自然语言处理(NLP)-----文本分类、文本生成实践(学习笔记)
本文是基于 Emmanuel Ameisen 的 Concrete solutions to real problems的学习笔记(翻译+整理+扩充),代码部分根据自己的环境进行了微改。此笔记适用于对于机器学习和Python应用有基本了解的人。本人环境是python3.6。本程序基于jupyter notebook。
目前现存很多NLP的技术与工具,但聚类和分类永远是我们在面对这类问题时会首先考虑的手段。这两种方法不仅使用简单,而且可帮助企业在一定程度上快速的初步解决一些问题:
- 怎样自动的区分不同类型的语句?
- 怎样从数据中找出与给定语句意义相似的语句?
- 怎样从语句中抽取并表示出相对完善而简明的语意以适用于一系列的各种应用?
- 最重要的是,怎样快速判断这些应用在你的数据之上是能够实现的?
下面作者给出文本内容分类的清晰简明的指南。一、二、部分介绍了文本分类,三部分简要介绍了文本生成。文中代码里均可直接复制按顺序运行,用到的模块如果没有需要自行下载。
文章目录
- 一、 数据
- 1. 数据清理
- 2. 分词处理
- 二、 算法
- 1. bag of words counts
- 2. TFIDF Bag of Words
- 3. word2vec
- 4. CNN
- 三、文本生成
- 四、总结
一、 数据
数据来自于 Figure Eight 中的 Disasters on social media,其中包含了10000多条包含各种跟灾难有关的关键词的推特,但这些词同时也可能并不是形容灾难的(比如用来形容心情等等),我们的任务是通过自然语言处理来让计算机可以识别出这条推特是否是形容一场灾难(疾病爆发,恐怖袭击等),从而发出预警并提升相关部门的反应速度。
1. 数据清理
导入所需要的基本库:
import keras
import nltk
import pandas as pd
import numpy as np
import re
import codecs
import warnings
warnings.filterwarnings('ignore')
从网上下载数据并把无法解码的地方用“?”代替并另存为’socialmedia_relevant_cols_clean.csv’:
input_file = codecs.open('socialmedia-disaster-tweets-DFE.csv',"r",encoding='utf-8',errors='replace')
output_file = open('socialmedia_relevant_cols_clean.csv','w', encoding='utf-8')
def sanitize_characters(raw, clean):
for line in input_file:
output_file.write(line)
sanitize_characters(input_file,output_file)
留下我们需要的字段,“text” 和 “choose_one”,分别为推特的内容及标签。标签有三个,分别是“Not Relevant”,“Relevant”,以及“Can’t Decide”。分别为“不相关”,“相关”,以及“无法确定”。并新增一个“class_label”字段来用数字表示这三个标签,0表示不相关,1表示相关,2表示无法确定。
questions = pd.read_csv('socialmedia_relevant_cols_clean.csv')
questions = questions[['text', 'choose_one']]
A = {'Not Relevant':0,'Relevant':1,"Can't Decide":2}
for i in A:
questions.loc[questions.choose_one==i,'class_label'] = int(A[i])
questions.head()
把网址(http及后面的东西)和“@”后面的东西(一般是用户名)删除掉,因为这些信息一般跟语义本身没什么关系。然后把“@”替换为 “at”,因为有人用“@”来表示“在…地方”。再把各种标点符号替换为空格以方便处理。最后把所有的内容都用小写表示(大小写对语义一般没什么影响)。把清理后的数据另存为’clean_data.csv’。
def standardize_text(df, text_field):
df[text_field] = df[text_field].apply(lambda x: re.sub(re.compile(r'http\S+'), '',x))
df[text_field] = df[text_field].apply(lambda x: re.sub(re.compile(r'http'), '',x))
df[text_field] = df[text_field].apply(lambda x: re.sub(re.compile(r'@\S+'), '',x))
df[text_field] = df[text_field].apply(lambda x: re.sub(re.compile(r'@'), 'at',x))
df[text_field] = df[text_field].apply(lambda x: re.sub(re.compile(r'[^A-Za-z0-9(),!?@\'\`\"\_\n]'), ' ',x))
df[text_field] = df[text_field].str.lower()
return df
questions = standardize_text(questions,'text')
questions.to_csv('clean_data.csv', encoding='utf-8')
questions.head()
2. 分词处理
首先看一下数据的分布:
clean_questions = pd.read_csv("clean_data.csv")
clean_questions.groupby('class_label').count().head()
结果如图:
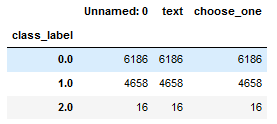 可以看出数据偏斜不严重,“相关”和“不相关”两组几乎均衡。
可以看出数据偏斜不严重,“相关”和“不相关”两组几乎均衡。
接下来是把句子转化为算法能够理解的形式。首先进行分词处理。
新建一个分词字段显示推特内容分词处理后的结果:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
clean_questions.loc[:,'tokens'] = clean_questions['text'].apply(tokenizer.tokenize)
clean_questions.head()
查看总词数及词典大小:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
all_words = [word for tokens in clean_questions['tokens'] for word in tokens]
sentence_lengths = [len(tokens) for tokens in clean_questions['tokens']]
VOCAB = sorted(list(set(all_words)))
print("%s words total, with a vocabulary size of %s" % (len(all_words),len(VOCAB)))
print("Max sentence length is %s" % max(sentence_lengths))
输出结果:
“154475 words total, with a vocabulary size of 18091
Max sentence length is 34”
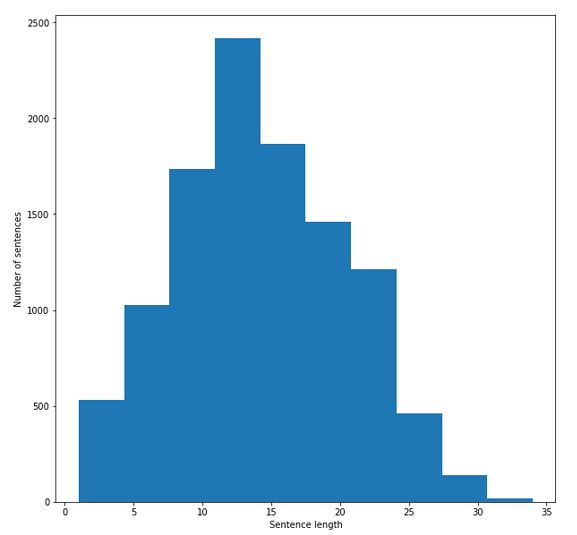
查看语句长度分布:
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10, 10))
plt.xlabel('Sentence length')
plt.ylabel('Number of sentences')
plt.hist(sentence_lengths)
plt.show()
二、 算法
现在数据已经清理干净并初步准备好,现在进入机器学习阶段。
在图像处理中,机器学习算法的输入是原始像素,欺诈检测算法用的是用户的特征作为输入,那么自然语言处理用什么作为输入呢?
一种自然而然的方法是给每一个字一个编码,但这种方法并不能很好地帮助算法去“理解”一个句子。我们的目标是找到一种合适的词嵌入方式去表示每一条推特,然后用这些嵌入来为每一条推特分类。
1. bag of words counts
我们从最简单的实现开始,bag of words即我们所说的词袋模型,它只是简单地把句子向量化,忽略其词序和语法,句法,将其仅仅看做是一个词集合,上面我们看到我们的字典长度是18091,则用0去表示所有的词,形成一个1*10891的向量,对于每一条推特,把出现的词的位置置1,这样把每一条推特进行向量化。
首先把数据集分成训练集和测试集,测试集占总数据的百分之二十,再把训练集和测试集的输入部分(推特内容)做向量化。
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
def cv(data):
count_vectorizer = CountVectorizer()
emb = count_vectorizer.fit_transform(data)
return emb, count_vectorizer
list_corpus = clean_questions.text.tolist()
list_labels = clean_questions.class_label.tolist()
X_train, X_test, y_train, y_test = train_test_split(list_corpus, list_labels, test_size=0.2, random_state=3)
X_train_counts, count_vectorizer = cv(X_train)
X_test_counts = count_vectorizer.transform(X_test)
现在我们对数据进行了基本的向量化,接下来我们试着把向量化后的数据可视化看看是否能够找到一定的规律。在最理想的情况下,我们希望不同类别的句子能够很好地区分,因为我们的向量维度接近两万,所以首先得把它降为2维再来做可视化。
这里我们用TruncatedSVD来降维,找出数据集中的两个主题,用每一条推特在两个主题中的权重值来作为横纵坐标,把“不相关”标记为橘色,“相关”和“无法确定”都标记为蓝色:
from sklearn.decomposition import TruncatedSVD
import matplotlib
import matplotlib.patches as mpatches
def plot_LSA(test_data, test_labels, savepath='PCA_demo.csv', plot=True):
lsa = TruncatedSVD(n_components=2)
lsa.fit(test_data)
lsa_scores = lsa.transform(test_data)
colors = ['orange','blue', 'blue']
if plot:
plt.scatter(lsa_scores[:, 0], lsa_scores[:, 1], s=8, alpha=.8, c=test_labels, cmap=matplotlib.colors.ListedColormap(colors))
red_patch = mpatches.Patch(color='orange', label='Not Relevant')
green_patch = mpatches.Patch(color='blue', label='Relevant')
plt.legend(handles=[red_patch, green_patch], prop={'size': 30})
fig = plt.figure(figsize=(16, 16))
plot_LSA(X_train_counts, y_train)
plt.show()
得到如下结果:
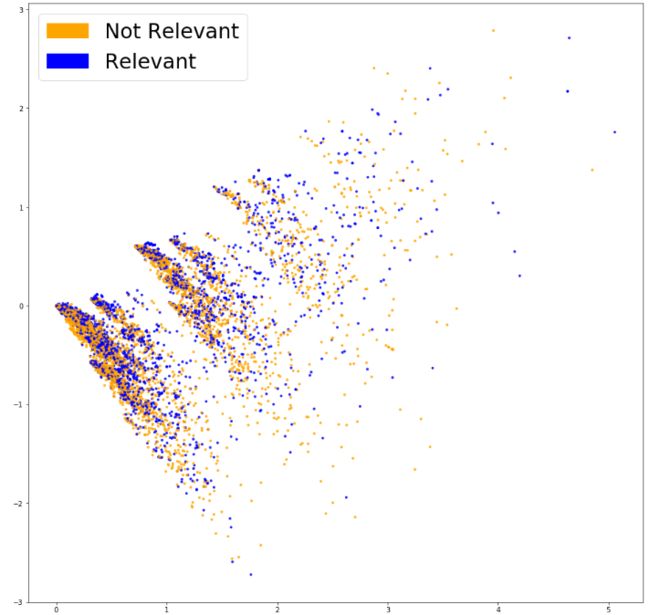 看起来两个颜色的推特都混在了一起,接下来我们看看机器学习算法是否能够把他们分类。这里选择最简单易行的逻辑回归算法。
看起来两个颜色的推特都混在了一起,接下来我们看看机器学习算法是否能够把他们分类。这里选择最简单易行的逻辑回归算法。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(C=30, class_weight='balanced', solver='newton-cg',
multi_class='multinomial', n_jobs=-1, random_state=40)
clf.fit(X_train_counts, y_train)
y_predicted_counts = clf.predict(X_test_counts)
接下来看看这个模型在我的数据集上表现如何。
from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, classification_report
def get_metrics(y_test, y_predicted):
# true positives / (true positives + false positives)
precision = precision_score(y_test, y_predicted, pos_label=None, average='weighted')
# true positives / (true positives + false negatives)
recall = recall_score(y_test, y_predicted, pos_label=None, average='weighted')
# harmonic mean of precision and recall
f1 = f1_score(y_test, y_predicted, pos_label=None, average='weighted')
# (true positives + true negatives)/total
accuracy = accuracy_score(y_test, y_predicted)
return accuracy, precision, recall, f1
accuracy, precision, recall, f1 = get_metrics(y_test, y_predicted_counts)
print("accuracy = %0.3f, precision = %0.3f, recall= %0.3f, f1 = %0.3f" % (accuracy, precision, recall, f1))
运行得到结果:
accuracy = 0.779, precision = 0.778, recall= 0.779, f1 = 0.778
看起来还可接受,但是为了更准确地做出决定,我们需要查看我们的模型究竟在什么地方犯了错。首先我们可以通过混淆矩阵来看一看。
import numpy as np
import itertools
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float')/cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title, fontsize=30)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, fontsize=20)
plt.yticks(tick_marks, classes, fontsize=20)
fmt = '.2f' if normalize else 'd'
thresh = cm.max()/2.
for i,j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), horizontalalignment='center',
color='black' if cm[i, j] < thresh else 'white', fontsize=40)
plt.tight_layout()
plt.ylabel('True label', fontsize=30)
plt.xlabel('Predicted label', fontsize=30)
return plt
cm = confusion_matrix(y_test, y_predicted_counts)
fig = plt.figure(figsize=(10,10))
plot = plot_confusion_matrix(cm,
classes= ['Not Relevant','Relevant',"Can't Decide"],
normalize=False,
title='Confusion Matrix')
plt.show()
print(cm)
结果如下:
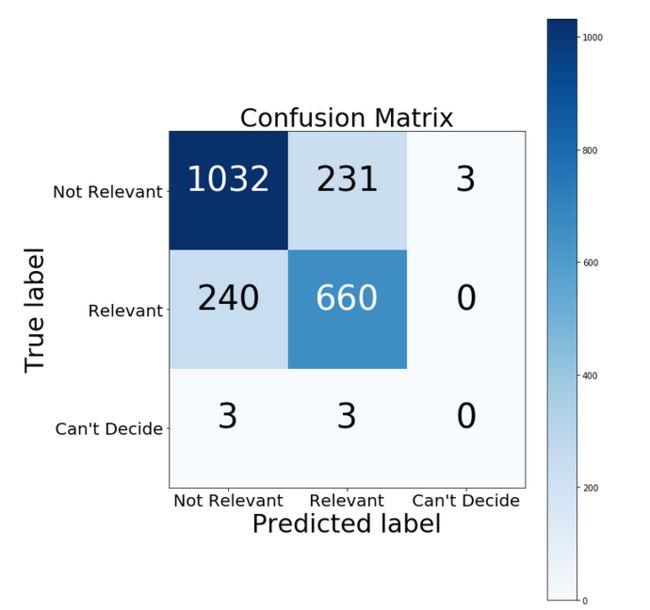
看得出第三种分类并没有被预测对,这是正常的,因为他在总体中占比过小,这里忽略它对整体的影响并不大。比起假正例(预测为灾难实际无关)来说我们的模型生成了更多的假负例(预测为无关实际为灾难),根据实际情况来看这应是比较理想的,因为误警报可能会造成很大的资源浪费。
除了混淆矩阵而外,我们还可以查看对我们的模型影响比较大的特征:
def get_most_important_features(vectorizer, model, n=5):
index_to_word = {v:k for k,v in vectorizer.vocabulary_.items()}
# loop fpr each class
classes = {}
for class_index in range(model.coef_.shape[0]):
word_importances = [(el, index_to_word[i]) for i, el in enumerate(model.coef_[class_index])]
sorted_coeff = sorted(word_importances, key=lambda x: x[0], reverse=True)
tops = sorted_coeff[:n]
bottom = sorted_coeff[-n:]
classes[class_index] = {'tops': tops,
'bottom': bottom}
return classes
importance = get_most_important_features(count_vectorizer, clf, 10)
def plot_important_words(top_scores, top_words, bottom_scores, bottom_words, name):
y_pos = np.arange(len(top_words))
top_pairs = [(a, b) for a,b in zip(top_words, top_scores)]
top_pairs = sorted(top_pairs, key=lambda x: x[1])
bottom_pairs = [(a, b) for a,b in zip(bottom_words, bottom_scores)]
bottom_pairs = sorted(bottom_pairs, key=lambda x: x[1], reverse=True)
top_words = [a[0] for a in top_pairs]
top_scores = [a[1] for a in top_pairs]
bottom_words = [a[0] for a in bottom_pairs]
bottom_scores = [a[1] for a in bottom_pairs]
fig = plt.figure(figsize=(10,10))
plt.subplot(121)
plt.barh(y_pos, bottom_scores, align='center', alpha=0.5)
plt.title('Not Relevant',fontsize=20)
plt.yticks(y_pos, bottom_words, fontsize=14)
plt.suptitle('Key words', fontsize=16)
plt.xlabel('Importance',fontsize=20)
plt.subplot(122)
plt.barh(y_pos, top_scores, align='center', alpha=0.5)
plt.title('Relevant', fontsize=20)
plt.yticks(y_pos, top_words, fontsize=14)
plt.suptitle(name, fontsize=16)
plt.xlabel('Importance', fontsize=20)
plt.subplots_adjust(wspace=0.8)
plt.show()
top_scores = [a[0] for a in importance[1]['tops']]
top_words = [a[1] for a in importance[1]['tops']]
bottom_scores = [a[0] for a in importance[1]['bottom']]
bottom_words = [a[1] for a in importance[1]['bottom']]
plot_important_words(top_scores, top_words, bottom_scores, bottom_words,
"Most important words for relevance")
结果如下:
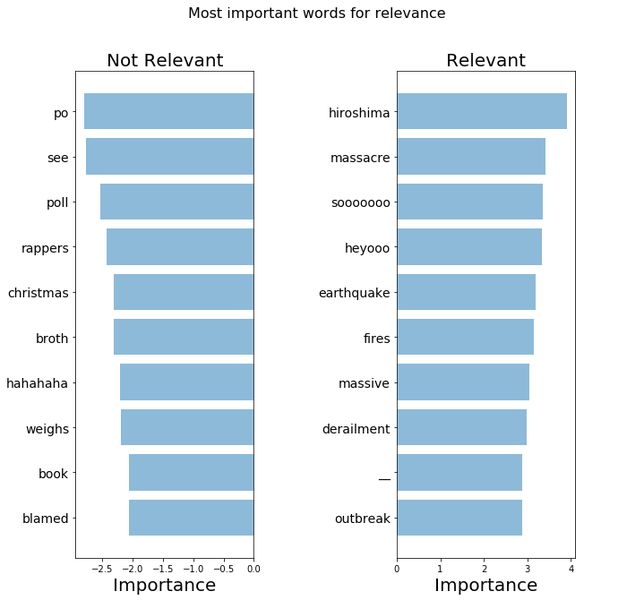 可以看出我们的模型确实找到了一些关键词,但是也有一些噪音混在其中(比如“heyoo”,“_”等),他们被选中可能因为他们在整个文档中的出镜频率都很高,甚至高过了关键词。
可以看出我们的模型确实找到了一些关键词,但是也有一些噪音混在其中(比如“heyoo”,“_”等),他们被选中可能因为他们在整个文档中的出镜频率都很高,甚至高过了关键词。
2. TFIDF Bag of Words
因为上述的问题,我们稍微调整一下词袋模型,考虑进TF-IDF(词频-逆文本频率指数),来过滤掉一些噪音,在这种方法下,词的重要性会随着它在样本中的出现次数增加,同时随着它在整个语料库中的出现次数降低。即如果一个词在一篇文章中频率很高,但在其他所有文章中频率比较低的时候他的重要性会更高。
def tfidf(data):
tfidf_vectorizer = TfidfVectorizer()
train = tfidf_vectorizer.fit_transform(data)
return train, tfidf_vectorizer
X_train_tfidf, tfidf_vectorizer = tfidf(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
同样的画出数据的降维分布图、混淆矩阵、以及特征重要程度。
fig = plt.figure(figsize=(16,16))
plot_LSA(X_train_tfidf, y_train)
plt.show()
clf_tfidf = LogisticRegression(C=30, class_weight='balanced', solver='newton-cg',
multi_class='multinomial', n_jobs=-1, random_state=40)
clf_tfidf.fit(X_train_tfidf, y_train)
y_predicted_tfidf = clf_tfidf.predict(X_test_tfidf)
accuracy_tfidf, precision_tfidf, recall_tfidf, f1_tfidf = get_metrics(y_test, y_predicted_tfidf)
print("accuracy = %.3f, precision = %.3f, recall = %.3f, f1 = %.3f" %
(accuracy_tfidf, precision_tfidf, recall_tfidf, f1_tfidf))
cm2 = confusion_matrix(y_test, y_predicted_tfidf)
fig = plt.figure(figsize=(10, 10))
plot = plot_confusion_matrix(cm2, classes=['Not Relevant','Relevant',"Can't Decide"], normalize=False,
title='Confusion Matrix')
plt.show()
print("TFIDF confusion mmatrix")
print(cm2)
print("BoW confusion matrix")
print(cm)
importance_tfidf = get_most_important_features(tfidf_vectorizer, clf_tfidf, 10)
top_scores = [a[0] for a in importance_tfidf[1]['tops']]
top_words = [a[1] for a in importance_tfidf[1]['tops']]
bottom_scores = [a[0] for a in importance_tfidf[1]['bottom']]
bottom_words = [a[1] for a in importance_tfidf[1]['bottom']]
plot_important_words(top_scores, top_words, bottom_scores, bottom_words,
"Most important words for relevance")
结果如下:
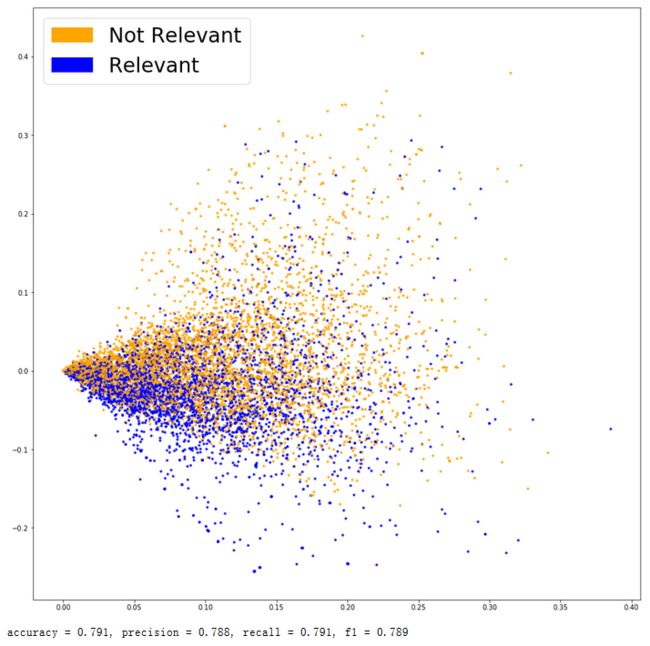
可以看出使用这种方法不同分类的样本区分度变得更好一些了。各项指标也略高于前一种方法。
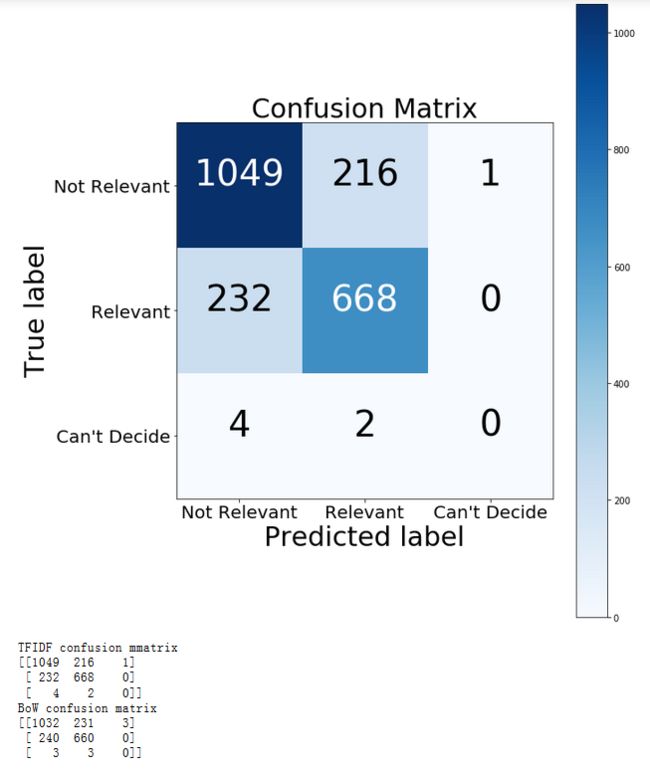
从混淆矩阵来看这个模型的表现也微好过上一个模型。
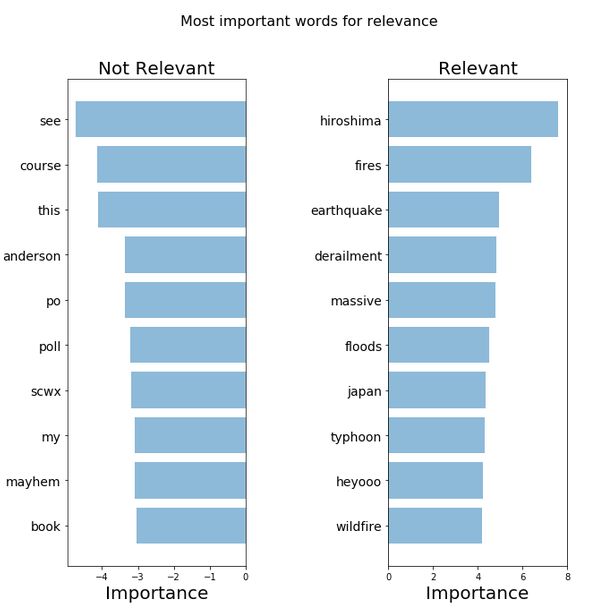
从词的重要程度我们能看到,上一个模型中的噪声在一定程度上被过滤掉了一部分。选出来的词汇也与主题更相关一些了。
3. word2vec
上面的模型中我们从文本中取出了重要的词汇,从而判断文本的分类。但是不可能所有的重要词汇都包含在了我们的训练数据中,所以当有新的数据进来包含新的重要词汇的话用之前的模型就无法识别。于是我们需要引入词汇的语义,这意味着我们能够通过我们的词嵌入来识别近义词,反义词等等。
Word2vec是一个预训练好的语料库,其中的词嵌入可以很好地表示语义相近的词汇,一个快速地表示一个文本的方法就是取文本中所含所有词汇word2vec值的均值。
先去网上下载训练好的word2vec集“GoogleNews-vectors-negative300.bin.gz”,放入目录中。再在我们的数据上生成相应的词嵌入。
import gensim
word2vec_path = "E:\\study\\research\\NLP\\word2vec\\GoogleNews-vectors-negative300.bin.gz"
word2vec = gensim.models.KeyedVectors.load_word2vec_format(word2vec_path, binary=True)
def get_average_word2vec(tokens_list, vector, generate_missing=False, k=300):
if len(tokens_list)<1:
return np.zeros(k)
if generate_missing:
vectorized = [vector[word] if word in vector else np.random.rand(k) for word in tokens_list]
else:
vectorized = [vector[word] if word in vector else np.zeros(k) for word in tokens_list]
length = len(vectorized)
summed = np.sum(vectorized, axis=0)
averaged = np.divide(summed,length)
return averaged
def get_word2vec_embeddings(vectors, clean_questions, generate_missing=False):
embeddings = clean_questions['tokens'].apply(lambda x: get_average_word2vec(x, vectors,
generate_missing=generate_missing))
return list(embeddings)
embeddings = get_word2vec_embeddings(word2vec, clean_questions)
X_train_word2vec, X_test_word2vec, y_train_word2vec, y_test_word2vec = train_test_split(embeddings,
list_labels, test_size=0.2,
random_state=3)
同样使用逻辑回归,看这种嵌入方式在在模型上的表现。
fig = plt.figure(figsize=(16, 16))
plot_LSA(embeddings, list_labels)
plt.show()
clf_w2v = LogisticRegression(C=30, class_weight='balanced', solver='newton-cg',
multi_class='multinomial', n_jobs=-1, random_state=40)
clf_w2v.fit(X_train_word2vec, y_train_word2vec)
y_predicted_word2vec = clf_w2v.predict(X_test_word2vec)
accuracy_w2v, precision_w2v, recall_w2v, f1_w2v = get_metrics(y_test_word2vec, y_predicted_word2vec)
print("accuracy = %.3f, precision = %.3f, recall = %.3f, f1 = %.3f" %
(accuracy_w2v, precision_w2v, recall_w2v, f1_w2v ))
cm_w2v = confusion_matrix(y_test_word2vec, y_predicted_word2vec)
fig = plt.figure(figsize=(10, 10))
plot = plot_confusion_matrix(cm_w2v, classes=['Not Relevant','Relevant',"Can't Decide"], normalize=False, title='Confusion matrix')
plt.show()
print("Word2Vec confusion matrix")
print(cm_w2v)
print("TFIDF confusion matrix")
print(cm2)
print("BoW confusion matrix")
print(cm)
结果如下:
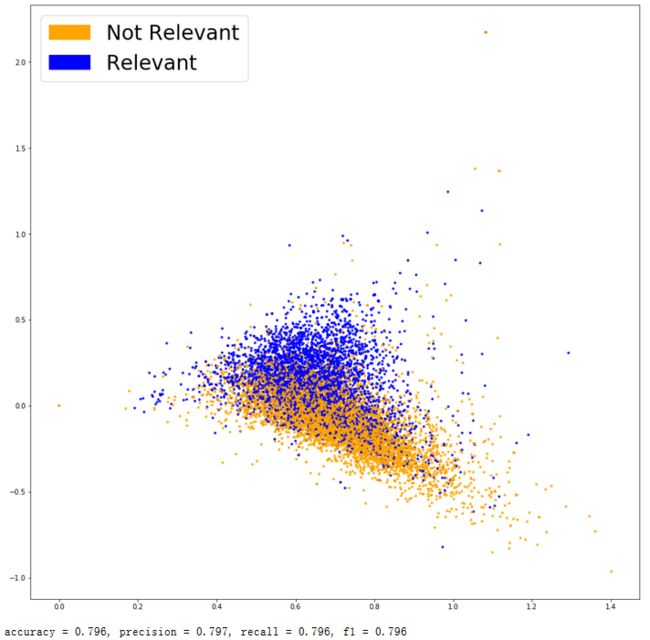
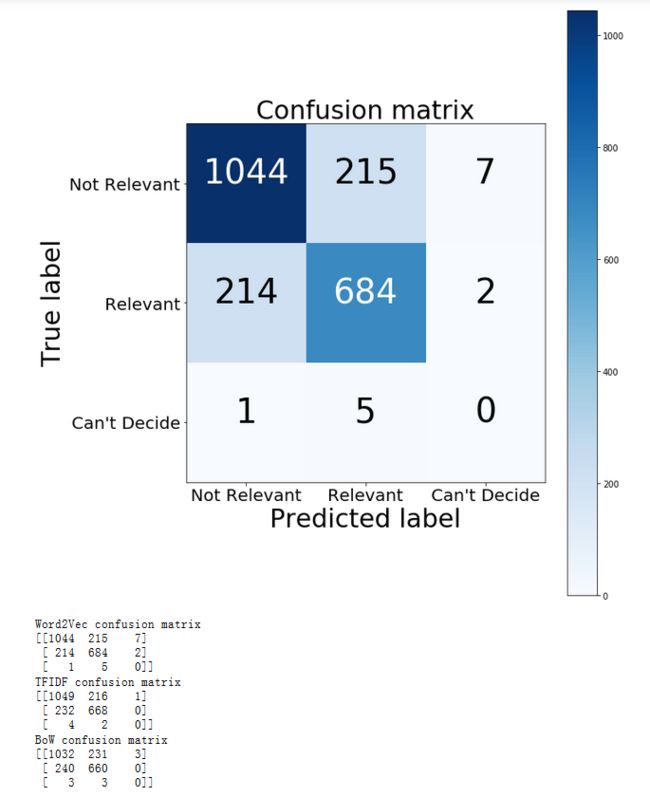 看得出各方面的表现都优于前面的两个模型。
看得出各方面的表现都优于前面的两个模型。
如果要再进一步查看我们的模型,比如像上面一样看看词在主题当中的重要程度,对于这一方法来说变得比较麻烦,因为每一个词都是用一个多维向量来表示,使模型很难直观判断其重要程度,但我们可以使用一个黑箱解释模型LIME来可视化各词在文本中产生的影响。
from lime import lime_text
from sklearn.pipeline import make_pipeline
from lime.lime_text import LimeTextExplainer
X_train_data, X_test_data, y_train_data, y_test_data = train_test_split(list_corpus, list_labels,
test_size=0.2, random_state=40)
vector_store = word2vec
def word2vec_pipeline(examples):
global vector_store
tokenizer = RegexpTokenizer(r'\w+')
tokenized_list = []
for example in examples:
example_tokens = tokenizer.tokenize(example)
vectorized_example = get_average_word2vec(example_tokens, vector_store,generate_missing=False, k=300)
tokenized_list.append(vectorized_example)
return clf_w2v.predict_proba(tokenized_list)
def explain_one_instance(instance, class_names):
explainer = LimeTextExplainer(class_names=class_names)
exp = explainer.explain_instance(instance, word2vec_pipeline, num_features=6)
return exp
def visualize_one_exp(features, labels, index, class_names = ['Not Relevant','Relevant',"Can't Decide"]):
exp = explain_one_instance(features[index], class_names=class_names)
print('Index:%d' % index)
print('True class: %s' % class_names[int(labels[index])])
exp.show_in_notebook(text=True)
c = make_pipeline(count_vectorizer, clf)
visualize_one_exp(X_test_data, y_test_data, 65)
visualize_one_exp(X_test_data, y_test_data, 60)
随机查看两段文本的解释如下:
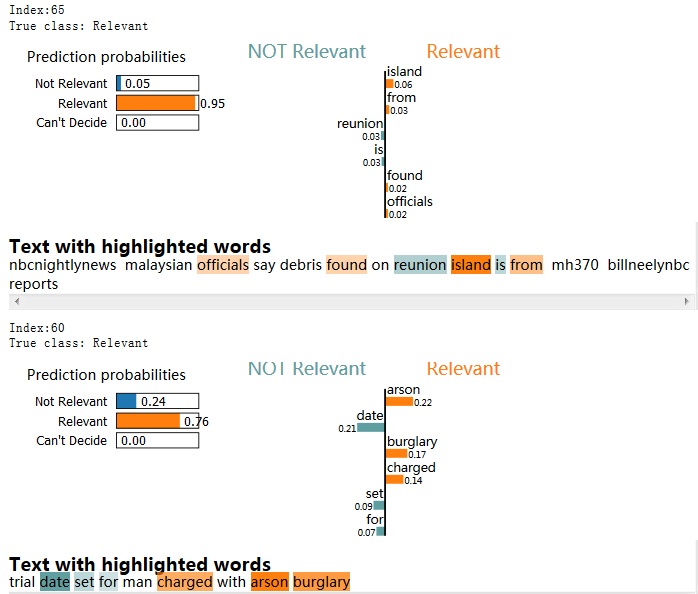 绘出词的重要程度排行:
绘出词的重要程度排行:
import random
from collections import defaultdict
random.seed(40)
def get_statistical_explanation(test_set, sample_size, word2vec_pipline, label_dict):
sample_sentences = random.sample(test_set, sample_size)
explainer = LimeTextExplainer()
labels_to_sentences = defaultdict(list)
contributors = defaultdict(dict)
# first, find contributing words to each class
for sentence in sample_sentences:
probabilities = word2vec_pipeline([sentence])
curr_label = probabilities[0].argmax()
labels_to_sentences[curr_label].append(sentence)
exp = explainer.explain_instance(sentence, word2vec_pipline, num_features=6, labels=[curr_label])
listed_explanation = exp.as_list(label=curr_label)
for word,contribution_weight in listed_explanation:
if word in contributors[curr_label]:
contributors[curr_label][word].append(contribution_weight)
else:
contributors[curr_label][word] = [contribution_weight]
# average each word's contribution to a class, and sort them by impact
average_contributions = {}
sorted_contributions = {}
for label,lexica in contributors.items():
curr_label = label
curr_lexica = lexica
average_contributions[curr_label] = pd.Series(index=curr_lexica.keys())
for word,scores in curr_lexica.items():
average_contributions[curr_label].loc[word] = np.sum(np.array(scores))/sample_size
detractors = average_contributions[curr_label].sort_values()
supporters = average_contributions[curr_label].sort_values(ascending=False)
sorted_contributions[label_dict[curr_label]] = {'detractors': detractors,
'supporters': supporters}
return sorted_contributions
label_to_text = {
0: 'Not Relevant',
1: 'Relevant',
2: "Can't Decide"
}
sorted_contributions = get_statistical_explanation(X_test_data, 100, word2vec_pipeline, label_to_text)
# First index is the class
# Second index is 0 for detractors, 1 for supporters
# Third is how many words we sample
top_words = sorted_contributions['Relevant']['supporters'][:10].index.tolist()
top_scores = sorted_contributions['Relevant']['supporters'][:10].tolist()
bottom_words = sorted_contributions['Relevant']['detractors'][:10].index.tolist()
bottom_scores = sorted_contributions['Relevant']['detractors'][:10].tolist()
plot_important_words(top_scores, top_words, bottom_scores, bottom_words, "Most important words for relevance")
结果如下:
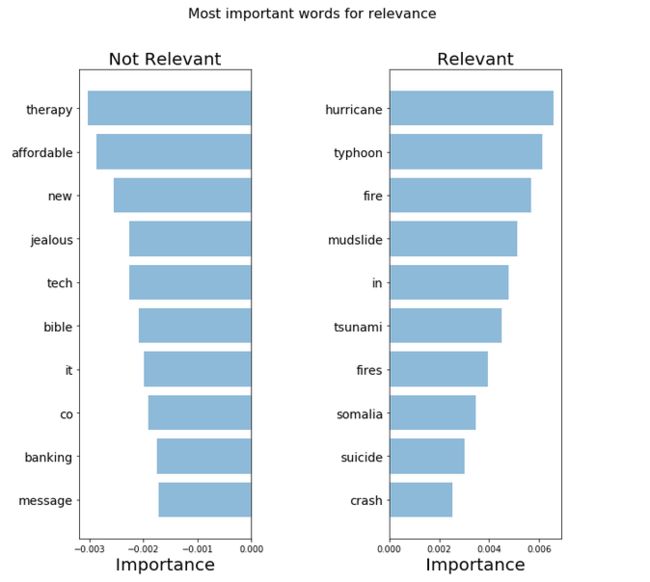
可以看出词语主题的相关性得到了更进一步的提升。
4. CNN
虽然模型考虑了语义后表现得更好了,但是word2vec算法彻底忽略掉了句子的结构,最后我们尝试一个更加复杂的模型,看看考虑进句子结构是否有帮助。
这里我们会使用卷积神经网络(CNN)来做文本分类,虽然他不像循环神经网络(RNN)那么受欢迎,但是它也能得到很有竞争力的结果,而且训练很迅速,这对于这篇教程来说很合适。
首先,用word2vec对我们的文本进行词嵌入。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
EMBEDDING_DIM = 300
MAX_SEQUENCE_LENGTH = 35
VOCAB_SIZE = len(VOCAB)
VALIDATION_SPLIT = .2
tokenizer = Tokenizer(num_words=VOCAB_SIZE)
tokenizer.fit_on_texts(clean_questions['text'].tolist())
sequences = tokenizer.texts_to_sequences(clean_questions['text'].tolist())
word_index = tokenizer.word_index
print("Found %s unique tokens." % len(word_index))
cnn_data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(clean_questions['class_label']))
indices = np.arange(cnn_data.shape[0])
np.random.shuffle(indices)
cnn_data = cnn_data[indices]
labels = labels[indices]
num_validation_samples = int(VALIDATION_SPLIT * cnn_data.shape[0])
embedding_weights = np.zeros((len(word_index)+1, EMBEDDING_DIM))
for word,index in word_index.items():
embedding_weights[index, :] = word2vec[word] if word in word2vec else np.random.rand(EMBEDDING_DIM)
print(embedding_weights.shape)
输出:
“Found 19092 unique tokens.
(19093, 300)”
接下来定义一个简单卷积神经网络。这里我们参考 Yoon Kim提出的模型,并做点小的改变。构建并训练我们的模型。
from keras.layers import Dense, Input, Flatten, Dropout, concatenate
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.layers import LSTM, Bidirectional
from keras.models import Model
def ConvNet(embeddings, max_sequence_length, num_words, embedding_dim, labels_index, trainable=False, extra_conv=True):
embedding_layer = Embedding(num_words, embedding_dim, weights=[embeddings],
input_length=max_sequence_length, trainable=trainable)
sequence_input = Input(shape=(max_sequence_length,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
# Yoon Kim model (https://arxiv.org/abs/1408.5882)
convs = []
filter_sizes = [3, 4, 5]
for filter_size in filter_sizes:
l_conv = Conv1D(filters=128, kernel_size=filter_size, activation='relu')(embedded_sequences)
l_pool = MaxPooling1D(pool_size=3)(l_conv)
convs.append(l_pool)
l_merge = concatenate(convs, axis=1)
# add a 1D convnet with global maxpooling, instead of Yoon Kim model
conv = Conv1D(filters=128, kernel_size=3, activation='relu')(embedded_sequences)
pool = MaxPooling1D(pool_size=3)(conv)
if extra_conv==True:
x = Dropout(0.5)(l_merge)
else:
#Original Yoon Kim model
x = Dropout(0.5)(pool)
x = Flatten()(x)
x = Dense(128, activation='relu')(x)
# x = Dropout(0.5)(x)
preds = Dense(labels_index, activation='softmax')(x)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
return model,x
x_train = cnn_data[:-num_validation_samples]
y_train = labels[:-num_validation_samples]
x_val = cnn_data[-num_validation_samples:]
y_val = labels[-num_validation_samples:]
model,x = ConvNet(embedding_weights, MAX_SEQUENCE_LENGTH, len(word_index)+1, EMBEDDING_DIM,
len(list(clean_questions["class_label"].unique())), False)
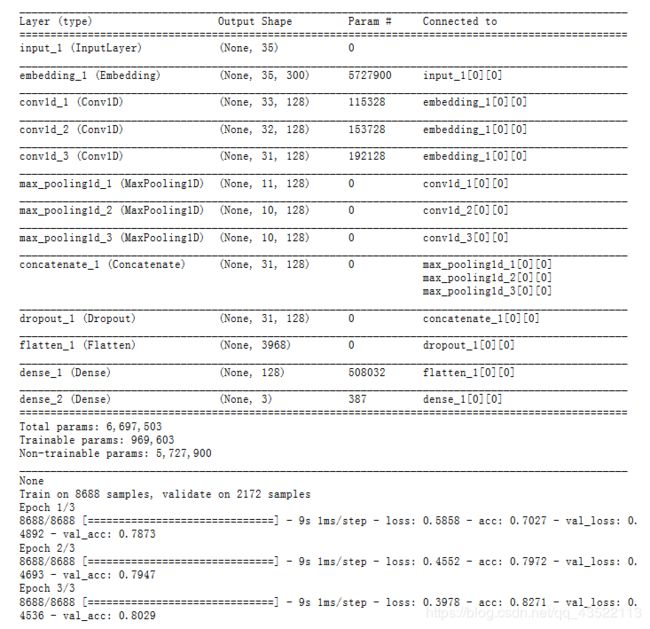
print(model.summary())
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=3, batch_size=128)
y_pred = model.predict(x_val)
模型构造及效果如下:
 我们画出他的混淆矩阵并与前三种比较,绘出分类效果:
我们画出他的混淆矩阵并与前三种比较,绘出分类效果:
def to_numerical(y):
y_tmp = y.round()
y = []
for i,j in enumerate(y_tmp):
if j[0] == 1:
y.append(0)
elif j[1] == 1:
y.append(1)
else:
y.append(2)
return y
y_pred = to_numerical(y_pred)
y_val = to_numerical(y_val)
cm_cnn = confusion_matrix(y_val, y_pred)
fig = plt.figure(figsize=(10, 10))
plot = plot_confusion_matrix(cm_cnn, classes=['Not Relevant','Relevant',"Can't Decide"], normalize=False, title='Confusion matrix')
plt.show()
print("CNN confusion matrix")
print(cm_cnn)
print("Word2Vec confusion matrix")
print(cm_w2v)
print("TFIDF confusion matrix")
print(cm2)
print("BoW confusion matrix")
print(cm)
dense1_layer_model = Model(inputs=model.input,outputs=model.get_layer('dense_2').output)
x = dense1_layer_model.predict(x_val)
fig = plt.figure(figsize=(16, 16))
plot_LSA(x, y_val)
plt.show()
结果如下:
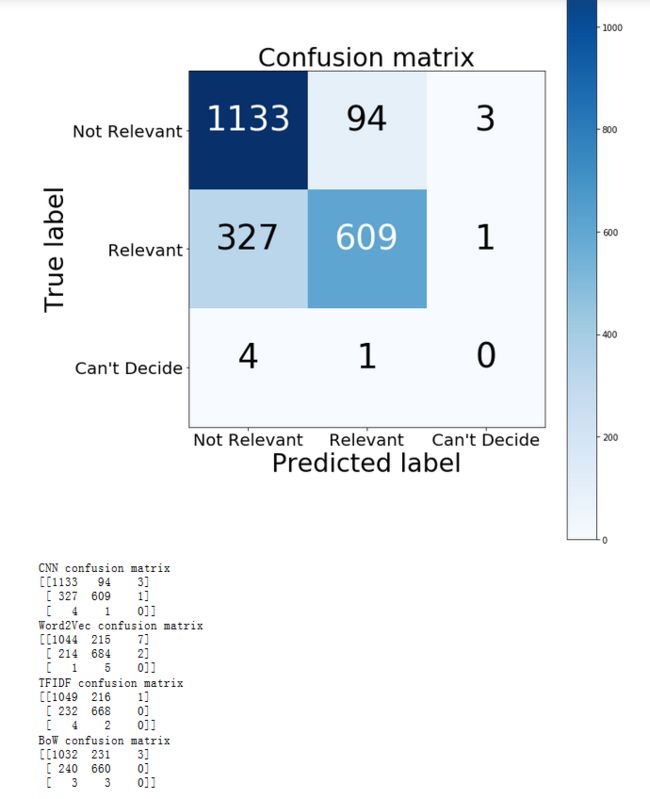 看的出这个模型倾向于判断出更少的假正例,所以在这一场景下也许在实际应用中这一模型会更加理想。
看的出这个模型倾向于判断出更少的假正例,所以在这一场景下也许在实际应用中这一模型会更加理想。
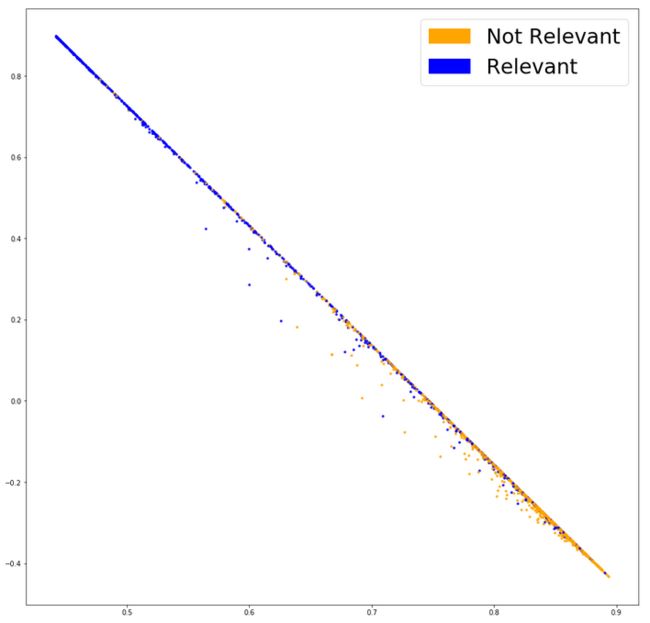 这个分类效果图是在模型的最后一层画出,可以看出两组数据的分离较之前其实更为明显了。
这个分类效果图是在模型的最后一层画出,可以看出两组数据的分离较之前其实更为明显了。
三、文本生成
接下来训练一个基于字节的文本生成模型。这一模型来自于ajmanser的项目详情可以上github去查看,按照指示准备相关文件。
from keras import layers
import sys
# Dictionary mapping unique characters to their index in 'chars'
text = open('seed_text.txt').read()
chars = ['\n', ' ', '!', '"', '#', '$', '%', '&', "'", '(', ')', '*', ',', '-', '.', '/', '0', '1',
'2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<', '=', '>', '?', '@', 'A', 'B', 'C',
'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y',
'z', '{', '|', '}', '~']
char_indices = dict((char, chars.index(char)) for char in chars)
maxlen = 60
step = 1
model = keras.models.Sequential()
model.add(layers.LSTM(1024, input_shape=(maxlen, len(chars)), return_sequences=True))
model.add(layers.LSTM(1024, input_shape=(maxlen, len(chars))))
model.add(layers.Dense(len(chars), activation='softmax'))
model.load_weights("pretrained-yelp.hdf5")
optimizer = keras.optimizers.Adam(lr=0.0002)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
def random_reviews():
start_index = np.random.randint(0, len(text)-maxlen-1)
generated_text = text[start_index: start_index + maxlen]
print("Coming up with several reviews for you...")
for temperature in [0.8]:
sys.stdout.write(generated_text)
# we generate 600 characters
for i in range(600):
sampled = np.zeros((1, maxlen, len(chars)))
for t,char in enumerate(generated_text):
sampled[0, t, char_indices[char]] = 1.
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_char = chars[next_index]
generated_text += next_char
generated_text = generated_text[1:]
sys.stdout.write(next_char)
sys.stdout.flush()
print(generated_text)
random_reviews()
结果:
 修改模型,使之能基于输入的关键词生成评价:
修改模型,使之能基于输入的关键词生成评价:
# substitude food words in the generated reviews for ones from a pre-established list
from nltk.corpus import wordnet as wn
def food_related(nouns):
food = wn.synset('food.n.01')
final_list = []
for word in nouns:
temp = word
word = word+'.n.01'
try:
if food.wup_similarity(wn.synset(word))>0.20 and temp!='food':
final_list.append(temp)
except:
pass
return final_list
def user_custom(foods):
# enter foods as a string separated by commas. For example 'sushi, sashimi, maki'
start_index = np.random.randint(0, len(text) - maxlen - 1)
generated_text = text[start_index:start_index + maxlen]
print('Coming up with two ideas for you...')
final = generated_text+''
for temperature in [0.8]:
# generate 600 characters
for i in range(1000):
sampled = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated_text):
sampled[0, t, char_indices[char]] = 1.
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_char = chars[next_index]
final += next_char
generated_text += next_char
generated_text = generated_text[1:]
# print first review, then second via SOR/EOR
temp = personalized_clean_up(final, foods)
start = temp.find('SOR')
stop = findStrAfterStr(temp, 'EOR', 'SOR')
end_first = temp[start+4:stop]
new = temp[get_second_index(temp, 'SOR')+4:]
ending = new.find('EOR')
print(temp[start+4:stop])
print("")
print(new[:ending])
def personalized_clean_up(review,user_items):
#take generic review, and replace with user generated words
generic_nouns = review_to_nouns(review)
food_generic = food_related(generic_nouns)
user_picked_items = user_items.split(",")
final = []
for word in re.findall(r"[\w']+|[.,!?;]", review):
if word in food_generic and len(user_picked_items)>1:
word = np.random.choice(user_picked_items)
final.append(word)
else:
final.append(word)
new_review = " ".join(final)
return re.sub(r'\s+([?.!","])', r'\1', new_review)
def review_to_nouns(review):
is_noun = lambda pos: pos[:2] == 'NN'
token = nltk.word_tokenize(review)
nouns = [word for (word, pos) in nltk.pos_tag(token) if is_noun(pos)]
return nouns
def findStrAfterStr(myString, searchText, afterText):
after_index = myString.index(afterText)
return myString.find(searchText, after_index)
def get_second_index(input_string, sub_string):
return input_string.index(sub_string, input_string.index(sub_string)+1)
user_custom('burrito, taco, guac')
输出结果如下:

四、总结
本文梳理了NLP中对文本的几种预处理方式,包括BOW,TF-IDF BOW, Word2vec,整体走了一遍NLP文本分类的流程并对不同处理进行了比较。最后简单介绍了NLP文本生成模型的流程,细节处有待进一步探讨。