【项目实战】数据挖掘 + 数据清洗 + 数据可视化
自己亲手全手打了一套系统的代码,帮助朋友完成设计,做了贵阳市几个区的房屋价格爬取以及数据清洗和可视化操作,代码细细道来:
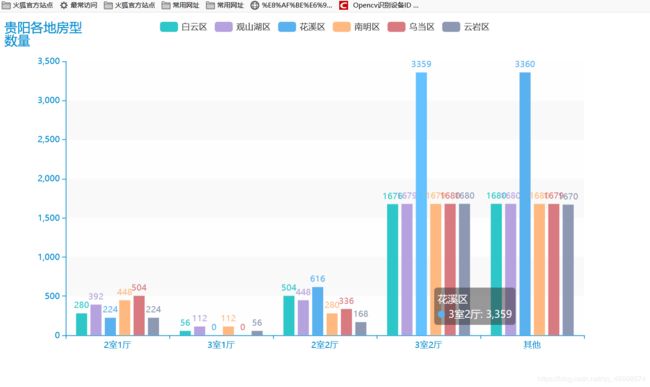
上图镇楼,接下来细说。
一:数据挖掘
我选用了链家网做数据爬取场所(不得不唠叨一句,这个网站真是为了爬虫而生的,对爬虫特别友好哈哈哈,反扒措施比较少)
比如我们爬取贵阳市乌当区的所有房子的房价及其他信息:
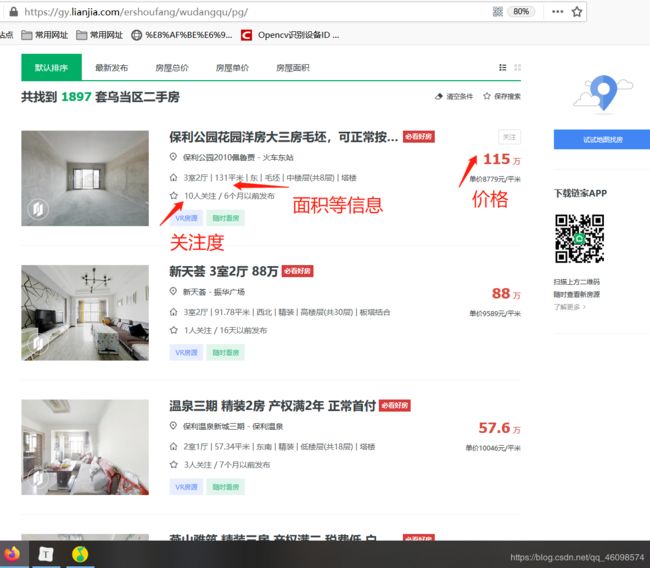
比如我们爬取第一个房子的价格:115万:
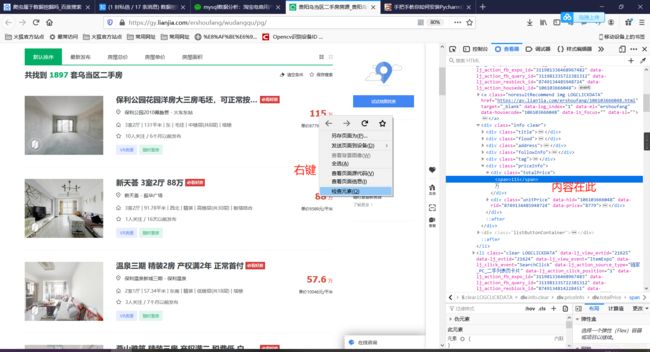
接下来我们可以使用复制CSS选择器或者XPath等等来实现获取:
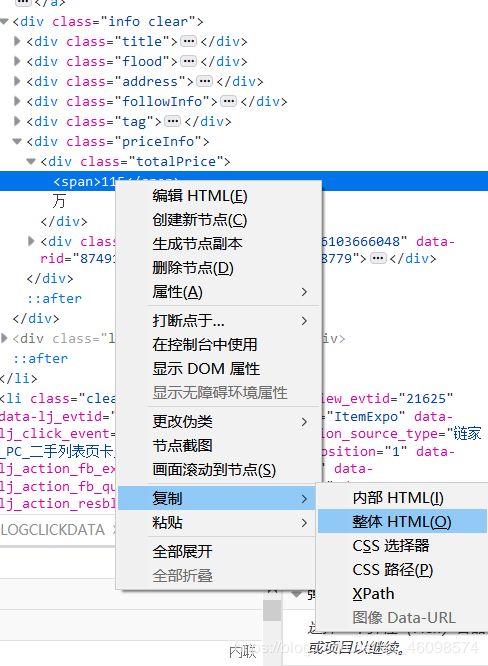
下面我们使用复制XPath的方式,修改路径即可(需要一定前端知识):
分别实现详解:
1:导入必备库
import requests
from lxml import etree
import xlwt
from xlutils.copy import copy
import xlrd
import csv
import pandas as pd
import time
细说一下:
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库,爬虫必备技能之一。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner。更重要的一点是它支持 Python3 哦!
Pandas是python第三方库,提供高性能易用数据类型和分析工具 , pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
2:定义爬取URL地址和设置请求头(其实还可以更完善,不过链家网比较友善,这点够用了)
self.url = 'https://gy.lianjia.com/ershoufang/wudangqu/pg{}/'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
url是要获取信息的地址:我们选用贵阳市(gy)乌当区(wudangqu)为目标,然后pg{}是页码的意思:pg100就是爬第一百页,这里我们使用{}做一下占位,方便后续从第一页迭代到最后。
headers是我们的请求头,就是模拟人正常登录的意思,而不是通过python,让网页知道你是爬虫,知道了就有可能封掉你的IP等。 通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。这两种类型的消息由一个起始行,一个或者多个头域,一个只是头域结束的空行和可 选的消息体组成。HTTP的头域包括通用头,请求头,响应头和实体头四个部分。每个头域由一个域名,冒号(:)和域值三部分组成。域名是大小写无关的,域 值前可以添加任何数量的空格符,头域可以被扩展为多行,在每行开始处,使用至少一个空格或制表符。 User-Agent头域的内容包含发出请求的用户信息。
3:使用Requests获取数据
def get_response_spider(self, url_str): # 发送请求
get_response = requests.get(self.url, headers=self.headers)
time.sleep(4)
response = get_response.content.decode()
html = etree.HTML(response)
return html
4:使用Xpath筛选数据源,过程见上图,需要一定的前端知识,不过,也有一些技巧:
def get_content_html(self, html): # 使xpath获取数据
self.houseInfo = html.xpath('//div[@class="houseInfo"]/text()')
self.title = html.xpath('//div[@class="title"]/a/text()')
self.positionInfo = html.xpath('//div[@class="positionInfo"]/a/text()')
self.totalPrice = html.xpath('//div[@class="totalPrice"]/span/text()')
self.unitPrice = html.xpath('//div[@class="unitPrice"]/span/text()')
self.followInfo = html.xpath('//div[@class="followInfo"]/text()')
self.tag = html.xpath('//div[@class="tag"]/span/text()')
5:使用生成器,通过for循环和yield生成器迭代生成数据项:
def xpath_title(self):
for i in range(len(self.title)):
yield self.title[i]
def xpath_positionInfo(self):
for i in range(len(self.positionInfo)):
yield self.positionInfo[i]
def xpath_totalPrice(self):
for i in range(len(self.totalPrice)):
yield self.totalPrice[i]
def xpath_unitPrice(self):
for i in range(len(self.unitPrice)):
yield self.unitPrice[i]
def xpath_followInfo(self):
for i in range(len(self.followInfo)):
yield self.followInfo[i]
def xpath_tag(self):
for i in range(len(self.tag)):
yield self.tag[i]
6:通过调用这些函数进行预获得:
self.xpath_houseInfo()
self.xpath_title()
self.xpath_positionInfo()
self.xpath_totalPrice()
self.xpath_unitPrice()
self.xpath_followInfo()
self.xpath_tag()
get_houseInfo = self.xpath_houseInfo()
get_title = self.xpath_title()
get_positionInfo=self.xpath_positionInfo()
get_totalPrice = self.xpath_totalPrice()
get_unitPrice = self.xpath_unitPrice()
get_followInfo=self.xpath_followInfo()
get_tag=self.xpath_tag()
这里的函数就是调用上面的生成器的函数:
生成器yield 理解的关键在于:下次迭代时,代码从yield的下一跳语句开始执行。
7:数据筛选,写入文本中:
while True:
data_houseInfo= next(get_houseInfo)
data_title=next(get_title)
data_positionInfo=next(get_positionInfo)
data_totalPrice=next(get_totalPrice)
data_unitPrice=next(get_unitPrice)
data_followInfo=next(get_followInfo)
data_tag=next(get_tag)
with open("lianjia1.csv", "a", newline="", encoding="utf-8-sig") as f:
fieldnames = ['houseInfo', 'title', 'positionInfo', 'totalPrice/万元', 'unitPrice', 'followInfo', 'tag']
writer = csv.DictWriter(f, fieldnames=fieldnames) # 写入表头
writer.writeheader()
list_1 = ['houseInfo', 'title', 'positionInfo', 'totalPrice/万元', 'unitPrice', 'followInfo', 'tag']
list_2 = [data_houseInfo,data_title,data_positionInfo,data_totalPrice,data_unitPrice,data_followInfo,data_tag]
list_3 = dict(zip(list_1, list_2))
writer.writerow(list_3)
print("写入第"+str(i)+"行数据")
i += 1
if i > len(self.houseInfo):
break
8:这里用过Next方法对生成器中内容不断提取:
fieldnames = ['houseInfo', 'title', 'positionInfo', 'totalPrice/万元', 'unitPrice', 'followInfo', 'tag']
writer = csv.DictWriter(f, fieldnames=fieldnames) # 写入表头
writer.writeheader()
9:将其加在表头中。然后每一行写入一次数据
10:最后构造run函数:
def run(self):
i = 1
while True:
url_str = self.url.format(i) # 构造请求url
html = self.get_response_spider(url_str)
self.get_content_html(html)
self.qingxi_data_houseInfo()
i += 1
if i == 57:
break
11:循环迭代一下,将上述的page页码从一到最后
12:main函数中启动一下,先new一下这个类,再启动run函数,就会开始爬取了
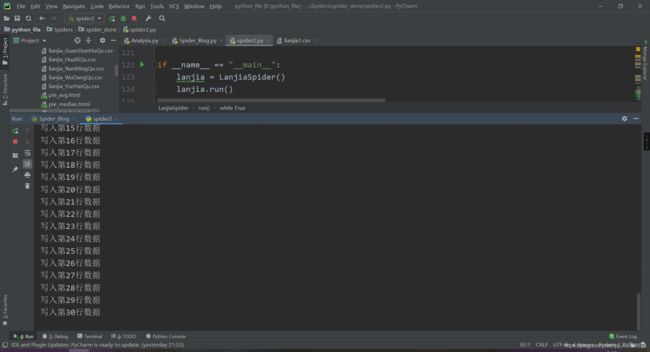
然后我们看一下结果:
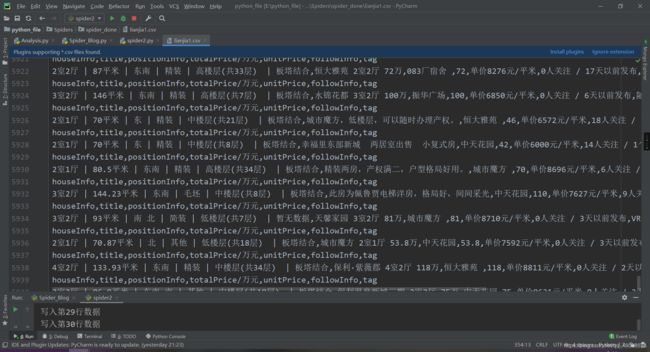
然后爬虫阶段就结束了,当然也可以写入数据库中,我们保存在文本文件中是为了更方便。我们保存在了左边的csv文件中,是不是很简单~,源码这个网上应该也有,我就暂时不放了,等朋友毕业再发。
二:数据清洗与提取
1:首先导入一下需要的库
"""
数据分析及可视化
"""
import pandas as pd
from pyecharts.charts import Line, Bar
import numpy as np
from pyecharts.globals import ThemeType
from pyecharts.charts import Pie
from pyecharts import options as opts
2:数据全局定义:
places = ['lianjia_BaiYunQu', 'lianjia_GuanShanHuQu', 'lianjia_HuaXiQu', 'lianjia_NanMingQu', 'lianjia_WuDangQu', 'lianjia_YunYanQu']
place = ['白云区', '观山湖区', '花溪区', '南明区', '乌当区', '云岩区']
avgs = [] # 房价均值
median = [] # 房价中位数
favourate_avg = [] # 房价收藏人数均值
favourate_median = [] # 房价收藏人数中位数
houseidfo = ['2室1厅', '3室1厅', '2室2厅', '3室2厅', '其他'] # 房型定义
houseidfos = ['2.1', '3.1', '2.2', '3.2']
sum_house = [0, 0, 0, 0, 0] # 各房型数量
price = [] # 房价
fav = [] # 收藏人数
type = []
area = [] # 房间面积
注释写的很清楚了,我的places是为了方便读取这几个csv中文件各自保存的数据(‘白云区’, ‘观山湖区’, ‘花溪区’, ‘南明区’, ‘乌当区’, '云岩区’区的数据):
3:文件操作,打开文件:
def avg(name):
df = pd.read_csv(str(name)+'.csv', encoding='utf-8')
pattern = '\d+'
df['totalPrice/万元'] = df['totalPrice/万元'].str.findall(pattern) # 转换成字符串,并且查找只含数字的项
df['followInfo'] = df['followInfo'].str.findall(pattern)
df['houseInfo'] = df['houseInfo'].str.findall(pattern)
使用padas的read_csv方式读取csv文件 name以传参形式迭代传入,也就是一个区一个区的传入主要是为了减少代码量,增加审美。就不必每一次都写几十行代码了
然后是一些匹配,转换成字符串,并且查找只含数字的项。
for i in range(len(df)):
if (i + 1) % 2 == 0:
continue
else:
if len(df['totalPrice/万元'][i]) == 2:
avg_work_year.append(','.join(df['totalPrice/万元'][i]).replace(',', '.'))
medians.append(float(','.join(df['totalPrice/万元'][i]).replace(',', '.')))
price.append(','.join(df['totalPrice/万元'][i]).replace(',', '.'))
if len(df['followInfo'][i]) ==2:
favourates.append(int(','.join(df['followInfo'][i][:1])))
fav.append(int(','.join(df['followInfo'][i][:1])))
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 2.1:
k +=1
sum_houses[0] =k
type.append(2.1)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 3.1:
k1 +=1
sum_houses[1] =k1
type.append(3.1)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 2.2:
k3 +=1
sum_houses[2] =k3
type.append(2.2)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 3.2:
k4 +=1
sum_houses[3] =k4
type.append(3.2)
else:
k4 +=1
sum_houses[4] = k4
type.append('other')
area.append(float(','.join(df['houseInfo'][i][2:4]).replace(',', '.')))
sum_house[0] =sum_houses[0]
sum_house[1] = sum_houses[1]
sum_house[2] = sum_houses[2]
sum_house[3] = sum_houses[3]
sum_house[4] = sum_houses[4]
favourates.sort()
favourate_median.append(int(np.median(favourates)))
medians.sort()
median.append(np.median(medians))
# price = avg_work_year
b = len(avg_work_year)
b1= len(favourates)
sum = 0
sum1 = 0
for i in avg_work_year:
sum = sum+float(i)
avgs.append(round(sum/b, 2))
for i in favourates:
sum1 = sum1+float(i)
favourate_avg.append(round(int(sum1/b1), 2))
4:这里是数据筛选的核心部分,我们细说一下:
if len(df['totalPrice/万元'][i]) == 2:
avg_work_year.append(','.join(df['totalPrice/万元'][i]).replace(',', '.'))
medians.append(float(','.join(df['totalPrice/万元'][i]).replace(',', '.')))
price.append(','.join(df['totalPrice/万元'][i]).replace(',', '.'))
5:这里是获取总价格,并且清洗好,放入前面定义好的数组中,保存好,
if len(df['followInfo'][i]) ==2:
favourates.append(int(','.join(df['followInfo'][i][:1])))
fav.append(int(','.join(df['followInfo'][i][:1])))
6:这里是获取总收藏人数,并且清洗好,放入前面定义好的数组中,保存好,
if len(df['followInfo'][i]) ==2:
favourates.append(int(','.join(df['followInfo'][i][:1])))
fav.append(int(','.join(df['followInfo'][i][:1])))
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 2.1:
k +=1
sum_houses[0] =k
type.append(2.1)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 3.1:
k1 +=1
sum_houses[1] =k1
type.append(3.1)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 2.2:
k3 +=1
sum_houses[2] =k3
type.append(2.2)
if float(','.join(df['houseInfo'][i][:2]).replace(',', '.')) == 3.2:
k4 +=1
sum_houses[3] =k4
type.append(3.2)
else:
k4 +=1
sum_houses[4] = k4
type.append('other')
area.append(float(','.join(df['houseInfo'][i][2:4]).replace(',', '.')))
7:这里是获取房型和面积,清洗好,放入数组中
favourates.sort()
favourate_median.append(int(np.median(favourates)))
medians.sort()
median.append(np.median(medians))
# price = avg_work_year
b = len(avg_work_year)
b1= len(favourates)
sum = 0
sum1 = 0
for i in avg_work_year:
sum = sum+float(i)
avgs.append(round(sum/b, 2))
for i in favourates:
sum1 = sum1+float(i)
favourate_avg.append(round(int(sum1/b1), 2))
8:这里是把上面的信息加工,生成平均数,中位数等。
另外说一下,清洗过程:
’,’.join()是为了筛选出的信息不含中括号和逗号
df[‘houseInfo’][i][2:4]是为了取出相应的数据,使用了python的切片操作
.replace(’,’, ‘.’)是把逗号改成小数点,这样就是我们想要的结果了。
下面执行看一下结果:
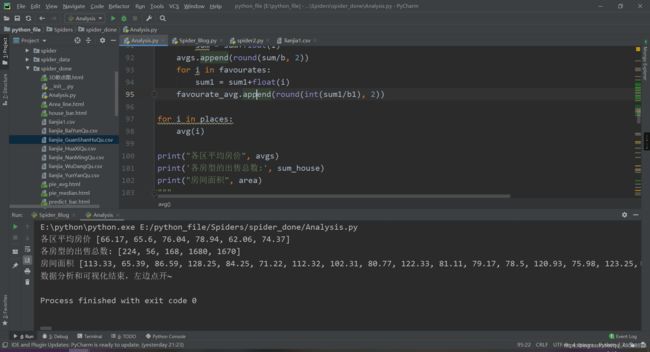
数据筛选结束~
三、数据可视化
python的数据可视化操作很完善,还很多样,我们先来看看几种常用的:
- Matplotlib:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持。在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助。也可以用作制作动画。
- Seaborn:该 Python 库能够创建富含信息量和美观的统计图形。Seaborn 基于 matplotlib,具有多种特性,比如内置主题、调色板、可以可视化单变量数据、双变量数据,线性回归数据和数据矩阵以及统计型时序数据等,能让我们创建复杂的可视化图形。
我们今天提供一个更美观,更方便的数据可视化库:Pyecahrts
1:首先绘制一下地区与房价关系折线图:
line = Line()
line.add_xaxis(place)
line.add_yaxis("贵阳各地房价平均值(万元)", avgs)
line.add_yaxis("贵阳各地房价中位数值(万元)", median)
line.render("predict_line.html")
x轴放入我们的place地区,y轴放入房价平均值和中位数值,就这几行代码,有木有很舒服。这时,执行一下,就会在当前目录生成predict_line.html,我们点开看一下
这是html网页代码,会支持在本地局域网打开我们点击一下右上角的浏览器,就可以看到:
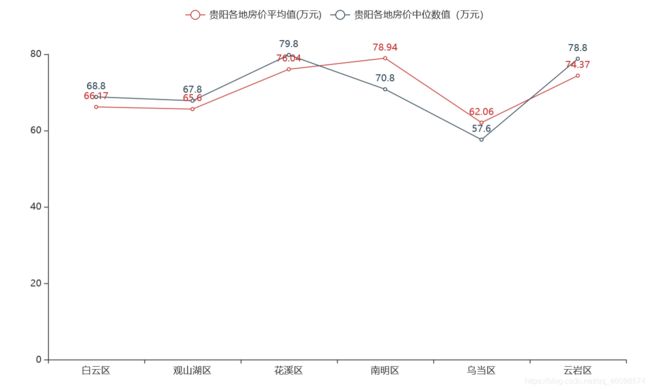
分析一下:
折线图直观明了地告诉了我们以下信息:
在这六个区中乌当区的平均房价和中位数远低于其他几个区,其中花溪区和云岩区以及南明区不相上平均房价为79万左右,说明这两地的经济水平,购房水平比较相似。乌当区经济水平和居民购房能力较弱。
2:绘制上述的柱状图
def bar() -> Bar:
c = (
Bar({"theme": ThemeType.MACARONS})
.add_xaxis(place)
.add_yaxis("平均值", avgs)
.add_yaxis("中位数", median)
.set_global_opts(
title_opts={"text": "贵阳各地房价(万元)"}
)
)
return c
bar().render("predict_bar.html")
同样的方式查看一下:
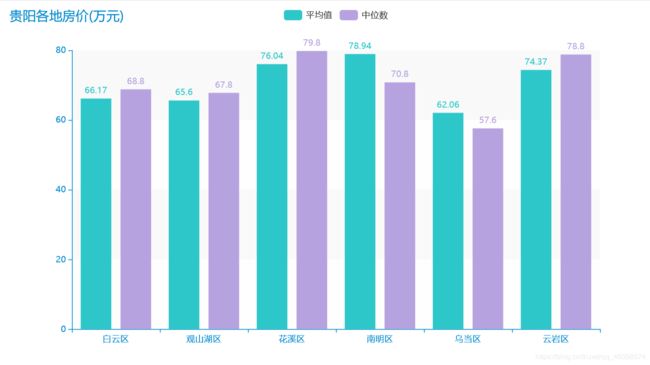
3:绘制各区房型与数量的关系柱状图:
def bar() -> Bar:
c = (
Bar({"theme": ThemeType.MACARONS})
.add_xaxis(houseidfo)
.add_yaxis(place[0], [280, 56, 504, 1676, 1680])
.add_yaxis(place[1], [392, 112, 448, 1679, 1680])
.add_yaxis(place[2], [224, 0, 616, 3359, 3360])
.add_yaxis(place[3], [448, 112, 280, 1679, 1680])
.add_yaxis(place[4], [504, 0, 336, 1680, 1679])
.add_yaxis(place[-1], sum_house)
# .add_yaxis("中位数", favourate_median)
.set_global_opts(
title_opts={"text": "贵阳各地房型\n数量"}
)
)
return c
bar().render("house_bar.html")
查看一下:
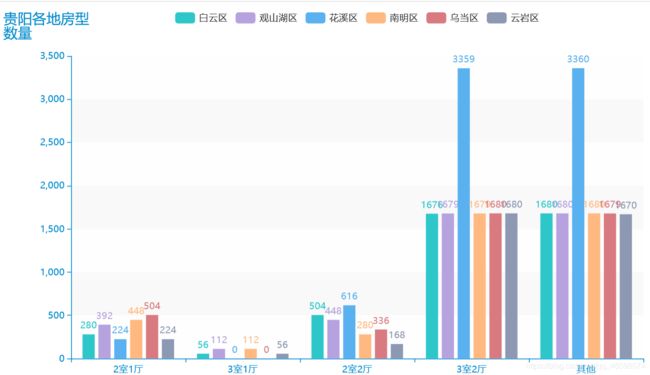
可以看到各区普遍是三室两厅和其他房型较多,其中花溪区的三室两厅远超平均水平,其他区比较持平。
4:绘制各区平均房间收藏人数和中位数饼状图
list_num = favourate_avg
attr = place
# print(zip(attr, list_num))
s = [list(z) for z in zip(attr, list_num)]
c = (Pie().add("", s).set_global_opts(title_opts=opts.TitleOpts(title="贵阳市各区楼房\n平均收藏人数"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render("pie_avg.html")
list_num = favourate_median
attr = place
# print(zip(attr, list_num))
s = [list(z) for z in zip(attr, list_num)]
c = (Pie().add("", s).set_global_opts(title_opts=opts.TitleOpts(title="贵阳市各区楼房\n收藏人数中位数"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render("pie_median.html")
看效果:
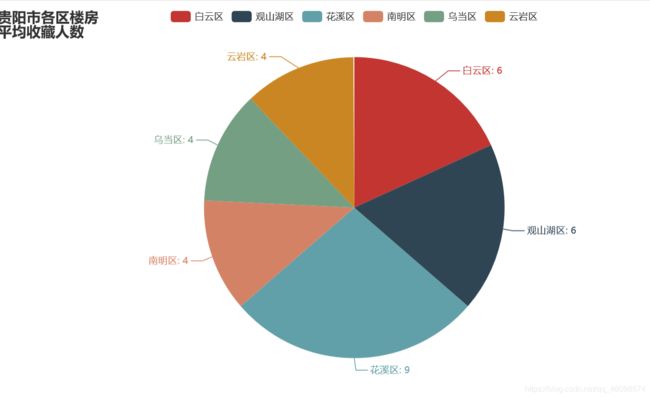
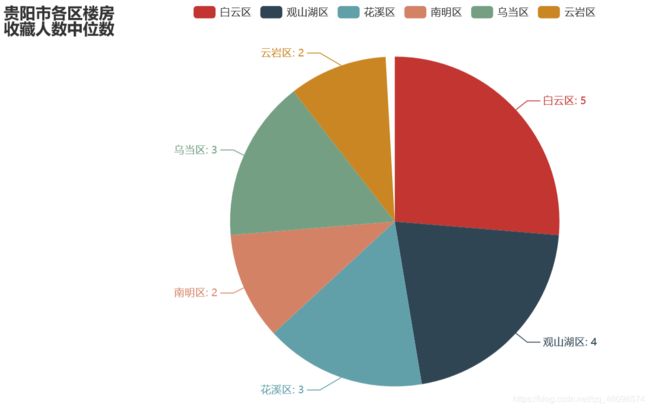
5:绘制贵阳各地房子平均面积\n(平米)折线图
line = Line()
line.add_xaxis(place)
line.add_yaxis("贵阳各地房子平均面积\n(平米)", area)
line.render("Area_line.html")
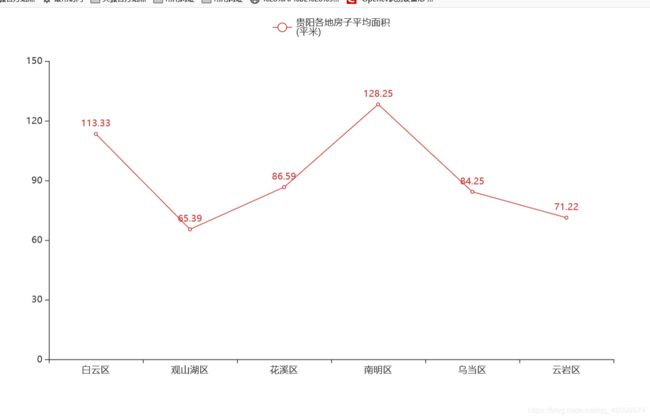
可以看到南明区的房间的平均面积最大,观山湖区最小,右上可以看出,南明区的房价又高,面积又大不过收藏人数缺平均最低,可见可能由于郊区等原因,购房群体较少
6:绘制房型和用户收藏人数和房间价格三维立体散点图
from pyecharts import options as opts
from pyecharts.charts import Scatter3D
from pyecharts.faker import Faker
price=[float(i)/1 for i in price]
# print(price)
# types=list(map(mapfunc,df.house_type.values))
# type = [224, 56, 168, 1680, 1670]
data = []
# print(fav,type)
# for j in range(len(type)):
# for k in range(len(fav)):
for j in range(100):
for k in range(100):
for i in range(500):
try:
data.append([type[j], favourate_avg[k],price[i]])
except:
continue
# print(data)
scatter = (
Scatter3D(init_opts=opts.InitOpts(width='900px', height='600px')) # 初始化
.add("", data,
grid3d_opts=opts.Grid3DOpts(
width=300, depth=300, rotate_speed=300, is_rotate=True,
),)
# 设置全局配置项
.set_global_opts(
title_opts=opts.TitleOpts(title="房型——关注度——价格\n三维关系图"), # 添加标题
visualmap_opts=opts.VisualMapOpts(
max_=100, # 最大值
pos_top=200, # visualMap 组件离容器上侧的距离
range_color=Faker.visual_color # 颜色映射
)
)
# .render("3D散点图.html")
)
print('数据分析和可视化结束,左边点开~')
可看到:
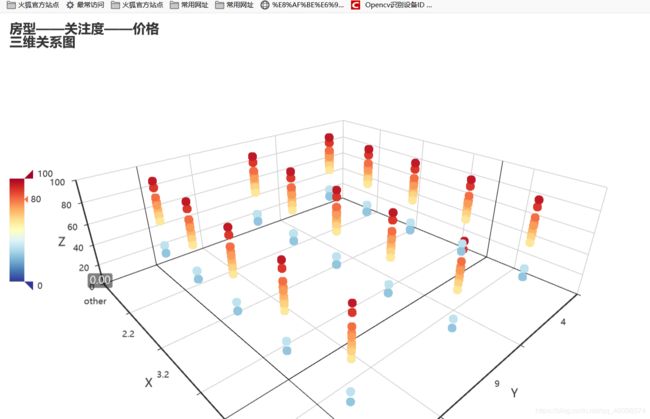
说明房型为三室两厅的情况下,用户的收藏喜爱程度和价格都可关,人们普遍喜欢80万左右的三室两厅房子。
最后总结一下:
我们通过爬取网站中贵阳市的6个区的房价,做了数据分析,并可视化呈现出来,为了更直观的感受到,各个维度之间的影响(见上)。完善的实验,可以成为有利的论据,今天的分享到此结束。感谢~
最后请务必关注一下博主,码字不易~