爬虫教程(爬取斗图网)---详解
理清思路
- 前言
- 我们先来看一下要爬取网页的内容
- 开始写代码
- 1.调入模块
- 2.分析每个表情包的地址
- 3.分析表情包中每张图片的地址
- 源代码
- 结语
前言
爬取之前我们先梳理一下思路,不然想到哪写到哪的话会导致我们的代码不完整,轻则体验效果不好,重则无法达到我们的目的,所以先做一步规划是很重要滴。
我们先来看一下要爬取网页的内容
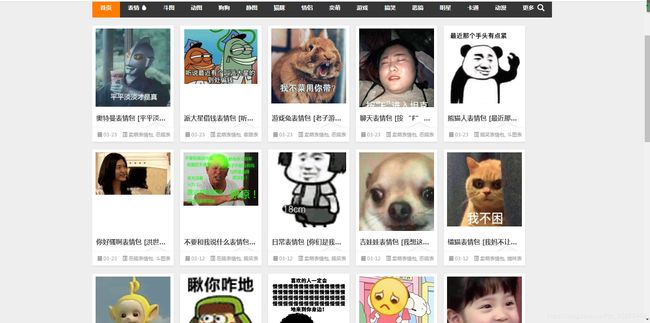
我们可以看到网页中有很多的表情包,我们要爬取每个表情包的话就要获得每个表情包的地址。
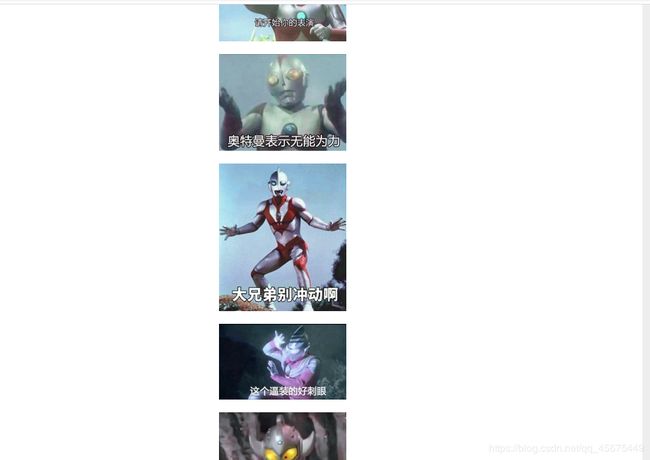
进入表情包以后我们要爬取表情包中的所有图片,所以我们要获取每张图片的地址。
我们要爬取所有表情包,就要从第一个开始,进入第一个表情包然后爬取所有图片,再进入第二个表情包然后爬取所有图片······以此往后直到爬取完所有表情包,那怎么实现呢?用最基础的循环即可。
所以大体思路我们整理了一下,可以简单的概括为:
分析每个表情包的地址 找到有关规律
分析每个表情包中每张图片的地址 找到有关规律
循环每一类表情包,在循环中嵌套循环每一张图片 即可实现自动爬取每一类表情包中的每一张图片
开始写代码
1.调入模块
此次学习主要涉及到的主要有网页源代码的获取,用正则表达式来表示我们要查找的地址,以及在源代码中查找要获得的地址,有关模块:
import requests
import re
from bs4 import BeautifulSoup
import os
2.分析每个表情包的地址
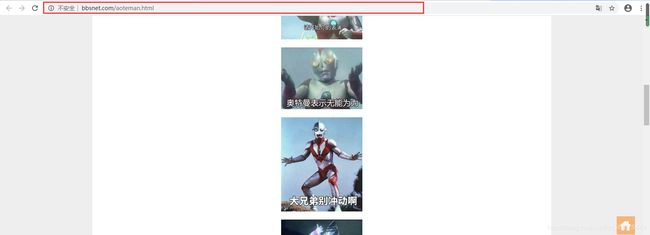
进入不同表情包依次查看网页地址,如下:
分析每一类表情包URL
http://www.bbsnet.com/aoteman.html
http://www.bbsnet.com/jieqian.html
http://www.bbsnet.com/youxitu.html
在首页中我们"检查"看一下

此时每个a标签的href就是进入每个不同表情包的地址,所以我们可以获取到每个a标签,然后再获得a标签中href属性的属性值。
# 主网页地址
main_html_url = "http://www.bbsnet.com/"
main_html = requests.get(main_html_url).text
# 获取相关类名的a标签(进入不同类表情包的链接)
# 转化地址
soup = BeautifulSoup(main_html,"html.parser")
# 查找相关标签
a = soup.find_all("a",attrs={"class":"zoom"}) # 此时a为一个列表
for i in range(len(a)): #循环每一类表情包
html_url = a[i]["href"] #获取每个a标签的href属性 为 每一类表情包的地址
3.分析表情包中每张图片的地址
进入一个表情包,F12检查一下
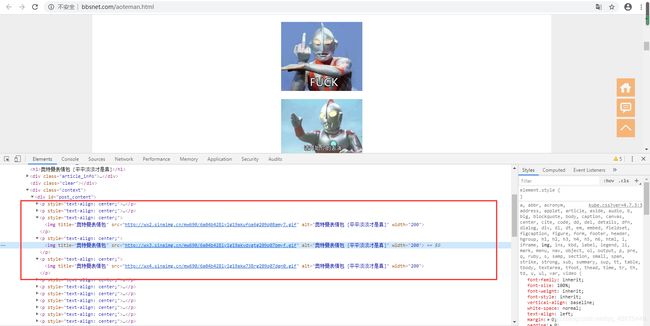
得到地址如下:
http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al0qbjag209q09q0u7.gif
http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al1bzn2g209q05bjso.gif
http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al2bxhkg208509qtaj.gif
这是一个表情包中的,我们再来看一个表情包

得到地址如下:
http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crllm55jg208c069glz.gif
http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crllx8kzg206u06tdg2.gif
http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crlniudwg206u06t3z2.gif
由此我们看出每一类表情包中的每一张图片地址前面一部分都是相同的,只有后面不同,那我们可以用正则表达式来表示所有表情包中所有图片地址的不同部分:
r'6a04b428.*?\.gif'
这段代码表示的是一类字符串,即所有符合这个格式的字符串(以6a04b···开头,以.gif结尾的字符串),我们可以用这段代码查找所有符合的字符串,得到的结果就是每张图片地址后面不同的部分,也就能获得每张图片的完整地址。
前面讲的主要还是一些思路和相对难理解的一些点,只读的话会比较抽象,所以附上源码,结合来看就很好理解了,基本都有注释,完整看一遍大体也就都明白了。
源代码
# 调入相关模块
import requests
import re
from bs4 import BeautifulSoup
import os
# 分析每一类表情包URL
# http://www.bbsnet.com/aoteman.html
# http://www.bbsnet.com/jieqian.html
# http://www.bbsnet.com/youxitu.html
# 每类表情包都根据一个标题命名地址(地址也就是标题部分不同,其余部分相同)
# 主网页地址
main_html_url = "http://www.bbsnet.com/"
main_html = requests.get(main_html_url).text
# 获取相关类名的a标签(进入不同类表情包的链接)
# 转化地址
soup = BeautifulSoup(main_html,"html.parser")
# 查找相关标签
a = soup.find_all("a",attrs={"class":"zoom"}) # 此时a为一个列表
# 分析每张图片的地址
# http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al0qbjag209q09q0u7.gif
# http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al1bzn2g209q05bjso.gif
# http://wx4.sinaimg.cn/mw690/6a04b428ly1g19al2bxhkg208509qtaj.gif
# http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crllm55jg208c069glz.gif
# http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crllx8kzg206u06tdg2.gif
# http://wx4.sinaimg.cn/mw690/6a04b428gy1g1crlniudwg206u06t3z2.gif
#不同类表情包的图片地址都相似 可以使用re库进行表示
z = 1
for i in range(len(a)): #循环每一类表情包
x = 0
html_url = a[i]["href"] #获取每个a标签的href属性 为 每一类表情包的地址
html_title = a[i]["title"].split("[")[0] #获取每个a标签的title标签 作为存取文件的文件名
img_html = requests.get(html_url).text #获取单独一类表情包的源代码
old_img_url = re.findall(r'6a04b428.*?\.gif',img_html) #查找每张图片其后面地址的不同部分 此时old_img_url 为一个列表
img_url = old_img_url[0:-6] # 网页下边有多余的几张图片 我们只选取符合标题的部分
local_name = ("F:/表情包/" + html_title) + "/" #本地存取地址及文件夹名
print(old_img_url)
print(img_url)
for person_name in img_url: #循环爬取每一张图片
x += 1
name = html_title + str(x) + ".jpg" # 保存的图片名
try:
if not os.path.exists(local_name):
os.mkdir(local_name) #不会自动创建多个文件夹只会创建给定目录最后一个文件夹 所以要确保除给定目录最后一个文件夹外其余文件夹都要存在
else:
print("文件夹已存在")
if not os.path.exists(local_name + name):
information_url = requests.get("http://wx4.sinaimg.cn/mw690/" + person_name).content #获取源代码并转换为二进制数据(第一次是获取源代码为text数据)
with open(local_name+name,"wb") as f: #存储 规范命名和文件格式
f.write(information_url) #写入相关地址的文件 文件的命名和文件的格式 由你自己规范
print("爬取成功第" + str(z) + "组第" + str(x) + "张")
else:
print("文件已存在")
except:
print("爬取失败")
z += 1
结语
其实我也是个小白,接触没多长时间,有很多不懂的地方,写这个东西也用了挺长时间,但我还是希望能帮助到有需要的人。代码肯定有很多不足之处,也请大佬们帮忙指点一下,也使我更快的进步。