大数据分析工程师入门13-Azkaban调度系统

导语
通过前面12篇文章的学习,相信大家对于数据分析工作中所有可能用到的基础技能点有了一个较全面的了解。
日常工作中,需求一般分两种,一种是临时需求,比如为了评估某个特定功能的统计,可以理解为一次性需求。还有一种就是一些常规性的指标统计,业务方需要随时查看最新数据的需求,这样的需求就需要借助任务调度平台的帮助了。
本文将会给大家从如何使用的角度讲解任务调度平台Azkaban。
所谓任务调度平台,可以简单理解为,就是支持上传目标任务,支持设置定时,并按定时设置周期性运行统计任务的平台。当然,它还有很多其他功能,比如支持作业编排,支持设置作业依赖,支持进行监控预警等,本文也会提及到部分相关概念,但不会深入讲解,感兴趣的小伙伴可自行查阅有关文档了解一下。
01
常用的调度框架及其对比
常用的调度平台框架有Oozie、Airflow、Zeus、Rundeck、Azkaban 等。
几种调度系统简单对比:
Oozie 目前是托管在 Apache 基金会的,开源。通过 XML 文件来定义 DAG依赖,作业配置复杂。
Airflow 目前是托管在 Apache 基金会的,开源。python 语言开发,通过 python脚本配置作业,学习成本较高。
Zeus 阿里开源的基于 Hadoop 平台的开源工作流调度系统,文档缺少,目前不再维护。
Rundeck 单机部署,分布式指令,没有清晰的作业 DAG 图。
Azkaban 由 Linkedin 公司推出的一个批量工作流任务调度器,通过 KV 文件格式来建立任务之间的依赖关系 。
Azkaban 优势:
提供功能清晰,简单易用的 Web UI 界面;
作业配置简单,任务作业依赖关系清晰;
提供可扩展的组件,原生支持 command、Java、Hive、Pig、Hadoop;
基于 Java 语言开发,易于二次开发。
02
Azkaban简介
在实际给大家演示如何使用Azkaban之前,先就Azkaban的一些基本概念进行简单介绍(下图是Azkaban登陆后的界面),这些概念在日常工作中会经常提及到,也是为给后续操作演示奠定基础。
2.1Project、Flow、Job
Project意为项目,登陆Azkaban,首先看到的就是项目页面。一个项目里允许上传一个zip包,zip应包含*.job运行作业所需的文件。
zip包上传成功以后,会看到一个个Flow,这些Flow下均包含一个或多个Job。
Azkaban可以设置一系列的运行参数来控制job运行的行为方式和传递执行需要的参数,如执行时的代理用户、失败邮件的收件人列表、用户自定义参数、当前时间等。通常情况下,我们会通过properties文件和job文件来设置参数,那它们是如何生效的呢,我们用下图来做个说明。
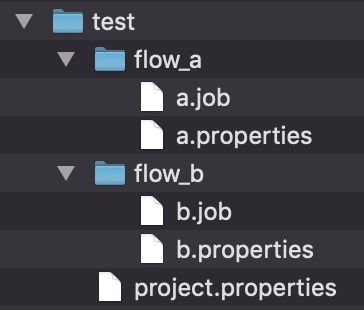
上图展示的是一个test工程的目录结构,在test目录下有个project.properties文件,这个文件内设置的参数对所有同级及子目录中的job都有效,即对flow_a和flow_b的job都生效。我们可以看到flow_a和flow_b目录下也各有一个properties文件,这两个文件同样是对同级以及子目录下的job生效。所以,a.properties文件对a.job同样生效,那么问题来了,既然project.properties文件和a.properties文件都对a.job有效,如果出现了同名参数会怎样?
答案是Azkaban采取了就近原则,谁离job近就会用谁的参数,所以a.propertis文件中的参数会覆盖project.properties文件中的同名参数。
除了properties文件外,job文件内也可以定义参数或属性,在这里定义的参数或属性优先级最高。这里我们要说明下在properties文件和在job文件中定义参数或属性的不同之处。
对比点 |
properties文件 |
job文件 |
作用域 |
同级目录及子目录下的所有job |
当前的单个job |
优先级 |
就近原则,离job越近优先级越高 |
优先级最高 |
运行时修改方式 |
直接修改运行界面的Flow Parameter即可生效 |
修改Flow Parameter不会生效,需要编辑job属性才可以 |
Scheduler是Azkaban的调度模块,负责作业的定时调度管理与运行,调度的最小单位是Flow。
这里要特别说明一下一个曾经遇到的坑。
如果先设置了Flow的定时调度,后又针对Flow中的某个Job设置了Scheduler,该Job的设置会覆盖之前Flow的设置,由于给单个Job设置调度时间的时候没有选中其余任务,于是会发生以后该调度流只有这一个Job调度执行,该Flow中的其余Job均不会定时运行。发生这个问题的原因就是因为调度的最小单元是Flow。
常用的Azkaban操作
以创建几个有依赖关系的Job文件上传到Azkaban上进行调度设置并执行为例,逐步讲解常用的Azkaban操作。
在这之前,先给大家将整个流程简单讲解一下,然后再带领大家来看具体的实际操作步骤。
第1步:创建Job文件
通常情况下,每一个Job文件都是对应着一个具体的统计任务(下文示例每个Job是直接打印相应字符串),这些Job之间有可能存在依赖关系,即某个任务的统计需要依赖上一个任务的执行结果等。
第2步:打包上传
工作中,统计程序和Job建好后,就将整个工程打成zip包,登陆Azkaban,将zip包上传到对应的Project中。上传成功后,就可以看到一个个的Flow自上而下呈现在眼前。
第3步:运行
可以试运行一下你的统计任务,点击整个Flow的Execute Flow就会整个Flow开始执行,点开Flow,找到下方对应的某个任务,点击Run Job,该Job就会开始执行。
第4步:查看任务执行情况
在任务执行过程中,可以进入Executing页面,查看任务执行情况。
第5步:设置调度
任务试运行成功,结果经验证是正确的情况下,就可以为整个Flow设置调度时间了,设置完成后,Azkaban以后就会根据调度时间周期性的自动运行这些统计任务。
创建示例Job文件及文件内容如下:
start.job
type=noopfirst.job
type=command
command="echo first"
dependencies=startsecond.job
type=command
command="echo second"
dependencies=start
three.job
type=command
command="echo third"
dependencies=startfour.job
type=command
command="echo fourth"
dependencies=startend.job
type=noop
dependencies=first,second,three,four
上面示例Job文件中总共包含三个参数,type、command和dependencies。type指定Job的类型,比如type=command,表示命令类型,type=noop是一个空操作,当然,还有其他赋值,读者可自行了解一下。command表示具体执行的指令。dependencies指定依赖的job。
由于该示例不是基于具体项目工程,也不涉及具体统计任务,只是为了示例如何使用Azkaban,所以是将这些Job文件放在一个文件夹内,直接打包生成zip压缩文件,然后上传到azkaban的Project中。
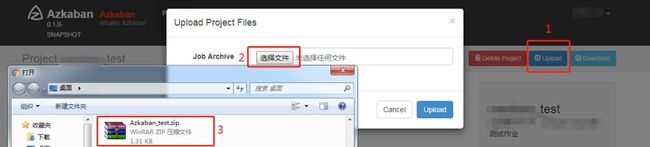
登录Azkaban,进入一个事先建好的测试Project,将zip包如下图1、2、3步上传。
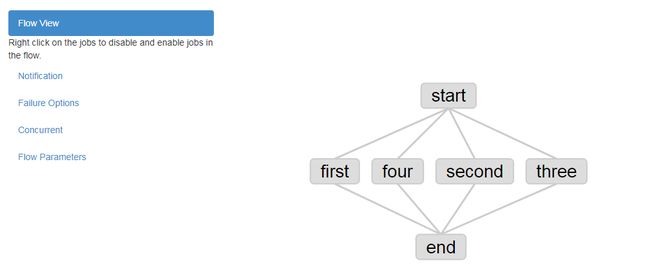
上传结果如下,在Azkaban页面上可以看到该Flow,点击Flow,将展开看到具体的一个个Job,可以看到它们之间存在着层级缩进,代表着自下而上的依赖关系:
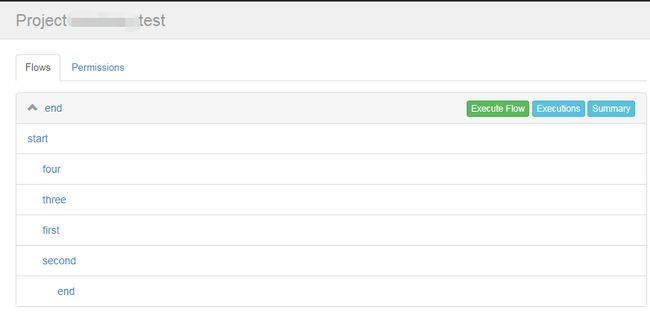
运行可以整个Flow统一执行,点击标记1,也可以选择单独运行某个job,点击标记2:
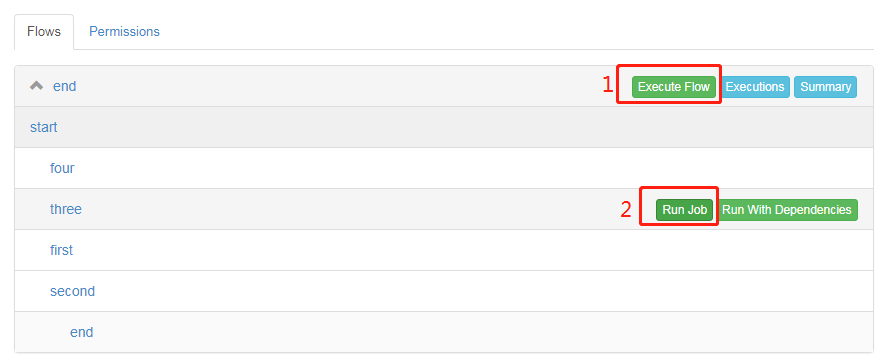
点击标记1后,弹出界面如下,所有job均被选中:
点击标记2后,弹出界面如下,只有目标job选中:
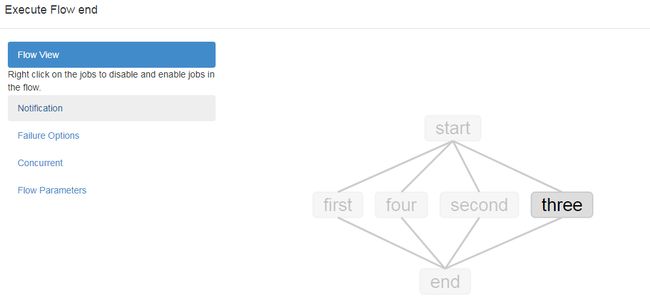
如果想一次执行两个job,可以在点击单个Job进行执行时,弹出的界面点击另一个想执行的job,右键选择enable,甚至可以enable其父节点,子节点,依赖节点,所有节点等等,大家可实际操作一下,想执行三个、四个job同样操作即可。
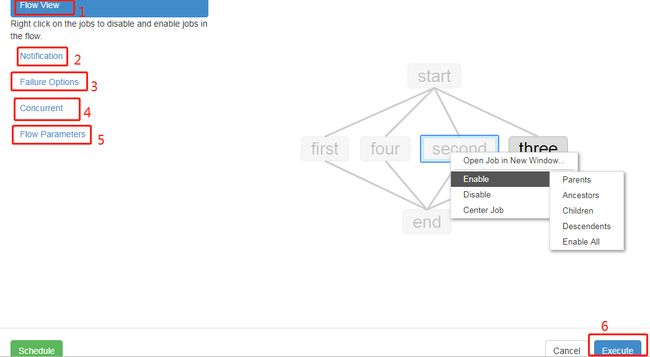
上图界面中左侧的六个选项,功能一一给大家解释一下:
标记1就是当前所选中的目标执行任务的预览图,可以重新设置所需执行任务。
标记2是设置邮件通知,当任务执行失败或者成功时,将邮件发给所填邮箱。
标记3设置当Flow当中有一个任务执行失败时,其余任务怎么处理,可选择全部取消、只执行完已经开始的任务或者执行完所有不受影响的任务。
标记4当一个Flow正在执行中时,被再次点击执行操作时,新起的任务进程可选择设置为照样执行或跳过不执行或待原先的任务执行完再运行。
标记5输入任务执行所需的参数,如日期。
标记6点击运行。
任务开始执行以后,可以查看任务执行情况。
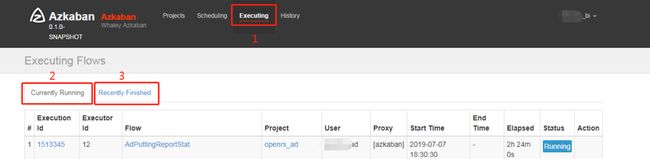
点击标记1处,弹出如图界面,标记2下面都是正在运行中的任务,可通过搜索找到你的目标任务,如果在正运行的任务中没找到,可点击标记3查看已完成的任务。
如果试运行的任务没有问题,那么就可以设置定时调度,让其依照调度时间运行了。
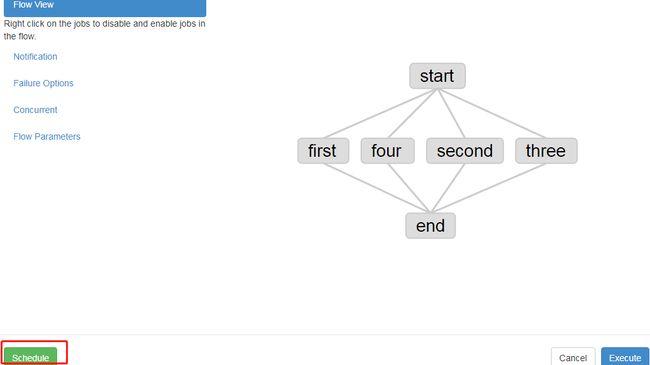
点击标记处,弹出调度设置界面,修改标记1处Hours中的值为4,Min为30,则表示以后每天的凌晨4:30点该Flow都将自动执行。
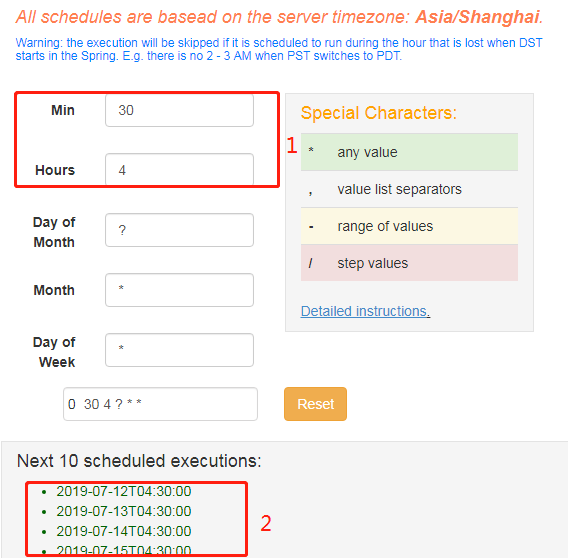
标记2处可以预览接下来的10个具体调度时间,点击调度设置界面右下角的Schedule,则调度设置成功。
3.6修改任务调度
如果要修改所设置Flow或Job的调度时间,依然如上步骤进入调度设置界面,直接重新填写调度时间,点击右下角的Schedule的即可。
如果想查看下某个Flow或者Job的调度,可点击如下标记1,进入调度查看界面,Ctrl+F搜索目标Flow或Job。标记2处即可看到所设调度时间。
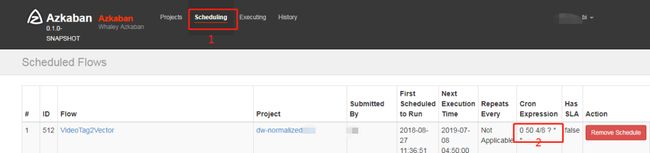
如果想删除该调度,点击右侧的Remove Schedule。
还有一种查看调度时间的方式,进入具体Project节目,找到目标Flow,点击Summary。
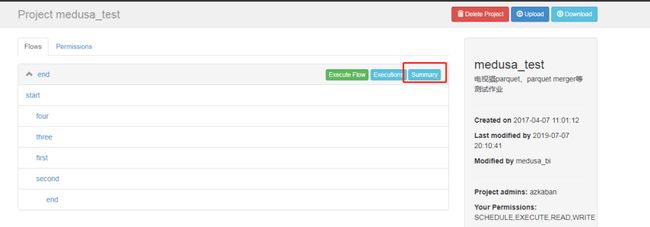
进入Summary页面,标记处可看到所设置的调度时间,同样可点击Remove Schedule,删除调度。
日常工作中失败任务处理
上一章节主要针对如何创建一个完整的任务调度进行了讲解演示。接下来,讲解一下调度中的任务执行失败时如何处理。
4.1失败记录定位
上文有提到,可为Flow或Job设置失败邮件通知,这样可帮助我们定位所运行失败的任务,在History中输入任务名称搜索执行失败的记录。如果没有设置失败邮件,只能直接进入History进行查找了。
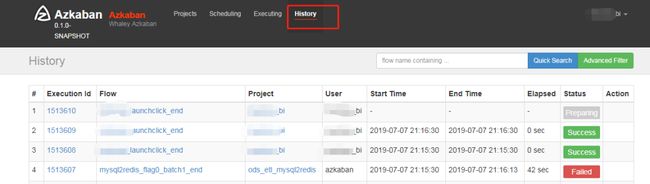
4.2失败信息查看
找到失败任务的执行记录后,点击图中的该失败任务的Execution Id进入任务具体执行记录界面,在Job List中找到Failed的任务,点击Details,进入Job Logs页面查看详情。
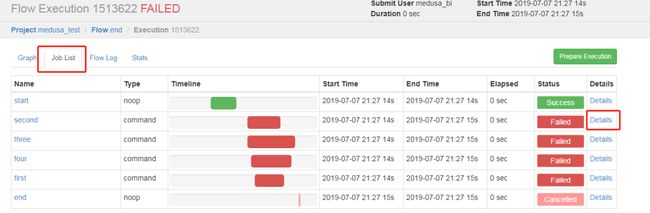
Job Logs里可以找到具体错误信息。如果任务类型是Yarn,那么Job Logs可找到报错任务的Application Id,如application_1562251516478_13934。然后,到Yarn平台输入该Application Id,查看报错详细信息。
总结
本文主要介绍了任务调度平台Azkaban的一些简单概念和实际如何创建和设置一个调度任务,以及如何针对报错任务进行问题排查。
作为数据分析入门课程,希望通过这篇文章,让大家对Azkaban有一个最基础的了解。
-end-
