为【img】的文件夹用于存放后面爬取到的图片
1.前提参数
我们先写上如下代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年7月21日
第一行是老生常谈的设置程序编码格式
第二行是记录作者信息
第三行是记录编写时间
2.导入模块
from lxml import etree
import requests
第一行的意思是从lxml模块中导入etree函数,用于解析网页代码,提取出我们想要的信息
第二行是导入requests模块,用于获取网页代码,下载图片等!
3.常用函数
main_url = 'http://pic.netbian.com' #主url,用于后期补齐图片url。
main_page_url = 'http://pic.netbian.com/e/search/result/index.php?page={}&searchid=1224'
#mian_page_url 主页面url,用于解析获取图片详情页的url,
#其中{}的作用是使用format函数将内容以字符串的形式添加到{}的位置
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',}
#请求头,用于后期访问网页,下载图片
这个我就不解释了,代码中#号后面的注释就是了!
偷个懒,相信各位大大,不会介意的(〃` 3′〃)
4.网页请求函数
def get_html(url):
"""定义一个用于获取网页代码的函数,调用时需要传递目标url"""
return requests.get(url,headers=header).content.decode('gbk')
定义一个名为get_html的函数,每次调用这个函数时需要传递一个url,作为要爬取的网页。
使用我们前面设置的变量 header作为爬取网页的请求头,将爬取到的内容解析为二进制格式。
使用decode函数将网页的二进制数据转码为gbk格式的文本数据,并将这个网页数据作为返回值弹出。
我们来测试下,尝试获取第十页的源代码
def get_html(url):
"""定义一个用于获取网页代码的函数,调用时需要传递目标url"""
return requests.get(url,headers=header).text
html = get_html(main_page_url.format(10))
print (html)
 出现这个黄颜色的框框是因为要输出的内容比较长,所以IDLE自动帮我们缩小了,是要双击黄颜色的框框就可以将缩略的内容显示出来。我们双击打开。
出现这个黄颜色的框框是因为要输出的内容比较长,所以IDLE自动帮我们缩小了,是要双击黄颜色的框框就可以将缩略的内容显示出来。我们双击打开。
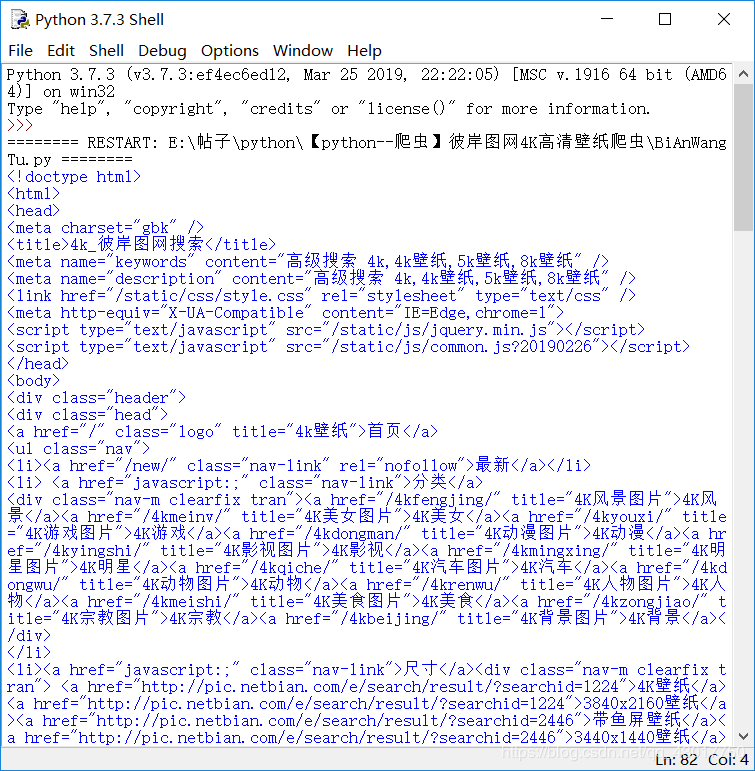 我们成功的获取到了网页代码,好棒的!给自己鼓个掌,呱唧呱唧!o( ̄▽ ̄)ブ
我们成功的获取到了网页代码,好棒的!给自己鼓个掌,呱唧呱唧!o( ̄▽ ̄)ブ
5.解析网页
即然我们将主页面的源代码获取下来了,现在还需要从主页面的源码中解析出来子页面的url,也就是我们说的图片详情页的url
def get_sub_url(html):
"""从主页面的源码中提取子页面的url"""
html_etree = etree.HTML(html)
sub_url = html_etree.xpath('//ul[@class="clearfix"]/li/a/@href')
return sub_url
首先我们定义了名为get_sub_url的函数用于从网页代码中获取子页面的url,每次调用时需要将主页面的源代码作为参数传入。
函数第一行我们将网页转为了etree格式的并将之存入变量html_etree
函数第二行我们使用xpath匹配出网页源代码中有着属性为【class=“clearfix”】的ul元素中的
li中的a元素中的href属性的值,并将匹配出来的url存入了变量sub_url
函数第三行我们将变量sub_url作为返回值弹出程序
我们来验证下
def get_sub_url(html):
"""从主页面的源码中提取子页面的url"""
html_etree = etree.HTML(html)
sub_url = html_etree.xpath('//ul[@class="clearfix"]/li/a/@href')
return sub_url
html = get_html(main_page_url.format(0))
urls = get_sub_url(html)
print (urls)
执行效果
['/tupian/24459.html', '/tupian/24458.html', '/tupian/24455.html', '/tupian/24454.html', '/tupian/24453.html',
'/tupian/24450.html', '/tupian/24452.html', '/tupian/24451.html', '/tupian/18363.html', '/tupian/24031.html',
'/tupian/24335.html', '/tupian/12356.html', '/tupian/21953.html', '/tupian/24411.html', '/tupian/21449.html',
'/tupian/22368.html', '/tupian/17785.html', '/tupian/24440.html', '/tupian/24438.html', '/tupian/24433.html',
'/tupian/12072.html']
>>>
可以看到我们获取出来的子url是不完整的,还需要补上我们的主url http://pic.netbian.com
6.补齐子页面url
我们使用一个for 循环补齐url
for url in urls:
sub_page_url = main_url+url
print (sub_page_url)
执行的效果
http://pic.netbian.com/tupian/24459.html
http://pic.netbian.com/tupian/24458.html
http://pic.netbian.com/tupian/24455.html
http://pic.netbian.com/tupian/24454.html
http://pic.netbian.com/tupian/24453.html
http://pic.netbian.com/tupian/24450.html
http://pic.netbian.com/tupian/24452.html
http://pic.netbian.com/tupian/24451.html
http://pic.netbian.com/tupian/18363.html
http://pic.netbian.com/tupian/24031.html
http://pic.netbian.com/tupian/24335.html
http://pic.netbian.com/tupian/12356.html
http://pic.netbian.com/tupian/21953.html
http://pic.netbian.com/tupian/24411.html
http://pic.netbian.com/tupian/21449.html
http://pic.netbian.com/tupian/22368.html
http://pic.netbian.com/tupian/17785.html
http://pic.netbian.com/tupian/24440.html
http://pic.netbian.com/tupian/24438.html
http://pic.netbian.com/tupian/24433.html
http://pic.netbian.com/tupian/12072.html
>>>
我们在浏览器中打开第一条url http://pic.netbian.com/tupian/24459.html
打开了,证明这些补齐后的子页面url是正确的。
7.访问子页面
现在我们再获取子页面的源代码,再前面的for循环中再添加一行代码
sub_html = get_html(sub_page_url)
sub_html = sub_html.encode('utf-8').decode('gbk')
将我们补齐后的子页面url作为调用前面定义的get_html函数的参数,并将下载的网页存储到变量sub_html中,我们执行看一下!
html = get_html(main_page_url.format(0))
urls = get_sub_url(html)
for url in urls:
sub_page_url = main_url+url
sub_html = get_html(sub_page_url)
print (sub_html)
执行后的结果
 8.提取子页面图片链接
8.提取子页面图片链接
现在我们也能获取到了子页面的源代码,是时候再编写一个函数提取出来子页面中的图片了
注意这个函数我们要写到for循环之前
def get_img_info(html):
"""从子页面的源码中提取图片url"""
html_etree = etree.HTML(html)
img_url = html_etree.xpath('//div[@class="photo-pic"]/a/img/@src')[0]
img_title = html_etree.xpath('//div[@class="photo-pic"]/a/img/@title')[0].replace(' ','').replace('《','').replace('》','').replace("(","").replace(")","").replace(":","").replace(":",'')
return img_url,img_title
我们创建一个名为get_img_info的函数,调用该函数时需要传递进来图片详情页的源码。
函数第一行我们将网页代码转为为了etree格式的,并将之保存到函数html_etree中。
函数第二行我们使用xpath匹配出了属性为【class=“photo-pic”】的【div】元素下的a元素下的img元素的src属性的值,由于xpath默认匹配出来的值是以列表的格式,所以我们要使用[0]将其匹配出来
并将其保存到变量img_url中。
函数第三行我们使用xpath匹配出了属性为【class=“photo-pic”】的【div】元素下的a元素下的img元素的title属性的值,由于xpath默认匹配出来的值是以列表的格式,所以我们要使用[0]将其匹配出来
由于图片名称中可能会有会有多余的空格,《,》所以我们使用replace函数将他们剔除掉!最后将其保存到变量img_title中
变量最后一行我们将图片的url和标题作为函数的执行结果弹出。
执行看下
html = get_html(main_page_url.format(0))
urls = get_sub_url(html)
for url in urls:
sub_page_url = main_url+url
sub_html = get_html(sub_page_url)
img_url,img_title = get_img_url(sub_html)
full_img_url = main_url + img_url
print (full_img_url,img_title)
我们将前面下载的子页面源码作为参数传入了我们定义的函数get_img_url中得到了img_url和img_title,图片的url和标题。由于图片的url不是完整的所以引申出了倒数第二行的代码,我们将main_url主url和img_url图片url拼接再一起,得到了完整的图片url,将其保存到full_img_url中。
执行后效果:
http://pic.netbian.com/uploads/allimg/190721/220511-156371791196e5.jpg KDADva守望先锋4k壁纸3840x2160
http://pic.netbian.com/uploads/allimg/190721/220015-15637176155637.jpg 阿狸插画4k原画壁纸
http://pic.netbian.com/uploads/allimg/190717/231857-15633767378c4f.jpg 大宋少年志赵简剧照4k壁纸
http://pic.netbian.com/uploads/allimg/190717/231654-1563376614357e.jpg 大宋少年志王宽的剧照4k壁纸
http://pic.netbian.com/uploads/allimg/190717/230846-15633761263c79.jpg 大宋少年志苏晓彤的剧照4k壁纸
http://pic.netbian.com/uploads/allimg/190717/230718-1563376038733a.jpg 大宋少年志周雨彤的剧照4k壁纸
http://pic.netbian.com/uploads/allimg/190717/230450-1563375890d74e.jpg 大宋少年志赵简4k壁纸3840x2160
http://pic.netbian.com/uploads/allimg/190713/104025-15629856250f21.jpg 刚起床的美女唯美插画4k动漫壁纸
http://pic.netbian.com/uploads/allimg/190713/104340-1562985820e760.jpg 受伤的天使唯美插画4k动漫壁纸
http://pic.netbian.com/uploads/allimg/190713/104217-156298573792c2.jpg 穿短裤少女唯美艺术插画4k壁纸
http://pic.netbian.com/uploads/allimg/180222/231102-151931226201f1.jpg lol娑娜大胸白丝4k壁纸
http://pic.netbian.com/uploads/allimg/190415/214606-15553359663cd8.jpg 女孩微笑蹲着水海岸海滩波浪风夜晚4k动漫壁纸
http://pic.netbian.com/uploads/allimg/190614/221508-15605217086e6f.jpg 少女女孩背部写真唯美艺术插画4k动漫壁纸
http://pic.netbian.com/uploads/allimg/170725/103840-150095032034c0.jpg 布兰德福德路作者TheWanderingSoul4K风景壁纸
http://pic.netbian.com/uploads/allimg/180826/113958-153525479855be.jpg 阿尔卑斯山风景4k高清壁纸3840x2160
http://pic.netbian.com/uploads/allimg/190706/165730-15624034501cdb.jpg dva可爱女生装4k手机壁纸竖屏
http://pic.netbian.com/uploads/allimg/180718/135924-15318935643369.jpg 克拉女神江琴居家沙发养眼美腿美女4k壁纸
http://pic.netbian.com/uploads/allimg/181004/202029-1538655629aa26.jpg 尤果网美女赵智妍4k壁纸
http://pic.netbian.com/uploads/allimg/180128/113416-1517110456633d.jpg 糖果性感美女4k壁纸
http://pic.netbian.com/uploads/allimg/190713/100525-15629835259f05.jpg 克拉女神-慕菲含情凝睇4k美女壁纸3840x2160
http://pic.netbian.com/uploads/allimg/190713/100152-1562983312a505.jpg 克拉女神-蓓颖风度娴雅4k美女壁纸
>>>
- 下载并保存图片
我们现在获取了图片的url和标题的,成败就看这最后一哆嗦了!
def save(url,title):
"""下载并保存图片"""
img = requests.get(url,headers=header).content
img_name = 'img/'+title+'.jpg'
with open (title,'wb') as save_object:
sasve_object.write(img)
定义了一个函数save,用于下载并保存参数。调用时需要传递图片的url和图片的名称。
函数第一行我们使用requests的get方法下载图片,请求的url是图片的url,请求头是我们前面设置的header,将下载到内容以二进制的形式保存到变量img中。
函数第二行我们使用’img/’+图片名称+’.jpg’保存到变量img_name中,作为保存图片的名称
倒数两行我们以二进制的形式保存了图片
执行的结果:

10.爬取全部页面的图片
最后我们修改for循环,让程序能爬取全部页面的图片。
for number in range(533):
html = get_html(main_page_url.format(number))
print ("[+]正在爬取第{}页".format(number))
urls = get_sub_url(html)
for url in urls:
sub_page_url = main_url+url
sub_html = get_html(sub_page_url)
img_url,img_title = get_img_info(sub_html)
full_img_url = main_url + img_url
save(full_img_url,img_title)
我们使用for循环生成了0到532的数字用于补齐主页面的url,相当于我们爬取了全部页面的图片
完整代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年7月21日
from lxml import etree
import requests
main_url = 'http://pic.netbian.com' #主url,用于后期补齐图片url。
main_page_url = 'http://pic.netbian.com/e/search/result/index.php?page={}&searchid=1224'
#mian_page_url 主页面url,用于解析获取图片详情页的url,
#其中{}的作用是使用format函数将内容以字符串的形式添加到{}的位置
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',}
#请求头,用于后期访问网页,下载图片
def get_html(url):
"""定义一个用于获取网页代码的函数,调用时需要传递目标url"""
return requests.get(url,headers=header).content.decode('gbk')
def get_sub_url(html):
"""从主页面的源码中提取子页面的url"""
html_etree = etree.HTML(html)
sub_url = html_etree.xpath('//ul[@class="clearfix"]/li/a/@href')
return sub_url
def get_img_info(html):
"""从子页面的源码中提取图片url"""
html_etree = etree.HTML(html)
img_url = html_etree.xpath('//div[@class="photo-pic"]/a/img/@src')[0]
img_title = html_etree.xpath('//div[@class="photo-pic"]/a/img/@title')[0].replace(' ','').replace('《','').replace('》','').replace("(","").replace(")","").replace(":","").replace(":",'')
return img_url,img_title
def save(url,title):
"""下载并保存图片"""
img = requests.get(url,headers=header).content
img_name = 'img/'+title+'.jpg'
with open (img_name,'wb') as save_object:
save_object.write(img)
for number in range(533):
html = get_html(main_page_url.format(number))
print ("[+]正在爬取第{}页".format(number))
urls = get_sub_url(html)
for url in urls:
sub_page_url = main_url+url
sub_html = get_html(sub_page_url)
img_url,img_title = get_img_info(sub_html)
full_img_url = main_url + img_url
save(full_img_url,img_title)