- Ansible 部署k8s
- 系统基础配置
- 部署ha和harbor
- harbor
- harbor之https
- HA
- keepalived
- haproxy
- ansible部署k8s
- 基础环境准备
- 安装ansible
- 配置ansible控制端免密钥登录
- 同步docker证书
- 下载 ansible项目
- 准备hosts文件
- 验证ansible安装
- 相关配置文件
- 部署
- 环境初始化
- 部署etcd集群
- 安装docker
- docker证书文件
- 部署master
- 部署node
- 部署network
- 测试容器内外通信
- 集群添加master节点
- 集群添加node节点
- 集群中移除master和node
- 基础环境准备
- 集群升级
- 升级前的准备和二进制文件备份
- 单台机器手动升级
- master升级
- node升级
- easzctl工具升级
- 部署dashboard
- 准备配置文件
- dashboard-2.0.0-rc6.yml
- admin-user.yml
- 运行dashboard
- 登录验证dashboard
- 查找dashboard密钥
- Token方式登录dashboard
- Kubeconfig方式登录dashboard
- 设置token的会话超时时间
- 准备配置文件
- DNS
- kube-dns
- 下载镜像并上传到harbor
- 准备kube-dns.yaml文件
- 运行kube-dns
- CoreDNS
- 生成CoreDNS配置文件
- coredns.yml
- 部署
- 测试不同namespace中的DNS解析
- kube-dns
- Etcd
- 启动脚本参数
- 查看成员信息
- 验证etcd所有成员的状态
- 查看etcd数据信息
- etcd增删改查
- 添加数据
- 查询数据
- 修改数据
- 删除数据
- etcd数据watch机制
- etcd数据备份与恢复机制
- etcd v3版本数据备份与恢复
- 备份数据
- 恢复数据
- 脚本自动备份
- etcd v2版本数据备份与恢复
- etcd v3版本数据备份与恢复
Ansible 部署k8s
主机列表
| IP | Hostname | Role |
|---|---|---|
| 10.203.104.20 | master1.linux.com | mster |
| 10.203.104.21 | master2.linux.com | mster |
| 10.203.104.22 | master3.linux.com | mster |
| 10.203.104.23 | etcd1.linux.com | mster |
| 10.203.104.24 | etcd2.linux.com | mster |
| 10.203.104.25 | etcd3.linux.com | mster |
| 10.203.104.26 | node1.linux.com | node |
| 10.203.104.27 | node2.linux.com | node |
| 10.203.104.28 | node3.linux.com | node |
| 10.203.104.29 | harbor.linux.com | harbor |
| 10.203.104.30 | ha1.linux.com | HA |
| 10.203.104.31 | ha1.linux.com | HA |
| 10.203.104.212 | keeplived-vip | VIP |
| 10.203.104.213 | keeplived-vip | VIP |
系统基础配置
-
时间同步
所有主机时间同步 root@node3:~# timedatectl set-timezone Asia/Shanghai root@node3:~# timedatectl set-ntp on root@node3:~# timedatectl Local time: Sat 2020-06-06 00:18:27 CST Universal time: Fri 2020-06-05 16:18:27 UTC RTC time: Fri 2020-06-05 16:18:27 Time zone: Asia/Shanghai (CST, +0800) System clock synchronized: yes systemd-timesyncd.service active: yes RTC in local TZ: no -
关闭防火墙
ufw disable -
关闭selinux
-
配置所有节点主机名解析
root@master1:~# cat scp_hosts.sh #!/bin/bash #目标主机列表 IP=" 10.203.104.20 10.203.104.21 10.203.104.22 10.203.104.23 10.203.104.24 10.203.104.25 10.203.104.26 10.203.104.27 10.203.104.28 " for node in ${IP};do scp /etc/hosts ${node}:/etc/hosts echo "hosts拷贝成功!" done -
配置master免密码登录
-
root@master1:~# ssh-keygen
-
root@master1:~# ssh-copy-id master2
root@master1:~# cat scp.sh #!/bin/bash #目标主机列表 IP=" 10.203.104.20 10.203.104.21 10.203.104.22 10.203.104.23 10.203.104.24 10.203.104.25 10.203.104.26 10.203.104.27 10.203.104.28 " for node in ${IP};do sshpass -p xxxxx ssh-copy-id ${node} -o StrictHostKeyChecking=no if [ $? -eq 0 ];then echo "${node} 秘钥copy完成" fi done
-
-
配置IP转发($\color{red}{net.ipv4.ip_forward = 1}$)和优化内核参数
root@master1:~# cat /etc/sysctl.conf 最后添加一下内容 net.ipv4.ip_forward = 1 net.ipv4.tcp_max_orphans = 3276800 net.ipv4.tcp_max_tw_buckets =20000 net.ipv4.tcp_synack_retries = 1 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_timestamps = 1 #? # keepalive conn net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_keepalive_time = 300 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.ip_local_port_range = 10001 65000 # swap vm.overcommit_memory = 0 vm.swappiness = 10 #net.ipv4.conf.eth1.rp_filter = 0 #net.ipv4.conf.lo.arp_ignore = 1 #net.ipv4.conf.lo.arp_announce = 2 #net.ipv4.conf.all.arp_ignore = 1 #net.ipv4.conf.all.arp_announce = 2 -
取消vim自动缩进功能
root@master1:~# vim ~/.vimrc set paste
部署ha和harbor
harbor
安装docker和docker-compose
root@master1:~# cat docker-install_\(2\).sh
#!/bin/bash
# step 1: 安装必要的一些系统工具
sudo apt-get update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
# step 2: 安装GPG证书
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
# Step 3: 写入软件源信息
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
# Step 4: 更新并安装Docker-CE
sudo apt-get -y update
sudo apt-get -y install docker-ce docker-ce-cli
root@harbor:~# sh docker-install.sh
root@harbor:~# apt install docker-compose
启动docker
root@harbor:/usr/local/src/harbor# systemctl start docker
部署harbor
下载harbor的offline包到系统的/usr/local/src/目录下
root@harbor:~# cd /usr/local/src/
root@harbor:/usr/local/src# ls
harbor-offline-installer-v1.1.2.tgz
root@harbor:/usr/local/src# tar xvf harbor-offline-installer-v1.1.2.tg
root@harbor:/usr/local/src# ls
harbor harbor-offline-installer-v1.1.2.tgz
root@harbor:/usr/local/src# cd harbor/
编辑harbor.cfg文件修改hostnam 、 ui_url_protocol 和harbor的admin密码
root@harbor:/usr/local/src/harbor# vim harbor.cfg
root@harbor:/usr/local/src/harbor# cat harbor.cfg
#The IP address or hostname to access admin UI and registry service.
hostname = harbor.danran.com
ui_url_protocol = https
harbor_admin_password = danran
ssl_cert = /usr/local/src/harbor/certs/harbor-ca.crt
ssl_cert_key = /usr/local/src/harbor/certs/harbor-ca.key
修改prepare文件的empty_subj参数
root@harbor:/usr/local/src/harbor# cat prepare | grep empty
#empty_subj = "/C=/ST=/L=/O=/CN=/"
empty_subj = "/C=US/ST=California/L=Palo Alto/O=VMware, Inc./OU=Harbor/CN=notarysigner"
harbor之https
生成https证书文件
root@harbor:~# cd /usr/local/src/harbor/
root@harbor:/usr/local/src/harbor# mkdir certs
root@harbor:/usr/local/src/harbor# cd certs/
root@harbor:/usr/local/src/harbor/certs# openssl genrsa -out /usr/local/src/harbor/certs/harbor-ca.key
Generating RSA private key, 2048 bit long modulus (2 primes)
.........+++++
.....................................+++++
e is 65537 (0x010001)
Ubuntu中需手动创建/root/.rnd文件
root@harbor:/usr/local/src/harbor/certs# touch /root/.rnd
root@harbor:/usr/local/src/harbor/certs# openssl req -x509 -new -nodes -key /usr/local/src/harbor/certs/harbor-ca.key -subj "/CN=harbor.linux.com" -days 7120 -out /usr/local/src/harbor/certs/harbor-ca.crt
root@harbor:/usr/local/src/harbor/certs# ls
harbor-ca.crt harbor-ca.key
将证书文件配置在harbor配置文件中
root@harbor:/usr/local/src/harbor/certs# ll /usr/local/src/harbor/certs/harbor-ca.crt
-rw-r--r-- 1 root root 1131 Jun 12 13:01 /usr/local/src/harbor/certs/harbor-ca.crt
root@harbor:/usr/local/src/harbor/certs# ll /usr/local/src/harbor/certs/harbor-ca.key
-rw------- 1 root root 1679 Jun 12 12:57 /usr/local/src/harbor/certs/harbor-ca.key
root@harbor:/usr/local/src/harbor# cat harbor.cfg | grep ssl
#It can be set to https if ssl is enabled on nginx.
ssl_cert = /usr/local/src/harbor/certs/harbor-ca.crt
ssl_cert_key = /usr/local/src/harbor/certs/harbor-ca.key
安装harbor
root@harbor:/usr/local/src/harbor# ./install.sh
通过配置了harbor域名解析的主机,可访问harbor的hostname测试harbor,可通过harbor.cfg中配置的admin密码登录
docker client 节点登录 harbor
登录harbor报证书错误
root@master2:~# docker login harbor.linux.com
Username: admin
Password:
Error response from daemon: Get https://harbor.linux.com/v2/: x509: certificate signed by unknown authority
新建存放证书的目录,目录一定为harbor的域名
root@master2:~# mkdir /etc/docker/certs.d/harbor.linux.com -p
将harbor的证书文件拷贝到节点上(harbor的证书文件为/usr/local/src/harbor/certs/harbor-ca.crt )
root@harbor:/usr/local/src/harbor# scp /usr/local/src/harbor/certs/harbor-ca.crt master2:/etc/docker/certs.d/harbor.linux.com
在节点上重启docker服务
root@master2:~# systemctl daemon-reload
root@master2:~# systemctl restart docker
在节点上重新登录harbor
root@master2:~# docker login harbor.linux.com
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
docker login harbor
如果docker login时报以下错误,则需安装apt install gnupg2 pass包
root@harbor:/images/kubeadm_images/quay.io/coreos# docker login harbor.linux.com
Username: admin
Password:
Error response from daemon: Get http://harbor.linux.com/v2/: dial tcp 10.203.124.236:80: connect: connection refused
root@harbor:/images# apt install gnupg2 pass
root@harbor:/images# docker login harbor.linux.com
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
HA
两台HA主机上都需要执行以下安装操作
keepalived
ha1节点
root@ha1:~# apt install haproxy keepalived
root@ha1:~# cp /usr/share/doc/keepalived/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
root@ha1:~# vim /etc/keepalived/keepalived.conf
root@ha1:~# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface ens160
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# optional label. should be of the form "realdev:sometext" for
# compatibility with ifconfig.
10.203.104.212 label eths160:1
10.203.104.213 label eths160:2
}
}
root@ha1:~# systemctl restart keepalived.service
root@ha1:~# systemctl enable keepalived.service
Synchronizing state of keepalived.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable keepalived
ha2节点
root@ha2:~# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
garp_master_delay 10
smtp_alert
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# optional label. should be of the form "realdev:sometext" for
# compatibility with ifconfig.
10.203.104.212 label eths160:1
10.203.104.213 label eths160:2
}
}
root@ha2:~# systemctl restart keepalived.service
root@ha2:~# systemctl enable keepalived.service
Synchronizing state of keepalived.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable keepalived
测试
在ha1节点 systemctl stop keepalived.service,观察VIP是否漂移到ha2节点
haproxy
root@ha1:~# vim /etc/haproxy/haproxy.cfg
在haproxy.cfg配置文件最后添加keepalived VIP的监听,负载均衡到三台master server,及HA的状态页
listen stats
mode http
bind 0.0.0.0:9999
stats enable
log global
stats uri /haproxy-status
stats auth haadmin:danran
listen k8s-api-6443
bind 10.203.104.212:6443
mode tcp
server etcd1 10.203.104.20:6443 check inter 3s fall 3 rise 5
#server etcd2 10.203.104.21:6443 check inter 3s fall 3 rise 5
#server etcd3 10.203.104.22:6443 check inter 3s fall 3 rise 5
root@ha1:~# systemctl restart haproxy.service
root@ha1:~# systemctl enable haproxy.service
Synchronizing state of haproxy.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable haproxy
root@ha1:~# ss -ntl | grep 6443
LISTEN 0 128 10.203.104.212:6443 0.0.0.0:*
ansible部署k8s
- https://github.com/easzlab/kubeasz
在master,node,etcd节点安装python2.7
root@etcd1:~# apt-get install python2.7 -y
root@etcd1:~# ln -s /usr/bin/python2.7 /usr/bin/python
ansible节点安装python-pip
root@etcd1:~# apt install -y python-pip
基础环境准备
安装ansible
root@master1:~# apt install ansible
配置ansible控制端免密钥登录
root@master1:~# apt install sshpass
生成master1的密钥对
root@master1:~# ssh-keygen
将ansible服务器的密钥拷贝到master,node,etcd节点上
root@master1:~# cat ssh-scp.sh
#!/bin/bash
#目标主机列表
IP="
10.203.104.20
10.203.104.21
10.203.104.22
10.203.104.23
10.203.104.24
10.203.104.25
10.203.104.26
10.203.104.27
10.203.104.28
"
for node in ${IP};do
sshpass -p P@ss1234 ssh-copy-id ${node} -o StrictHostKeyChecking=no
if [ $? -eq 0 ];then
echo "${node} 秘钥copy完成"
else
echo "${node} 秘钥copy失败"
fi
done
root@master1:~# bash ssh-scp.sh
同步docker证书
root@master1:~# cat scp_cert.sh
#!/bin/bash
#目标主机列表
IP="
10.203.104.20
10.203.104.21
10.203.104.22
10.203.104.23
10.203.104.24
10.203.104.25
10.203.104.26
10.203.104.27
10.203.104.28
"
for node in ${IP};do
sshpass -p P@ss8183 ssh-copy-id ${node} -o StrictHostKeyChecking=no
if [ $? -eq 0 ];then
echo "${node} 秘钥copy完成"
1.6.2:clone项目:
1.6.3:准备hosts文件:
echo "${node} 秘钥copy完成,准备环境初始化....."
ssh ${node} "mkdir /etc/docker/certs.d/harbor.linux.com -p"
echo "Harbor 证书目录创建成功!"
scp /usr/local/src/harbor/certs/harbor-ca.crt
${node}:/etc/docker/certs.d/harbor.linux.com/harbor-ca.crt
echo "Harbor 证书拷贝成功!"
scp /etc/hosts ${node}:/etc/hosts
echo "host 文件拷贝完成"
scp -r /root/.docker ${node}:/root/
echo "Harbor 认证文件拷贝完成!"
scp -r /etc/resolv.conf ${node}:/etc/
else
echo "${node} 秘钥copy失败"
fi
done
下载 ansible项目
root@master1:~# export release=2.2.0
root@master1:~# curl -C- -fLO --retry 3 https://github.com/easzlab/kubeasz/releases/download/${release}/easzup
root@master1:~# chmod +x ./easzup
# 使用工具脚本下载
root@master1:~# ./easzup -D
# 会下载/etc/ansible目录到主机上
root@master1:~# ls /etc/ansible/
01.prepare.yml 03.containerd.yml 04.kube-master.yml 06.network.yml 11.harbor.yml 23.backup.yml 90.setup.yml 92.stop.yml ansible.cfg dockerfiles down hosts pics roles
02.etcd.yml 03.docker.yml 05.kube-node.yml 07.cluster-addon.yml 22.upgrade.yml 24.restore.yml 91.start.yml 99.clean.yml bin docs example manifests README.md tools
若内网无法下载,可找台能下载项目的机器,下载完成后,将/etc/ansible/目录拷贝至内网环境主机的/etc/ansible/使用
查看k8s的版本
root@master1:~# cd /etc/ansible
root@master1:/etc/ansible# ./bin/kube-apiserver --version
Kubernetes v1.17.4
准备hosts文件
#复制hosts模板 文件
root@k8s-master1:/etc/ansible# cp example/hosts.m-masters.example ./hosts
root@master1:/etc/ansible# cat /etc/ansible/hosts
# 'etcd' cluster should have odd member(s) (1,3,5,...)
# variable 'NODE_NAME' is the distinct name of a member in 'etcd' cluster
[etcd]
10.203.104.23 NODE_NAME=etcd1
10.203.104.24 NODE_NAME=etcd2
10.203.104.25 NODE_NAME=etcd3
# master node(s)
[kube-master]
10.203.104.20 NEW_MASTER=yes
10.203.104.21
#10.203.104.22
# work node(s)
[kube-node]
10.203.104.26 NEW_NODE=yes
10.203.104.27
10.203.104.28
# [optional] harbor server, a private docker registry
# 'NEW_INSTALL': 'yes' to install a harbor server; 'no' to integrate with existed one
# 'SELF_SIGNED_CERT': 'no' you need put files of certificates named harbor.pem and harbor-key.pem in directory 'down'
[harbor]
#10.203.104.8 HARBOR_DOMAIN="harbor.yourdomain.com" NEW_INSTALL=no SELF_SIGNED_CERT=yes
# [optional] loadbalance for accessing k8s from outside
[ex-lb]
10.203.104.30 LB_ROLE=master EX_APISERVER_VIP=10.203.104.212 EX_APISERVER_PORT=6443
#10.203.104.31 LB_ROLE=backup EX_APISERVER_VIP=10.203.104.212 EX_APISERVER_PORT=6443
# [optional] ntp server for the cluster
[chrony]
#10.203.104.1
[all:vars]
# --------- Main Variables ---------------
# Cluster container-runtime supported: docker, containerd
CONTAINER_RUNTIME="docker"
# Network plugins supported: calico, flannel, kube-router, cilium, kube-ovn
CLUSTER_NETWORK="flannel"
# Service proxy mode of kube-proxy: 'iptables' or 'ipvs'
PROXY_MODE="ipvs"
# K8S Service CIDR, not overlap with node(host) networking
SERVICE_CIDR="172.28.0.0/16"
# Cluster CIDR (Pod CIDR), not overlap with node(host) networking
CLUSTER_CIDR="10.20.0.0/16"
# NodePort Range
NODE_PORT_RANGE="30000-60000"
# Cluster DNS Domain
CLUSTER_DNS_DOMAIN="linux.local."
# -------- Additional Variables (don't change the default value right now) ---
# Binaries Directory
bin_dir="/usr/bin"
# CA and other components cert/key Directory
ca_dir="/etc/kubernetes/ssl"
# Deploy Directory (kubeasz workspace)
base_dir="/etc/ansible"
验证ansible安装
root@master1:~# ansible all -m ping
10.203.104.27 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.26 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.23 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.24 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.28 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.30 | FAILED! => {
"changed": false,
"module_stderr": "/bin/sh: 1: /usr/bin/python: not found\n",
"module_stdout": "",
"msg": "MODULE FAILURE",
"rc": 127
}
10.203.104.25 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.21 | SUCCESS => {
"changed": false,
"ping": "pong"
}
10.203.104.20 | SUCCESS => {
"changed": false,
"ping": "pong"
}
相关配置文件
定义了默认的变量
root@master1:/etc/ansible# cat /etc/ansible/roles/deploy/defaults/main.yml
# CA 证书相关参数
CA_EXPIRY: "876000h"
CERT_EXPIRY: "438000h"
# apiserver 默认第一个master节点
KUBE_APISERVER: "https://{{ groups['kube-master'][0] }}:6443"
CLUSTER_NAME: "cluster1"
CREATE_READONLY_KUBECONFIG: false
定义了kube-proxy证书请求文件
root@master1:/etc/ansible# vim /etc/ansible/roles/deploy/templates/admin-csr.json.j2
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "HangZhou",
"L": "XS",
"O": "system:masters",
"OU": "System"
}
]
}
etcd的主文件
root@master1:/etc/ansible# ls roles/etcd/tasks/main.yml
roles/etcd/tasks/main.yml
etcd的启动配置文件
root@master1:/etc/ansible# cat roles/etcd/templates/etcd.service.j2
部署
环境初始化
root@master1:/etc/ansible# ansible-playbook 01.prepare.yml
最终输出结果如下
PLAY RECAP *******************************************************************************************************************************************************************************************************************************************************************
10.203.104.20 : ok=28 changed=21 unreachable=0 failed=0
10.203.104.21 : ok=28 changed=23 unreachable=0 failed=0
10.203.104.23 : ok=22 changed=17 unreachable=0 failed=0
10.203.104.24 : ok=22 changed=17 unreachable=0 failed=0
10.203.104.25 : ok=22 changed=17 unreachable=0 failed=0
10.203.104.26 : ok=26 changed=21 unreachable=0 failed=0
10.203.104.27 : ok=26 changed=21 unreachable=0 failed=0
10.203.104.28 : ok=26 changed=21 unreachable=0 failed=0
localhost : ok=35 changed=26 unreachable=0 failed=0
部署etcd集群
root@master1:/etc/ansible# ansible-playbook 02.etcd.ym
输出结果为
PLAY RECAP *******************************************************************************************************************************************************************************************************************************************************************
10.203.104.23 : ok=10 changed=9 unreachable=0 failed=0
10.203.104.24 : ok=10 changed=9 unreachable=0 failed=0
10.203.104.25 : ok=10 changed=9 unreachable=0 failed=0
验证etcd服务
root@etcd1:~# ps -ef | grep etcd
![]()
root@etcd1:~# export NODE_IPS="10.203.104.23 10.203.104.24 10.203.104.25"
root@etcd1:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem endpoint health; done
https://10.203.104.23:2379 is healthy: successfully committed proposal: took = 7.246214ms
https://10.203.104.24:2379 is healthy: successfully committed proposal: took = 7.025557ms
https://10.203.104.25:2379 is healthy: successfully committed proposal: took = 7.120852ms
![]()
安装docker
docker的amsible主配置文件
root@master1:/etc/ansible# cat roles/docker/tasks/main.yml
解压docker-19.03.8.tgz文件,在其他节点安装docker-19.03.8
root@master1:/etc/ansible/down# tar xvf docker-19.03.8.tgz
root@master1:/etc/ansible/down# cp ./docker/* /etc/ansible/bin/
root@master1:/etc/ansible# ansible-playbook 03.docker.yml
如在安装过程中提示Containerd already installed的错误,可手动关闭错误节点上的containerd服务。再次安装
root@master1:/etc/ansible# systemctl stop containerd
root@master1:/etc/ansible# ansible-playbook 03.docker.yml
PLAY RECAP *******************************************************************************************************************************************************************************************************************************************************************
10.203.104.20 : ok=17 changed=12 unreachable=0 failed=0
10.203.104.21 : ok=16 changed=6 unreachable=0 failed=0
10.203.104.26 : ok=16 changed=11 unreachable=0 failed=0
10.203.104.27 : ok=16 changed=11 unreachable=0 failed=0
10.203.104.28 : ok=16 changed=11 unreachable=0 failed=0
docker证书文件
在master1节点上准备docker的证书文件
创建存放docker证书的目录
root@master1:/etc/ansible# mkdir /etc/docker/certs.d/harbor.linux.com/ -p
在harbor上将证书公钥文件拷贝到master1节点上
root@harbor:~# scp /usr/local/src/harbor/certs/harbor-ca.crt master1:/etc/docker/certs.d/harbor.linux.com/
root@master1:/etc/ansible# ll /etc/docker/certs.d/harbor.linux.com/harbor-ca.crt
-rw-r--r-- 1 root root 1131 Jun 13 18:14 /etc/docker/certs.d/harbor.linux.com/harbor-ca.crt
验证docker即可登录
root@master1:/etc/ansible# docker login harbor.linux.com
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
将docker证书文件分发给其他节点
将证书文件备份一份在/opt/目录下
root@master1:/etc/ansible# cp /etc/docker/certs.d/harbor.linux.com/harbor-ca.crt /opt/
将/opt/harbor-ca.crt证书文件分发到其他节点
root@master1:~# cat scp_ca.sh
#!/bin/bash
#目标主机列表
IP="
10.203.104.20
10.203.104.21
10.203.104.22
10.203.104.23
10.203.104.24
10.203.104.25
10.203.104.26
10.203.104.27
10.203.104.28
"
for node in ${IP};do
ssh ${node} "mkdir /etc/docker/certs.d/harbor.linux.com -p"
echo "Harbor 证书目录创建成功!"
scp /opt/harbor-ca.crt ${node}:/etc/docker/certs.d/harbor.linux.com/harbor-ca.crt
echo "Harbor 证书拷贝成功!"
done
部署master
主配置文件
root@master1:/etc/ansible# vim roles/kube-master/tasks/main.yml
root@master1:/etc/ansible# ansible-playbook 04.kube-master.yml
root@master1:/etc/ansible# kubectl get node
NAME STATUS ROLES AGE VERSION
10.203.104.20 Ready,SchedulingDisabled master 31s v1.17.4
10.203.104.21 Ready,SchedulingDisabled master 31s v1.17.4
部署node
准备配置文件
root@master1:/etc/ansible# cat roles/kube-node/tasks/main.yml
root@master1:/etc/ansible# cat roles/kube-node/templates/kube-proxy.service.j2
kubelet.service.j2文件中使用了镜像地址为--pod-infra-container-image={{ SANDBOX_IMAGE }}
root@master1:/etc/ansible# cat roles/kube-node/templates/kubelet.service.j2
查看SANDBOX_IMAGE变量指定的镜像地址配置
root@master1:/etc/ansible# grep SANDBOX_IMAGE roles/kube-node/ -R
roles/kube-node/defaults/main.yml:SANDBOX_IMAGE: "mirrorgooglecontainers/pause-amd64:3.1"
roles/kube-node/defaults/main.yml:#SANDBOX_IMAGE: "registry.access.redhat.com/rhel7/pod-infrastructure:latest"
roles/kube-node/templates/kubelet.service.j2: --pod-infra-container-image={{ SANDBOX_IMAGE }} \
修改镜像地址为可用的镜像地址
root@master1:/etc/ansible# vim roles/kube-node/defaults/main.yml
SANDBOX_IMAGE: "mirrorgooglecontainers/pause-amd64:3.1"
可先将mirrorgooglecontainers/pause-amd64:3.1 镜像下载到harbor,然后再文件中指定镜像地址为harbor
root@master1:~# docker tag mirrorgooglecontainers/pause-amd64:3.1 harbor.linux.com/baseimages/pause-amd64:3.1
root@master1:~# docker push harbor.linux.com/baseimages/pause-amd64:3.1
The push refers to repository [harbor.linux.com/baseimages/pause-amd64]
e17133b79956: Pushed
3.1: digest: sha256:fcaff905397ba63fd376d0c3019f1f1cb6e7506131389edbcb3d22719f1ae54d size: 527
SANDBOX_IMAGE镜像地址修改为harbor.linux.com/baseimages/pause-amd64:3.1
root@master1:/etc/ansible# vim roles/kube-node/defaults/main.yml
SANDBOX_IMAGE: "harbor.linux.com/baseimages/pause-amd64:3.1"
部署
root@master1:/etc/ansible# ansible-playbook 05.kube-node.yml
root@master1:/etc/ansible# kubectl get node
NAME STATUS ROLES AGE VERSION
10.203.104.20 Ready,SchedulingDisabled master 14m v1.17.4
10.203.104.21 Ready,SchedulingDisabled master 14m v1.17.4
10.203.104.26 Ready node 64s v1.17.4
10.203.104.27 Ready node 64s v1.17.4
10.203.104.28 Ready node 64s v1.17.4
部署network
root@master1:/etc/ansible# vim roles/flannel/tasks/main.yml
root@master1:/etc/ansible# cat roles/flannel/templates/kube-flannel.yaml.j2
部署
root@master1:/etc/ansible# ansible-playbook 06.network.yml
测试容器内外通信
root@master1:~# kubectl run net-test2 --image=harbor.linux.com/baseimages/busybox:latest --replicas=4 sleep 360000
root@master1:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
net-test2-565b5f575-fjc78 1/1 Running 0 36s 10.20.4.3 10.203.104.28
net-test2-565b5f575-h692c 1/1 Running 0 36s 10.20.3.5 10.203.104.26
net-test2-565b5f575-qczh4 1/1 Running 0 36s 10.20.4.4 10.203.104.28
net-test2-565b5f575-rlcwz 1/1 Running 0 36s 10.20.2.4 10.203.104.27
root@master1:~# kubectl exec -it net-test2-565b5f575-fjc78 sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr A2:35:54:97:72:44
inet addr:10.20.4.3 Bcast:0.0.0.0 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:13 errors:0 dropped:0 overruns:0 frame:0
TX packets:1 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:950 (950.0 B) TX bytes:42 (42.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 10.20.3.5
PING 10.20.3.5 (10.20.3.5): 56 data bytes
64 bytes from 10.20.3.5: seq=0 ttl=62 time=0.591 ms
64 bytes from 10.20.3.5: seq=1 ttl=62 time=0.323 ms
^C
--- 10.20.3.5 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.323/0.457/0.591 ms
/ # ping 10.203.129.1
PING 10.203.129.1 (10.203.129.1): 56 data bytes
64 bytes from 10.203.129.1: seq=0 ttl=122 time=0.415 ms
集群添加master节点
添加的maste节点IP为10.203.104.22
root@master1:/etc/ansible# easzctl add-master 10.203.104.22
![]()
root@master1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
10.203.104.20 Ready,SchedulingDisabled master 142m v1.17.4
10.203.104.21 Ready,SchedulingDisabled master 142m v1.17.4
10.203.104.22 Ready,SchedulingDisabled master 4m34s v1.17.4
10.203.104.26 Ready node 128m v1.17.4
10.203.104.27 Ready node 128m v1.17.4
集群添加node节点
添加的node节点IP为10.203.104.28
root@master1:/etc/ansible# easzctl add-node 10.203.104.28
集群中移除master和node
移除master
root@master1:/etc/ansible# easzctl del-master 10.203.104.22
移除node
root@master1:/etc/ansible# easzctl del-node 10.203.104.28
集群升级
官网release下载待升级的k8s版本以下二进制文件
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.17.md#downloads-for-v1174
kubernetes.tar.gz
kubernetes-client-linux-amd64.tar.gz
kubernetes-server-linux-amd64.tar.gz
kubernetes-node-linux-amd64.tar.gz
集群升级,实际上就是升级以下六个二进制程序
kube-apiserver
kube-controller-manager
kubectl
kubelet
kube-proxy
kube-scheduler
升级前的准备和二进制文件备份
root@master1:~# tar -zxvf kubernetes-server-linux-amd64.tar.gz
root@master1:~# ll kubernetes/server/bin/
新建两个文件夹,用于存放升级前后的可执行程序
root@master1:~# mkdir /opt/k8s-1.17.4
root@master1:~# mkdir /opt/k8s-1.17.2
将当前ansible中的相关二进制程序拷贝到/opt/k8s-1.17.2目录下备份
root@master1:~# cd /etc/ansible/bin/
root@master1:/etc/ansible/bin# cp kube-apiserver kube-controller-manager kubectl kubelet kube-proxy kube-scheduler /opt/k8s-1.17.2/
将kubernetes-server-linux-amd64.tar.gz解压之后的二进制程序拷贝到/opt/k8s-1.17.4/下
root@master1:~# cd /kubernetes/server/bin/
root@master1:~/kubernetes/server/bin# cp kube-apiserver kube-controller-manager kubectl kubelet kube-proxy kube-scheduler /opt/k8s-1.17.4/
单台机器手动升级
master升级
升级时,须先提前将以下服务停止
- kube-apiserver.service
- kube-controller-manager.service
- kubelet.service
- kube-scheduler.service
- kube-proxy.service
需先将服务停止
root@master1:~# systemctl stop kube-apiserver.service kube-controller-manager.service kubelet.service kube-scheduler.service kube-proxy.service
二进制文件拷贝
将/opt/k8s-1.17.4下的新版本二进制文件拷贝至/usr/bin/下
root@master1:/opt/k8s-1.17.4# cp ./* /usr/bin
启动服务
root@master1:~# systemctl start kube-apiserver.service kube-controller-manager.service kubelet.service kube-scheduler.service kube-proxy.service
node升级
升级时,必须先提前将以下服务停止
- kubelet.service
- kube-proxy.service
先将node上的服务停止
root@node3:~# systemctl stop kubelet.service kube-proxy.service
在master上将新版本的kubectl kubelet kube-proxy二进制文件拷贝至/usr/bin/下
root@master1:/opt/k8s-1.17.4# scp kubectl kubelet kube-proxy node3:/usr/bin/
在node上启动服务
root@node3:~# systemctl start kubelet.service kube-proxy.service
easzctl工具升级
将新版本的二进制文件拷贝至/etc/ansible/bin
root@master1:/opt/k8s-1.17.4# ls
kube-apiserver kube-controller-manager kubectl kubelet kube-proxy kube-scheduler
将/opt/k8s-1.17.4下的新版本二进制文件拷贝至/etc/ansible/bin/下
root@master1:/opt/k8s-1.17.4# cp ./* /etc/ansible/bin/
root@master1:~/etc/ansible/bin/# ./kube-apiserver --version
Kubernetes v1.17.4
开始升级
root@master1:/etc/ansible# easzctl upgrade
查看升级后的版本
root@master1:/etc/ansible# kubectl get node
NAME STATUS ROLES AGE VERSION
10.203.104.20 Ready,SchedulingDisabled master 3h36m v1.17.4
10.203.104.21 Ready,SchedulingDisabled master 3h36m v1.17.4
10.203.104.22 Ready,SchedulingDisabled master 79m v1.17.4
10.203.104.26 Ready node 3h23m v1.17.4
10.203.104.27 Ready node 3h23m v1.17.4
10.203.104.28 Ready node 3h23m v1.17.4
部署dashboard
准备配置文件
准备dashboard-2.0.0-rc6.yml 和admin-user.yml 文件
root@master1:~# cd /etc/ansible/manifests/dashboard/
root@master1:/etc/ansible/manifests/dashboard# mkdir dashboard-2.0.6
将dashboard-2.0.0-rc6.yml文件和admin-user.yml文件上传
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# ls
admin-user.yml dashboard-2.0.0-rc6.yml
dashboard-2.0.0-rc6.yml
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# cat dashboard-2.0.0-rc6.yml
# Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30002
selector:
k8s-app: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kubernetes-dashboard
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-csrf
namespace: kubernetes-dashboard
type: Opaque
data:
csrf: ""
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
rules:
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs", "kubernetes-dashboard-csrf"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster", "dashboard-metrics-scraper"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:", "dashboard-metrics-scraper", "http:dashboard-metrics-scraper"]
verbs: ["get"]
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: harbor.linux.com/baseimages/dashboard:v2.0.0-rc6
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
ports:
- port: 8000
targetPort: 8000
selector:
k8s-app: dashboard-metrics-scraper
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: dashboard-metrics-scraper
template:
metadata:
labels:
k8s-app: dashboard-metrics-scraper
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'runtime/default'
spec:
containers:
- name: dashboard-metrics-scraper
image: harbor.linux.com/baseimages/metrics-scraper:v1.0.3
ports:
- containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 8000
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- mountPath: /tmp
name: tmp-volume
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
volumes:
- name: tmp-volume
emptyDir: {}
admin-user.yml
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# cat admin-user.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
运行dashboard
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# kubectl apply -f dashboard-2.0.0-rc6.yml
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# kubectl apply -f admin-user.yml
root@master1:~# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-amd64-4dvn9 1/1 Running 0 4h59m
kube-system kube-flannel-ds-amd64-6zk8z 1/1 Running 0 4h59m
kube-system kube-flannel-ds-amd64-d54j4 1/1 Running 0 4h59m
kube-system kube-flannel-ds-amd64-hmnsj 1/1 Running 0 3h8m
kube-system kube-flannel-ds-amd64-k52kz 1/1 Running 0 4h59m
kube-system kube-flannel-ds-amd64-q42lh 1/1 Running 0 4h59m
kubernetes-dashboard dashboard-metrics-scraper-665dccf555-xlsm2 1/1 Running 0 5m
kubernetes-dashboard kubernetes-dashboard-745b4b66f4-4x7h7 1/1 Running 0 5m1s
登录验证dashboard
查找dashboard密钥
root@master1:~# kubectl get secret -A | grep admin
kubernetes-dashboard admin-user-token-xlls2 kubernetes.io/service-account-token 3 5m2s
root@master1:~# kubectl describe secret admin-user-token-xlls2 -n kubernetes-dashboard
Name: admin-user-token-xlls2
Namespace: kubernetes-dashboard
Labels:
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 0d0288df-7e0b-4899-859b-0e346a92cba2
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1350 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkR5eEg0ckg0VFlTYkdEcUtTUzFad3R6OEJzOVJHdFRsZ0tGTGVUUFJiTncifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXhsbHMyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIwZDAyODhkZi03ZTBiLTQ4OTktODU5Yi0wZTM0NmE5MmNiYTIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.dYLyBTl2NT1rECKIvnQz8PXXXx3q80YSkAVG-4qL17wEignE2PEaJe4XChWYfXTQ95cKVQnhjv0JhnMChyA2ttu7wGaR-Vl3L2KkRwkSWxyOJ_zCbeg80vlXMW4jqzU5A0oiG5i6qBtLRGdYmKRPOgMcjwPFJbkauThknSmWCfrV5_p3JBmlSCMzsKm2BB1j2F1I_6ifNX5bbTLUpVEHrpQCh2nPREniVWsHCV61cbEOR0i6ya0dkzYTOjnNDeayKQiZNABWAFHLXwIRyrwH8PBErg-JqOMlJXJg9VTOwILazSKkfDavis8eBuaJoiK6N8AEmOXLu5s31R-Xs8ACRQ
Token方式登录dashboard
查看dashboard的port端口
root@master1:~# kubectl get service -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 172.28.0.1 443/TCP 5h29m
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 172.28.163.238 8000/TCP 8m3s
kubernetes-dashboard kubernetes-dashboard NodePort 172.28.62.60 443:30002/TCP 8m3s
将admin-user-token的token直接填入web界面
Kubeconfig方式登录dashboard
拷贝一份kube的配置文件做修改
root@k8s-master1:~# cp /root/.kube/config /opt/kubeconfig
将token信息追加到配置文件最后

将添加token后的kubeconfig文件存放于电脑本地,每次登录时选中该文件即可登录
设置token的会话超时时间
查找args字段,添加--token-ttl=3600
root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# vim dashboard-2.0.0-rc6.yml
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
- --token-ttl=3600

root@master1:/etc/ansible/manifests/dashboard/dashboard-2.0.6# kubectl apply -f dashboard-2.0.0-rc6.yml
DNS
目前常用的dns组件有kube-dns和coredns两个,用于解析k8s集群中service name所对应得到IP地址
推荐使用CoreDNS
- skyDNS/kube-dns/coreDNS
kube-dns
将官方kubernetes二进制文件解压获取kube-dns的示例yaml文件
root@master1:~# tar -zxf kubernetes.tar.gz
root@master1:~# tar -zxf kubernetes-client-linux-amd64.tar.gz
root@master1:~# tar -zxf kubernetes-node-linux-amd64.tar.gz
root@master1:~# tar -zxf kubernetes-server-linux-amd64.tar.gz
- kube-dns:提供service name域名的解析
- dns-dnsmasq:提供DNS缓存,降低kubedns负载,提高性能
- dns-sidecar:定期检查kubedns和dnsmasq的健康状态
下载镜像并上传到harbor
由于无法从k8s.gcr.io中下载镜像,在此使用registry.cn-hangzhou.aliyuncs.com镜像下载
root@master1:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-sidecar-amd64:1.14.13
root@master1:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-kube-dns-amd64:1.14.13
root@master1:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.13
root@master1:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-sidecar-amd64 1.14.13 4b2e93f0133d 21 months ago 42.9MB
registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-kube-dns-amd64 1.14.13 55a3c5209c5e 21 months ago 51.2MB
registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-dnsmasq-nanny-amd64 1.14.13 6dc8ef8287d3 21 months ago 41.4MB
将镜像上传到harbor
root@master1:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-sidecar-amd64:1.14.13 harbor.linux.com/baseimages/k8s-dns-sidecar-amd64:1.14.13
root@master1:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-kube-dns-amd64:1.14.13 harbor.linux.com/baseimages/k8s-dns-kube-dns-amd64:1.14.13
root@master1:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.13 harbor.linux.com/baseimages/k8s-dns-dnsmasq-nanny-amd64:1.14.13
root@master1:~# docker push harbor.linux.com/baseimages/k8s-dns-kube-dns-amd64:1.14.13
root@master1:~# docker push harbor.linux.com/baseimages/k8s-dns-sidecar-amd64:1.14.13
root@master1:~# docker push harbor.linux.com/baseimages/k8s-dns-dnsmasq-nanny-amd64:1.14.13
准备kube-dns.yaml文件
将kubernetes二进制文件解压,获取kube-dns的示例yml文件
二进制文件解压之后生成kubernetes目录
root@master1:~# cd kubernetes/cluster/addons/dns/kube-dns/
root@master1:~/kubernetes/cluster/addons/dns/kube-dns# ls
kube-dns.yaml.base kube-dns.yaml.in kube-dns.yaml.sed Makefile README.md transforms2salt.sed transforms2sed.sed
root@master1:~/kubernetes/cluster/addons/dns/kube-dns# cp kube-dns.yaml.base /root/kube-dns.yaml
修改后的kube-dns.yaml 文件内容
-
clusterIP: 172.28.0.2 指的是容器中查看到的指向DNS的地址
-
kubedns的memory限制为1024Mi
-
--domain=linux.local. ansible的hosts文件中指定的domain name
-
kube-dns.yaml 文件中有替换了多次linux.local
-
iamge指向harbor.linux.com
-
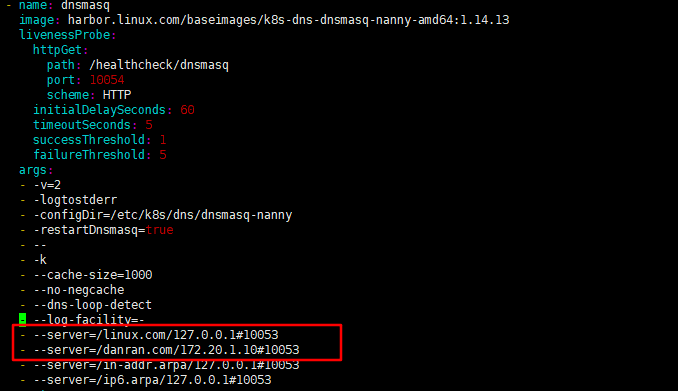
在dnsmasp容器的args字段添加了一个系的呢DNS server,即--server=/danran.com/172.20.1.10#10053
root@master1:~# cat kube-dns.yaml # Copyright 2016 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Should keep target in cluster/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml # in sync with this file. # __MACHINE_GENERATED_WARNING__ apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 172.28.0.2 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP --- apiVersion: v1 kind: ServiceAccount metadata: name: kube-dns namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: v1 kind: ConfigMap metadata: name: kube-dns namespace: kube-system labels: addonmanager.kubernetes.io/mode: EnsureExists --- apiVersion: apps/v1 kind: Deployment metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: # replicas: not specified here: # 1. In order to make Addon Manager do not reconcile this replicas parameter. # 2. Default is 1. # 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on. strategy: rollingUpdate: maxSurge: 10% maxUnavailable: 0 selector: matchLabels: k8s-app: kube-dns template: metadata: labels: k8s-app: kube-dns annotations: seccomp.security.alpha.kubernetes.io/pod: 'runtime/default' prometheus.io/port: "10054" prometheus.io/scrape: "true" spec: priorityClassName: system-cluster-critical securityContext: supplementalGroups: [ 65534 ] fsGroup: 65534 tolerations: - key: "CriticalAddonsOnly" operator: "Exists" nodeSelector: beta.kubernetes.io/os: linux volumes: - name: kube-dns-config configMap: name: kube-dns optional: true containers: - name: kubedns image: harbor.linux.com/baseimages/k8s-dns-kube-dns-amd64:1.14.13 resources: # TODO: Set memory limits when we've profiled the container for large # clusters, then set request = limit to keep this container in # guaranteed class. Currently, this container falls into the # "burstable" category so the kubelet doesn't backoff from restarting it. limits: memory: 1024Mi requests: cpu: 100m memory: 70Mi livenessProbe: httpGet: path: /healthcheck/kubedns port: 10054 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 readinessProbe: httpGet: path: /readiness port: 8081 scheme: HTTP # we poll on pod startup for the Kubernetes master service and # only setup the /readiness HTTP server once that's available. initialDelaySeconds: 3 timeoutSeconds: 5 args: - --domain=linux.local. - --dns-port=10053 - --config-dir=/kube-dns-config - --v=2 env: - name: PROMETHEUS_PORT value: "10055" ports: - containerPort: 10053 name: dns-local protocol: UDP - containerPort: 10053 name: dns-tcp-local protocol: TCP - containerPort: 10055 name: metrics protocol: TCP volumeMounts: - name: kube-dns-config mountPath: /kube-dns-config securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsUser: 1001 runAsGroup: 1001 - name: dnsmasq image: harbor.linux.com/baseimages/k8s-dns-dnsmasq-nanny-amd64:1.14.13 livenessProbe: httpGet: path: /healthcheck/dnsmasq port: 10054 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 args: - -v=2 - -logtostderr - -configDir=/etc/k8s/dns/dnsmasq-nanny - -restartDnsmasq=true - -- - -k - --cache-size=1000 - --no-negcache - --dns-loop-detect - --log-facility=- - --server=/linux.com/127.0.0.1#10053 - --server=/danran.com/172.20.1.10#10053 - --server=/in-addr.arpa/127.0.0.1#10053 - --server=/ip6.arpa/127.0.0.1#10053 ports: - containerPort: 53 name: dns protocol: UDP - containerPort: 53 name: dns-tcp protocol: TCP # see: https://github.com/kubernetes/kubernetes/issues/29055 for details resources: requests: cpu: 150m memory: 20Mi volumeMounts: - name: kube-dns-config mountPath: /etc/k8s/dns/dnsmasq-nanny securityContext: capabilities: drop: - all add: - NET_BIND_SERVICE - SETGID - name: sidecar image: harbor.linux.com/baseimages/k8s-dns-sidecar-amd64:1.14.13 livenessProbe: httpGet: path: /metrics port: 10054 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 args: - --v=2 - --logtostderr - --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.linux.local,5,SRV - --probe=dnsmasq,127.0.0.1:53,kubernetes.default.svc.linux.local,5,SRV ports: - containerPort: 10054 name: metrics protocol: TCP resources: requests: memory: 20Mi cpu: 10m securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsUser: 1001 runAsGroup: 1001 dnsPolicy: Default # Don't use cluster DNS. serviceAccountName: kube-dns
运行kube-dns
root@master1:~# kubectl apply -f kube-dns.yaml
service/kube-dns created
serviceaccount/kube-dns created
configmap/kube-dns created
deployment.apps/kube-dns created
CoreDNS
-
deployment地址
https://github.com/coredns/deployment/tree/master/kubernetes -
将coreDNS项目从github上下载
https://github.com/coredns/deployment
生成CoreDNS配置文件
root@master1:/etc/ansible/manifests/dns/coredns# ls
deployment-master.zip kusybox.yaml
root@master1:/etc/ansible/manifests/dns/coredns# unzip deployment-master.zip
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master# ls
debian docker kubernetes LICENSE Makefile README.md systemd
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master/kubernetes# ls
CoreDNS-k8s_version.md coredns.yaml.sed corefile-tool deploy.sh FAQs.md migration README.md rollback.sh Scaling_CoreDNS.md Upgrading_CoreDNS.m
指定-i 指向Pod中的DNS, 172.28.0.2为容器中查看到的dns 地址
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master/kubernetes# ./deploy.sh -i 172.28.0.2 > coredns.yml
coredns.yml
将coredns/coredns的镜像下载后上传到harbor,配置文件中的image指向harbor地址
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master/kubernetes# vim coredns.yml
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master/kubernetes# cat coredns.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes linux.local in-addr.arpa ip6.arpa {
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
#forward . /etc/resolv.conf
forward . 10.203.24.132
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. Default is 1.
# 2. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
priorityClassName: system-cluster-critical
serviceAccountName: coredns
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
containers:
- name: coredns
image: harbor.linux.com/baseimages/coredns:1.6.6
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 172.28.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP



部署
root@master1:/etc/ansible/manifests/dns/coredns/deployment-master/kubernetes# kubectl apply -f coredns.yml
serviceaccount/coredns created
clusterrole.rbac.authorization.k8s.io/system:coredns created
clusterrolebinding.rbac.authorization.k8s.io/system:coredns created
configmap/coredns created
deployment.apps/coredns created
service/kube-dns created
测试不同namespace中的DNS解析
创建kusybox pod
root@master1:/etc/ansible/manifests/dns/coredns# vim kusybox.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: harbor.linux.com/baseimages/busybox:latest
command:
- sleep
- "3600"
imagePullPolicy: Always
name: busybox
restartPolicy: Always
root@master1:/etc/ansible/manifests/dns/coredns# kubectl apply -f kusybox.yaml
pod/busybox created
测试Pod中DNS解析
-
pod中解析不同namespace中的name,需使用NAME.NAMESPACE.svc.DOMAIN
EG:ping dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.localroot@master1:~# kubectl get pod -A NAMESPACE NAME READY STATUS RESTARTS AGE default busybox 1/1 Running 0 51m kube-system coredns-85bd4f9784-95qcb 1/1 Running 0 4m16s kube-system kube-flannel-ds-amd64-4dvn9 1/1 Running 0 17h kube-system kube-flannel-ds-amd64-6zk8z 1/1 Running 0 17h kube-system kube-flannel-ds-amd64-d54j4 1/1 Running 0 17h kube-system kube-flannel-ds-amd64-hmnsj 1/1 Running 0 15h kube-system kube-flannel-ds-amd64-k52kz 1/1 Running 0 17h kube-system kube-flannel-ds-amd64-q42lh 1/1 Running 0 17h kubernetes-dashboard dashboard-metrics-scraper-665dccf555-xlsm2 1/1 Running 0 12h kubernetes-dashboard kubernetes-dashboard-6d489b6474-h7cqw 1/1 Running 0 12h pod中解析不同namespace中的name,需使用NAME.NAMESPACE.svc.DOMAIN,egdashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local root@master1:~# kubectl exec busybox nslookup dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local Server: 172.28.0.2 Address 1: 172.28.0.2 kube-dns.kube-system.svc.linux.local Name: dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local Address 1: 172.28.163.238 dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local root@master1:~# kubectl exec busybox -it sh / # ping dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local PING dashboard-metrics-scraper.kubernetes-dashboard.svc.linux.local (172.28.163.238): 56 data bytes 64 bytes from 172.28.163.238: seq=0 ttl=64 time=0.032 ms 64 bytes from 172.28.163.238: seq=1 ttl=64 time=0.072 ms / # ping v.xx-xx.com PING v.saic-gm.com (10.204.4.163): 56 data bytes 64 bytes from 10.204.4.163: seq=0 ttl=250 time=0.216 ms 64 bytes from 10.204.4.163: seq=1 ttl=250 time=0.303 ms
Etcd
启动脚本参数
root@etcd1:~# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/ #数据保存目录
ExecStart=/usr/bin/etcd \ #二进制文件路径
--name=etcd1 \ #当前node 名称
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
--peer-cert-file=/etc/etcd/ssl/etcd.pem \
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--initial-advertise-peer-urls=https://10.203.104.23:2380 \ #通告自己的集群端口
--listen-peer-urls=https://10.203.104.23:2380 \ #集群之间通讯端口
--listen-client-urls=https://10.203.104.23:2379,http://127.0.0.1:2379 \ #客户端访问地址
--advertise-client-urls=https://10.203.104.23:2379 \ #通告自己的客户端端口
--initial-cluster-token=etcd-cluster-0 \ #创建集群使用的token,一个集群内的节点保持一致
--initial-cluster=etcd1=https://10.203.104.23:2380,etcd2=https://10.203.104.24:2380,etcd3=https://10.203.104.25:2380 \ #集群所有的节点信息
--initial-cluster-state=new \ #新建集群的时候的值为new,如果是已经存在的集群为existing。
--data-dir=/var/lib/etcd #数据目录路径
Restart=always
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
查看成员信息
root@etcd1:~# ETCDCTL_API=3 etcdctl member list --endpoints=https://10.203.104.23:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem
root@etcd1:~# etcdctl member list
204af522c33d52e1, started, etcd3, https://10.203.104.25:2380, https://10.203.104.25:2379, false
4839e069f5632f0a, started, etcd2, https://10.203.104.24:2380, https://10.203.104.24:2379, false
e15abba3588e6a04, started, etcd1, https://10.203.104.23:2380, https://10.203.104.23:2379, false
验证etcd所有成员的状态
root@etcd1:~# export NODE_IPS="10.203.104.23 10.203.104.24 10.203.104.25"
root@etcd1:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem endpoint health; done
https://10.203.104.23:2379 is healthy: successfully committed proposal: took = 7.246214ms
https://10.203.104.24:2379 is healthy: successfully committed proposal: took = 7.025557ms
https://10.203.104.25:2379 is healthy: successfully committed proposal: took = 7.120852ms
![]()
查看etcd数据信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only | grep coredns
/registry/clusterrolebindings/system:coredns
/registry/clusterroles/system:coredns
/registry/configmaps/kube-system/coredns
/registry/deployments/kube-system/coredns
/registry/pods/kube-system/coredns-85bd4f9784-95qcb
/registry/replicasets/kube-system/coredns-85bd4f9784
/registry/secrets/kube-system/coredns-token-ssflx
/registry/serviceaccounts/kube-system/coredns
查看 /registry/pods/kube-system/coredns-85bd4f9784-95qcb API的数据信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get /registry/pods/kube-system/coredns-85bd4f9784-95qcb
etcd增删改查
添加数据
root@etcd1:~# ETCDCTL_API=3 /usr/bin/etcdctl put /name "danran"
OK
root@etcd1:~# ETCDCTL_API=3 /usr/bin/etcdctl get /name
/name
danran
查询数据
root@etcd1:~# ETCDCTL_API=3 /usr/bin/etcdctl get /name
/name
danran
root@etcd2:~# etcdctl version
etcdctl version: 3.4.3
API version: 3.4
root@etcd2:~# /usr/bin/etcdctl get /name
/name
danran
修改数据
root@etcd1:~# ETCDCTL_API=3 /usr/bin/etcdctl put /name "JevonWei"
OK
root@etcd1:~# /usr/bin/etcdctl get /name
/name
JevonWei
删除数据
del删除数据,返回值为1,则删除成功
root@etcd1:~# /usr/bin/etcdctl del /name
1
root@etcd1:~# /usr/bin/etcdctl get /name
在maste上看下需要删除的pod,在此删除 ImagePullBackOff异常的pod
root@master1:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 5 5h49m
net-test1-69d7858669-8mh47 0/1 ImagePullBackOff 0 74s
net-test1-69d7858669-dtz5r 0/1 ImagePullBackOff 0 19h
net-test1-69d7858669-hpqcn 0/1 ImagePullBackOff 0 22h
net-test1-69d7858669-tmwm4 0/1 ImagePullBackOff 0 22h
net-test2-565b5f575-b28kf 1/1 Running 0 19h
net-test2-565b5f575-h692c 1/1 Running 0 22h
net-test2-565b5f575-rlcwz 1/1 Running 0 22h
net-test2-565b5f575-wwkl2 1/1 Running 0 19h
查看需要删除pod所属的deployment为net-test1
root@master1:~# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
net-test1 0/4 4 0 22h
net-test2 4/4 4 4 22h
在etcd上过滤需要删除的net-test1 deployment的API
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only | grep net-test1
/registry/deployments/default/net-test1
/registry/events/default/net-test1-69d7858669-8mh47.1618604ea2140450
/registry/events/default/net-test1-69d7858669-8mh47.1618604ed4dee5db
/registry/events/default/net-test1-69d7858669-8mh47.1618604ed51ae32c
/registry/events/default/net-test1-69d7858669-8mh47.1618604ed51b1263
/registry/events/default/net-test1-69d7858669-8mh47.1618604eef49d3e7
/registry/events/default/net-test1-69d7858669-8mh47.1618604eef49f923
/registry/events/default/net-test1-69d7858669-9j9gm.1618163de0bf41f6
/registry/events/default/net-test1-69d7858669-9j9gm.1618163e18ebb435
/registry/events/default/net-test1-69d7858669-9j9gm.1618163e18ebd4a3
/registry/events/default/net-test1-69d7858669-dtz5r.16181fe2fe8e8d23
/registry/events/default/net-test1-69d7858669-dtz5r.16181fe2fe8ebddb
/registry/events/default/net-test1-69d7858669-hpqcn.161816398dc13c64
/registry/events/default/net-test1-69d7858669-hpqcn.161816398dc15a27
/registry/events/default/net-test1-69d7858669-tmwm4.16181630b767c5ff
/registry/events/default/net-test1-69d7858669-tmwm4.16181630b767df2a
/registry/events/default/net-test1-69d7858669.1618604ea1e24963
/registry/pods/default/net-test1-69d7858669-8mh47
/registry/pods/default/net-test1-69d7858669-dtz5r
/registry/pods/default/net-test1-69d7858669-hpqcn
/registry/pods/default/net-test1-69d7858669-tmwm4
/registry/replicasets/default/net-test1-69d7858669
etcd删除deployment为net-test1的API信息
root@etcd1:~# etcdctl del /registry/deployments/default/net-test1
1
master确认pod是否删除成功
root@master1:~# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
net-test2 4/4 4 4 22h
root@master1:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 5 5h50m
net-test2-565b5f575-b28kf 1/1 Running 0 19h
net-test2-565b5f575-h692c 1/1 Running 0 22h
net-test2-565b5f575-rlcwz 1/1 Running 0 22h
net-test2-565b5f575-wwkl2 1/1 Running 0 19h
etcd数据watch机制
- 在etcd node1上watch一个key,没有此key也可以执行watch,后期可以再创建:
在etcd1上watch /name
root@etcd1:~# etcdctl watch /name
在etcd2上,为/name put一个value
root@etcd2:~# etcdctl put /name "danran"
OK
观察etcd1的watch结果
root@etcd1:~# etcdctl watch /name
PUT
/name
danran
etcd数据备份与恢复机制
- WAL是write ahead log的缩写,顾名思义,也就是在执行真正的写操作之前先写一个日志。
- wal: 存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要 先写入到WAL中
etcd v3版本数据备份与恢复
备份数据
root@etcd1:~# etcdctl snapshot save snapshot.db
{"level":"info","ts":1592130335.5922172,"caller":"snapshot/v3_snapshot.go:110","msg":"created temporary db file","path":"snapshot.db.part"}
{"level":"warn","ts":"2020-06-14T18:25:35.592+0800","caller":"clientv3/retry_interceptor.go:116","msg":"retry stream intercept"}
{"level":"info","ts":1592130335.592874,"caller":"snapshot/v3_snapshot.go:121","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":1592130335.6071215,"caller":"snapshot/v3_snapshot.go:134","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","took":0.014857253}
{"level":"info","ts":1592130335.6071875,"caller":"snapshot/v3_snapshot.go:143","msg":"saved","path":"snapshot.db"}
Snapshot saved at snapshot.db
root@etcd1:~# ll snapshot.db
-rw------- 1 root root 1925152 Jun 14 18:25 snapshot.db
恢复数据
将当前目录下的备份文件snapshot.db恢复至/opt/etcd目录下,/opt/etcd必须为新目录,自动会新建
root@etcd1:~# etcdctl snapshot restore snapshot.db --data-dir="/opt/etcd"
{"level":"info","ts":1592130606.7339287,"caller":"snapshot/v3_snapshot.go:287","msg":"restoring snapshot","path":"snapshot.db","wal-dir":"/opt/etcd/member/wal","data-dir":"/opt/etcd","snap-dir":"/opt/etcd/member/snap"}
{"level":"info","ts":1592130606.749432,"caller":"mvcc/kvstore.go:378","msg":"restored last compact revision","meta-bucket-name":"meta","meta-bucket-name-key":"finishedCompactRev","restored-compact-revision":256270}
{"level":"info","ts":1592130606.7538748,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"cdf818194e3a8c32","local-member-id":"0","added-peer-id":"8e9e05c52164694d","added-peer-peer-urls":["http://localhost:2380"]}
{"level":"info","ts":1592130606.7582352,"caller":"snapshot/v3_snapshot.go:300","msg":"restored snapshot","path":"snapshot.db","wal-dir":"/opt/etcd/member/wal","data-dir":"/opt/etcd","snap-dir":"/opt/etcd/member/snap"}
root@etcd1:~# systemctl start etcd
脚本自动备份
备份脚本
root@etcd1:~/scripts# mkdir /data/etcd1-backup-dir -p
root@etcd1:~/scripts# cat etcd-backup.sh
#!/bin/bash
source /etc/profile
DATE=`date +%Y-%m-%d_%H-%M-%S`
ETCDCTL_API=3 /usr/bin/etcdctl snapshot save /data/etcd1-backup-dir/etcdsnapshot-${DATE}.db
执行脚本
root@etcd1:~/scripts# bash etcd-backup.sh
{"level":"info","ts":1592132036.4022355,"caller":"snapshot/v3_snapshot.go:110","msg":"created temporary db file","path":"/data/etcd-backup-dir/etcdsnapshot-2020-06-14_18-53-56.db.part"}
{"level":"warn","ts":"2020-06-14T18:53:56.402+0800","caller":"clientv3/retry_interceptor.go:116","msg":"retry stream intercept"}
{"level":"info","ts":1592132036.4027808,"caller":"snapshot/v3_snapshot.go:121","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":1592132036.4196029,"caller":"snapshot/v3_snapshot.go:134","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","took":0.017307145}
{"level":"info","ts":1592132036.4196665,"caller":"snapshot/v3_snapshot.go:143","msg":"saved","path":"/data/etcd-backup-dir/etcdsnapshot-2020-06-14_18-53-56.db"}
Snapshot saved at /data/etcd-backup-dir/etcdsnapshot-2020-06-14_18-53-56.db
root@etcd1:~/scripts# ll /data/etcd1-backup-dir/etcdsnapshot-2020-06-14_18-53-56.db
-rw------- 1 root root 1925152 Jun 14 18:53 /data/etcd1-backup-dir/etcdsnapshot-2020-06-14_18-53-56.db
etcd v2版本数据备份与恢复
V2版本备份数据
root@etcd1:~# ETCDCTL_API=2 etcdctl backup --data-dir /var/lib/etcd/ --backup-dir /opt/etcd_backup
root@etcd1:~# cd /opt/etcd_backup/member/
root@etcd1:/opt/etcd_backup/member# ls
snap wal
V2版本恢复数据
root@etcd1:~# etcd --data-dir=/var/lib/etcd/default.etcd --force-new-cluster
或
root@k8s-etcd2:~# vim /etc/systemd/system/etcd.service
root@etcd1:~# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/bin/etcd \
--name=etcd1 \
........
--data-dir=opt/etcd_backup -force-new-cluster #强制设置为新集群
Restart=always
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target