HDFS其实很简单,分分钟学会
HDFS
(一)HDFS的命令行操作
1. HDFS操作命令(HDFS操作命令帮助信息:hdfs dfs)
| 命令 | 说明 | 示例 |
|---|---|---|
| -mkdir | 在HDFS上创建目录 | 在HDFS上创建目录/data: hdfs dfs -mkdir /data 在HDFS上级联创建目录/data/input: hdfs dfs -mkdir -p /data/input |
| -ls | 列出hdfs文件系统根目录下的目录和文件 | 查看HDFS根目录下的文件和目录: hdfs dfs -ls / 查看HDFS的/data目录下文件和目录: hdfs dfs -ls /data |
| -ls -R | 列出hdfs文件系统所有的目录和文件 | 查看HDFS根目录及其子目录下的文件和目录: hdfs dfs -ls -R / |
| -put | 上传文件或者从键盘输入字符到HDFS | 将本地Linux的文件data.txt上传到HDFS: hdfs dfs -put data.txt /data/input 从键盘输入字符保存到HDFS的文件: hdfs dfs -put - /aaa.txt (按Ctrl+c结束输入) |
| -moveFromLocal | 与put相类似,命令执行后源文件将从本地被移除 | hdfs dfs -moveFromLocal data.txt /data/input |
| -copyFromLocal | 与put相类似 | hdfs dfs -copyFromLocal data.txt /data/input |
| -get | 将HDFS中的文件复制到本地 | hdfs dfs -get /data/input/data.txt /root/ |
| -rm | 每次可以删除多个文件或目录 | 删除多个文件: hdfs dfs -rm /data1.txt /data2.txt 删除多个目录: hdfs dfs -rm -r /data /input |
| -getmerge | 将hdfs指定目录下所有文件排序后合并到local指定的文件中,文件不存在时会自动创建,文件存在时会覆盖里面的内容 | 将HDFS上/data/input目录下的所有文件合并到本地的a.txt文件中: hdfs dfs -getmerge /data/input /root/a.txt |
| -cp | 在HDFS上拷贝文件 | |
| -mv | 在HDFS上移动文件 | |
| -count | 统计hdfs对应路径下的目录个数,文件个数,文件总计大小 显示为目录个数,文件个数,文件总计大小,输入路径 |
hdfs dfs -count /data |
| -du | 显示hdfs对应路径下每个文件和文件大小 | hdfs dfs -du / |
| -text、-cat | 相当于Linux的cat命令 | hdfs dfs -cat /input/1.txt |
| balancer | 如果管理员发现某些DataNode保存数据过多,某些DataNode保存数据相对较少,可以使用上述命令手动启动内部的均衡过程 | hdfs balancer |
2. HDFS管理命令(HDFS管理命令帮助信息:hdfs dfsadmin)
| 命令 | 说明 | 示例 |
|---|---|---|
| -report | 显示HDFS的总容量,剩余容量,datanode的相关信息 | hdfs dfsadmin -report |
| -safemode | HDFS的安全模式命令 enter, leave, get, wait | hdfs dfsadmin -safemode enter hdfs dfsadmin -safemode leave hdfs dfsadmin -safemode get hdfs dfsadmin -safemode wait |
(二)HDFS的JavaAPI
所需pom依赖如下:
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.3version>
dependency>
dependencies>
通过HDFS提供的JavaAPI,我们可以完成以下的功能:
-
在HDFS上创建目录
@Test public void testMkDir() throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.137.25:9000"); FileSystem fs = FileSystem.get(conf); // 创建目录 boolean flag = fs.mkdirs(new Path("/inputdata")); System.out.println(flag); } -
通过FileSystemAPI读取数据(下载文件)
@Test publci void testDownload() throws Exception { // 构造一个输入流 <-------HDFS FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.88:9000"), new Configuration()); InputStream in = fs.open(new Path("/inputdata/a.war")); // 构造一个输出流 OutputStream out = new FileOutputStream("d:\\a.war"); IOUtils.copy(in, out); } -
写入数据(上传文件)
@Test public void testUpload() throws Exception { // 指定上传的文件(输入流) InputStream in = new FileInputStream("d:\\test.war"); // 构造输出流 ----> HDFS FileSystem fs = FileSystem.get(new URI("hdfs://192.168.31.88:9000"), new Configuration()); // 工具类 ---> 直接实现上传和下载 IOUtils.copy(in, out); } -
查看目录及文件信息
@Test public void checkFileInformation() throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.31.88:9000"); FileSystem fs = FileSystem.get(conf); FileStatus[] status = fs.listStatus(new Path("/hbase")); for (FileStatus f : status) { String dir = f.isDirectory() ? "目录" : "文件"; String name = f.getPath().getName(); String path = f.getPath().toString(); System.out.println(dir + "------" + name + ",path:" + path); System.out.println(f.getAccessTime()); System.out.println(f.getBlockSize()); System.out.println(f.getGroup()); System.out.println(f.getLen()); System.out.println(f.getModificationTime()); System.out.println(f.getOwner()); System.out.println(f.getPermission()); System.out.println(f.getReplication()); } } -
查找某个文件在HDFS集群的位置
@Test public void findFileBlockLocation() throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.31.88:9000"); FileSystem fs = FileSystem.get(conf); FileStatus fStatus = fs.getFileStatus(new Path("/data/mydata.txt")); BlockLocation[] blocks = fs.getFileBlockLocations(fStatus, 0, fStatus.getLen()); for (BlockLocation block : blocks) { System.out.println(Arrays.toString(block.getHosts()) + "\t" + Arrays.toString(block.getNames())); } } -
删除数据
@Test public void deleteFile() throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.31.88:9000"); FileSytem fs = FileSystem.get(conf); // 第二个参数表示是否递归 boolean flag = fs.delete(new Path("/mydir/test.txt", false)); System.out.println(flag ? "删除成功" : "删除失败"); } -
获取HDFS集群上所有数据节点的信息
@Test public void testDataNode() throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.31.88:9000"); DistributedFileSystem fs = (DistributedFileSystem) FileSystem.get(conf); DatanodeInfo[] dataNodeStats = fs.getDataNodeStats(); for (DatanodeInfo dataNode : dataNodeStats) { System.out.println(dataNode.getHostName() + "\t" + dataNode.getName()); } }
(三)HDFS的WebConsole
(四)HDFS的回收站
-
默认回收站是关闭的,可以通过在core-site.xml中添加fs.trash.interval来打开配置时间阀值,例如:
<property> <name>fs.trash.intervalname> <value>1440value> property> -
删除文件时,其实是放入回收站/user/root/.Trash/Current
-
回收站里的文件可以快速恢复
-
可以设置一个时间阀值,当回收站里文件的存放时间超过这个阀值,就被彻底删除,并且释放占用的数据块
-
查看回收站:
hdfs dfs -ls /user/root/.Trash/Current -
从回收站中恢复
hdfs dfs -cp /user/root/.Trash/Current/data.txt /input
(五)HDFS的快照
- 一个snapshot(快照)是一个全部文件系统、或者某个目录在某一时刻的镜像
- 快照应用在如下场景中:
- 防止用户的错误操作
- 备份
- 试验/测试
- 灾难恢复
- HDFS的快照操作
- 开启快照
hdfs dfsadmin -allowSnapshot /input- 创建快照
hdfs dfs -createSnapshot /input backup_input_01- 查看快照
hdfs lsSnapshottableDir- 对比快照
hdfs snapshotDiff /input backup_input_01 backup_input_02- 恢复快照
hdfs dfs -cp /input/.snapshot/backup_input_01/data.txt /input
(六)HDFS的用户权限管理
-
启动namenode服务的用户就是超级用户,该用户的组是supergroup

-
shell 命令
命令 说明 chmod[-R] mode file… 只有文件的所有者或者超级用户才有权限改变文件模式 chgrp[-R] group file … 使用chgrp命令的用户必须属于特定的组且是文件的所有者,或者用户是超级用户 chown[-R][owner]:[group] file 文件的所有者只能被超级用户修改
(七)HDFS的配额管理
什么是配额?
配额就是HDFS为每个目录分配的大小空间,新建立的目录是没有配额的,最大的配额是Long.MAX_VALUE。配额为1可以强制目录保持为空。
配额的类型?
- 名称配额:用于设置该目录中能够存放的最多文件(目录)个数。
- 空间配额:用于设置该目录中最大能够存放的文件大小。
配额的应用案例
-
设置/input目录的名称配额为3:
hdfs dfsadmin -setQuota 3 /input -
清除/input目录的名称配额:
hdfs dfsadmin -clrQuota /input -
设置/input目录的空间配额为1M:
hdfs dfsadmin -setSpaceQuota 1048576 /input -
清除input目录的空间配额:
hdfs dfsadmin -clrSpaceQuota /input
注意:如果hdfs文件系统中文件个数或者大小超过了限制配额,会出现错误。
(八)HDFS的安全模式
-
什么是安全模式?
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。如果HDFS处于安全模式,则表示HDFS是只读状态。
-
当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是5,那么在datanode上就应该有5个副本存在,假设只存在3个副本,那么比例就是3/5=0.6。在配置文件hdfs-default.xml中定义了一个最小的副本的副本率0.999。
我们的副本率0.6明显小于0.99,因此系统会自动的复制副本到其他的dataNode,使得副本率不小于0.999.如果系统中有8个副本,超过我们设定的5个副本,那么系统也会删除多余的3个副本。
-
虽然不能进行修改文件的操作,但是可以浏览目录结构、查看文件内容。
-
在命令行下是可以控制安全模式的进入、退出和查看的:
- 查看安全模式状态:
hdfs dfsadmin -safemode get - 进入安全模式状态:
hdfs dfsadmin -safemode enter - 离开安全模式状态:
hdfs dfsadmin -safemode leave
- 查看安全模式状态:
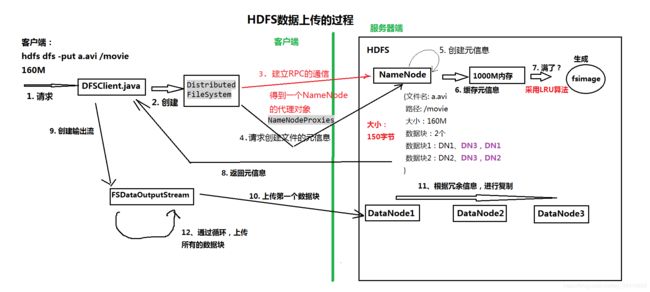
HDFS上传与下载原理
(一)HDFS上传原理
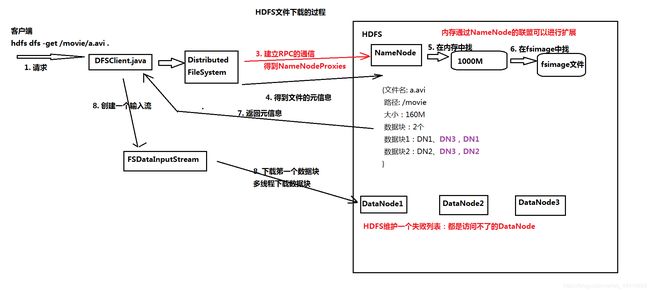
(二)HDFS下载原理
HDFS的底层原理
HDFS的底层通信原理采用的是:RPC和动态代理对象Proxy
(一)RPC
什么是RPC?
Remote Procedure Call,远程过程调用。也就是说,调用过程代码并不是在调用者本地运行,而是要实现调用者与被调用者二地之间的连接与通信。
RPC的基本通信模型是基于Client/Server进程间相互通信模型的一种同步通信形式;它对Client提供了远程服务的过程抽象,其底层消息传递操作对Client是透明的。
在RPC中,Client即是请求服务的调用者(Caller),而Server则是执行Client的请求而被调用的程序 (Callee)。
RPC示例
-
服务器端
package rpc.server; import org.apache.hadoop.ipc.VersionedProtocol; public interface MyInterface extends VersionedProtocol { //定义一个版本号 public static long versionID=1; //定义客户端可以调用的方法 public String sayHello(String name); }package rpc.server; import java.io.IOException; import org.apache.hadoop.ipc.ProtocolSignature; public class MyInterfaceImpl implements MyInterface { @Override public ProtocolSignature getProtocolSignature(String arg0, long arg1, int arg2) throws IOException { // 指定签名(版本号) return new ProtocolSignature(MyInterface.versionID, null); } @Override public long getProtocolVersion(String arg0, long arg1) throws IOException { // 返回的该实现类的版本号 return MyInterface.versionID; } @Override public String sayHello(String name) { System.out.println("********* 调用到了Server端*********"); return "Hello " + name; } }package rpc.server; import java.io.IOException; import org.apache.hadoop.HadoopIllegalArgumentException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; import org.apache.hadoop.ipc.RPC.Server; public class RPCServer { public static void main(String[] args) throws Exception { //定义一个RPC Builder RPC.Builder builder = new RPC.Builder(new Configuration()); //指定RPC Server的参数 builder.setBindAddress("localhost"); builder.setPort(7788); //将自己的程序部署到Server上 builder.setProtocol(MyInterface.class); builder.setInstance(new MyInterfaceImpl()); //创建Server Server server = builder.build(); //启动 server.start(); } } -
客户端
package rpc.client; import java.io.IOException; import java.net.InetSocketAddress; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; import rpc.server.MyInterface; public class RPCClient { public static void main(String[] args) throws Exception { //得到的是服务器端的一个代理对象 MyInterface proxy = RPC.getProxy(MyInterface.class, //调用服务器端的接口 MyInterface.versionID, // 版本号 new InetSocketAddress("localhost", 7788), //指定RPC Server的地址 new Configuration()); String result = proxy.sayHello("Tom"); System.out.println("结果是:"+ result); } }
(二)Java动态代理对象
-
为其他对象提供一种代理以控制这个对象的访问。
-
核心是使用JDK的Proxy类
package proxy; public interface MyBusiness { public void method1(); public void method2(); }package proxy; public class MyBusinessImpl implements MyBusiness { @Override public void method1() { System.out.println("method1"); } @Override public void method2() { System.out.println("method2"); } }package proxy; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; import java.lang.reflect.Proxy; public class ProxyTestMain { public static void main(String[] args) { //创建真正的对象 MyBusiness obj = new MyBusinessImpl(); //重写method1的实现 ---> 不修改源码 //生成真正对象的代理对象 /* Proxy.newProxyInstance(loader, 类加载器 interfaces, 真正对象实现的接口 h ) InvocationHandler 表示客户端如何调用代理对象 */ MyBusiness proxyObj = (MyBusiness) Proxy.newProxyInstance(ProxyTestMain.class.getClassLoader(), obj.getClass().getInterfaces(), new InvocationHandler() { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 客户端的一次调用 /* * method: 客户端调用方法名 * args : 方法的参数 */ if(method.getName().equals("method1")){ //重写 System.out.println("******重写了method1*********"); return null; }else{ //不感兴趣的方法 直接调用真正的对象完成 return method.invoke(obj, args); } } }); //通过代理对象调用 method1 method2 proxyObj.method1(); proxyObj.method2(); } }