HBase读写数据原理
1 读流程
HBase读数据流程如图1所示
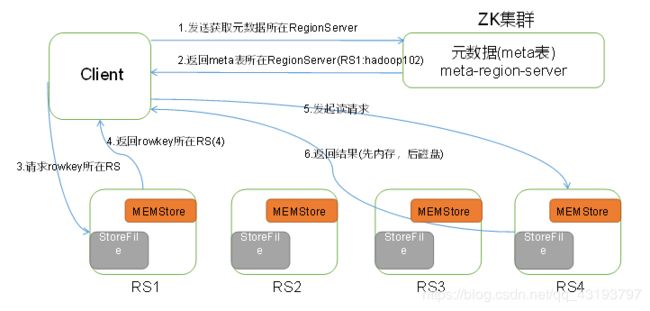
图1 所示 HBase读数据流程
1)Client先访问zookeeper,从meta表所处位置(ip),
2)访问meta表,然后读取meta表中的数据。meta中又存储了用户表的region信息;
3)根据namespace、表名和rowkey在meta表中找到对应的region信息;
4)找到这个region对应的regionserver;
5)查找对应的region;
6)先从MemStore找数据,如果没有,再到BlockCache里面读;
7)BlockCache还没有,再到StoreFile上读(为了读取的效率);
8)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
2 写流程
Hbase写流程如图2所示
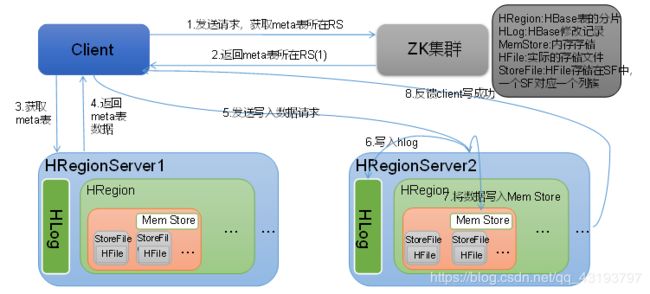
图2 HBase写数据流程
1)Client先访问zookeeper,从meta表所处位置(ip),
2)访问meta表,然后读取meta表中的数据。meta中又存储了用户表的region信息;
3)根据namespace、表名和rowkey在meta表中找到对应的region信息;
4)找到这个region对应的regionserver;
6)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复;
7)HregionServer将数据写到内存(MemStore);
8)反馈Client写成功。
3 数据Flush过程
当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
有 3 个条件满足任意一个都可以触发 flush:
-
当一个 RegionServer 中的所有 MemStore 的大小只和超过了堆内存的 40%. 则这个 RegionServer 中所有的 MemStore 一起刷到 HFile 中
-
当有任何一个 MemStore 的存活时间超过了 1h, 则这个 RegionServer 中所有的 MemStore 一起刷到 HFile 中.
-
单个region里多个memstore的缓存大小,超过那么整个HRegion就会flush,默认128M
4 数据的合并过程
由于前面的刷写过程的存在, 有可能会导致磁盘上有比较多的 HFile 小文件, 而 HDFS 并不适合存储小文件, 所以就存在了一个小文件合并的过程.
有 2 种合并:
- 小和并(Minor Compaction): 当一个store里面允许存的HFile的个数,超过这个个数会被写到一个新的HFile里面,也就是每个region的每个列族对应的memstore在flush为HFile的时候,默认情况下当超过3个HFile的时候就会对这些文件进行合并重写为一个新文件,设置个数越大key减少触发合并的时间,但是每次合并的时间就会越长
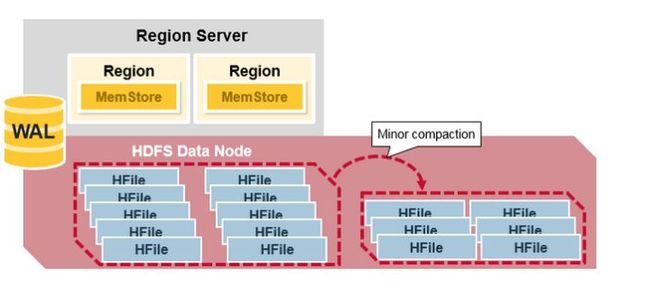
- 大合并(Major Compaction): Major compaction 指一个 region 下的所有 HFile 做归并排序, 最后形成一个大的HFile. 这可以提高读性能.
但是, major compaction重写所有的Hfile, 占用大量硬盘IO和网络带宽. 这也被称为写放大现象(write amplification)
Major compaction 可以被调度成自动运行的模式, 但是由于写放大的问题(write amplification), major compaction通常在一周执行一次或者只在凌晨运行.
此外, major compaction的过程中, 如果发现region server负责的数据不在本地的HDFS datanode上, major compaction除了合并文件外, 还会把其中一份数据转存到本地的data node上.
5 Region 拆分
最初, 每张表只有一个 region, 当一个 region 变得太大时, 它就分裂成 2 个子region.
2个子 region, 各占原始 region 的一半数据, 仍然被相同的 region server管理.
然后Region server向HBase master节点汇报拆分完成.
如果集群内还有其他 region server, master 节点倾向于做负载均衡, 所以master节点有可能调度新的 region 到其他 region server, 由其他 region 管理新的分裂出的region.