基于Tensorflow框架的BP神经网络回归小案例--股票预测
(案例):利用BP实现股票大盘指数的预测,以大盘所包含的500支股票每分钟的收盘价作为样本,预测大盘收盘价,并数据可视化,观测预测值和真实值的规律
导包
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib as mpl
解决中文显示问题
mpl.rcParams[‘font.sans-serif’] = [u’SimHei’]
mpl.rcParams[‘axes.unicode_minus’]
设置程序是预测还是训练
FLAGS=tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer(‘is_train’,2,‘指定程序是预测还是训练’)
读取数据:样本数为41266(分钟数),特征数为500(股票数),1个大盘指数标签
data = pd.read_csv(’./data_stocks_predict/data_stocks.csv’).astype(‘float32’)
sample_tatal_num = data.shape[0] # n=41266 每分钟股票的数据
n= data.shape[1] #500支股票的close+大盘指数1列,+日期1列
划分数据集:选取80%的数据进行训练 20%的进行测试
train_start = 0
train_end = int(np.floor(0.8*sample_tatal_num)) #np.floor向下取整
获取分割索引
test_start = train_end + 1
test_end = sample_tatal_num
分割训练集和测试集
data_train = data.iloc[np.arange(train_start, train_end), :]
data_test = data.iloc[np.arange(test_start, test_end), :]
数据标准化
scaler = MinMaxScaler()
scaler.fit(data_train) #计算
scaler.transform(data_train) #转化
scaler.transform(data_test) #转化
训练集和测试集:
获取所有行,第一列是时间,第二列是大盘指数,所以从第三列往后是每支股票的收价
x_train = data_train.iloc[:, 2:]
y_train = data_train.iloc[:, 1]
x_test = data_test.iloc[:, 2:]
y_test = data_test.iloc[:, 1]
参数设置
n_stocks = 500 #500支股票,就是500个输入特征
n_neurons_1 = 1024 #第一层隐藏层神经元个数
n_neurons_2 = 512 #第二层隐藏层神经元个数
n_neurons_3 = 256 #第三层隐藏层神经元个数
n_neurons_4 = 128 #第四层隐藏层神经元个数
n_target = 1 #输出层神经元个数
预输入X,预输出值Y
X = tf.placeholder(tf.float32, [None, n_stocks]) #未知样本500个特征
Y = tf.placeholder(tf.float32, [None]) #未知输出个数
初始化权重:
weight_initializer = tf.variance_scaling_initializer()
bias_initializer = tf.zeros_initializer()
第一层隐藏层
W1 = tf.Variable(weight_initializer([n_stocks, n_neurons_1]))
b1 = tf.Variable(bias_initializer([n_neurons_1]))
第二层隐藏层
W2 = tf.Variable(weight_initializer([n_neurons_1, n_neurons_2]))
b2 = tf.Variable(bias_initializer([n_neurons_2]))
第三层隐藏层
W3 = tf.Variable(weight_initializer([n_neurons_2, n_neurons_3]))
b3 = tf.Variable(bias_initializer([n_neurons_3]))
第四层隐藏层
W4 = tf.Variable(weight_initializer([n_neurons_3, n_neurons_4]))
b4 = tf.Variable(bias_initializer([n_neurons_4]))
输出层
W_out = tf.Variable(weight_initializer([n_neurons_4, n_target]))
b_out = tf.Variable(bias_initializer([n_target]))
对隐藏层,进行非线性的转换 激活
h1 = tf.nn.relu(tf.add(tf.matmul(X, W1), b1))
h2 = tf.nn.relu(tf.add(tf.matmul(h1, W2), b2))
h3 = tf.nn.relu(tf.add(tf.matmul(h2, W3), b3))
h4 = tf.nn.relu(tf.add(tf.matmul(h3, W4), b4))
最终的输出
out = tf.transpose(tf.add(tf.matmul(h4, W_out), b_out))
定义损失函数:均方误差
loss=tf.reduce_mean(tf.squared_difference(out, Y))
#优化损失
opt=tf.train.AdamOptimizer().minimize(loss)
#初始化变量
init = tf.global_variables_initializer()
#收集数据
#单个数字收集
tf.summary.scalar(‘losses’,loss)
#高位数据收集
tf.summary.histogram(‘weights’,W1)
tf.summary.histogram(‘weights’,W2)
tf.summary.histogram(‘weights’,W3)
tf.summary.histogram(‘weights’,W4)
tf.summary.histogram(‘weights’,W_out)
tf.summary.histogram(‘biases’,b1)
tf.summary.histogram(‘biases’,b2)
tf.summary.histogram(‘biases’,b3)
tf.summary.histogram(‘biases’,b4)
tf.summary.histogram(‘biases’,b_out)
定义一个合并数据的op
merged = tf.summary.merge_all()
#创建saver保存模型
saver=tf.train.Saver()
#开启会话
with tf.Session() as sess:
sess.run(init)
** 创建events文件,写入文件(创建文件)**
filewriter = tf.summary.FileWriter(’./data_stock_train’)
epochs = 50 #训练轮数
batch_size = 256 #每批次训练数目
num= 1
is_train==1表示进行训练模型
if FLAGS.is_train == 1:
for e in range(epochs): #控制轮数
# 得到一个乱了顺序的range对象
shuffle_indices = np.random.permutation(np.arange(len(y_train)))
x_train = x_train.iloc[shuffle_indices]
y_train = y_train.iloc[shuffle_indices]
for i in range(0, len(y_train) // batch_size): #训练集训练一遍需要次数
start = i * batch_size #索引
batch_x = x_train.iloc[start:start + batch_size] #每批次训练特征
batch_y = y_train.iloc[start:start + batch_size] #每批次目标标签
#训练模型,优化损失:#避免重名引起数据类型输送错误,最好使用不同的命名
_,ms = sess.run([opt,loss], feed_dict={X: batch_x, Y: batch_y})
# 写入每批次训练的值
summary = sess.run(merged, feed_dict={X: batch_x, Y: batch_y})
filewriter.add_summary(summary, i)
print(‘第%s轮第%s批次训练的损失为:%s’%(e+1,i+1,ms))
# 保存模型
saver.save(sess, ‘./data_stock_train/data_model’)
预测数据:
else:
加载模型
saver.restore(sess, ‘./data_stock_train/data_model’)
# 利用循环测试测试集
predicts= sess.run(out, feed_dict={X: x_test}) #二维数据
num=0
#把二维数据遍历成一维数组
for predict in predicts:
#利用zip同时遍历预测值和真实值
for pre,y_true in zip(predict,y_test):
print(‘第%s次测试的预测值为:%s,真实值为:%s’ % (num+1,pre, y_true))
num += 1 #便于计数
数据可视化,画图对比预测值和真实值
t=np.arange(len(y_test))
plt.plot(t,list(predict),c=‘r’,linewidth=2,label=‘预测大盘指数’)
plt.plot(t,list(y_test),c=‘g’,linewidth=2,label=‘真实大盘指数’)
plt.legend(loc=‘upper right’)
plt.show()
结果:
第8249次测试的预测值为:2432.245,真实值为:2472.219970703125
第8250次测试的预测值为:2432.6633,真实值为:2471.77001953125
第8251次测试的预测值为:2432.2756,真实值为:2470.030029296875
第8252次测试的预测值为:2430.9697,真实值为:2471.489990234375
第8253次测试的预测值为:2432.3396,真实值为:2471.489990234375
可视化展示:
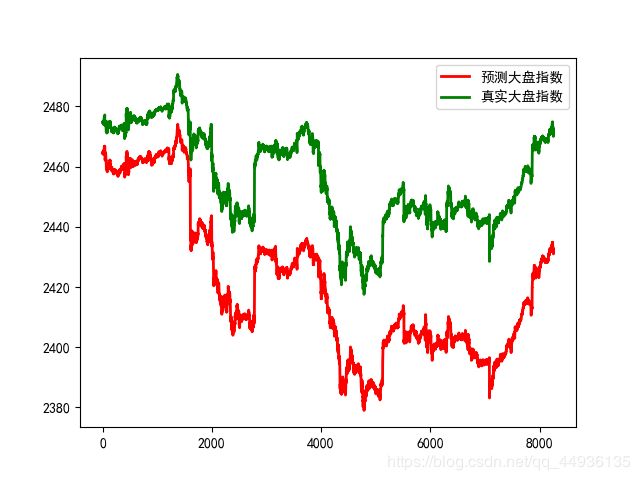 从预测的结果可以看到预测的大盘指数始终小于真实值,误差最大在50左右,这是基于已知的数据预测当时大盘指数,误差还是很大,但是趋势基本保持一致,效果还可以,后面会专门用递归神经网络Lstm模型用已知数据预测股票未来趋势,可能会更有趣,感兴趣的朋友可以联系我,把数据发给你。
从预测的结果可以看到预测的大盘指数始终小于真实值,误差最大在50左右,这是基于已知的数据预测当时大盘指数,误差还是很大,但是趋势基本保持一致,效果还可以,后面会专门用递归神经网络Lstm模型用已知数据预测股票未来趋势,可能会更有趣,感兴趣的朋友可以联系我,把数据发给你。