MapReduce实现WordCount
1,搭建开发环境。
(1) 上传maven和eclipse安装包到Linux环境目录。软件版本分别为:eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz,apache-maven-3.0.5-bin.tar.gz。解压软件到指定目录下即可。
(2) 配置maven环境变量。以root用户执行命令 # vi /etc/profile ,增加MAVEN_HOME=/home/zpl/software/apache-maven-3.0.5,并修改path: exportPATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin,退出root用户,执行一下命令source /etc/profile
(3) 建立Maven本地仓库。在/home/zpl目录下新建 .m2目录,将之前maven安装目录下con目录下的setting.xml文件拷贝到新建的.m2目录, $ cp /home/zpl/software/apache-maven-3.0.5/conf/settings.xml /home/zpl/.m2/,为了节省时间,将之前下载好的repository.tar.gz上传到.m2目录下,解压。
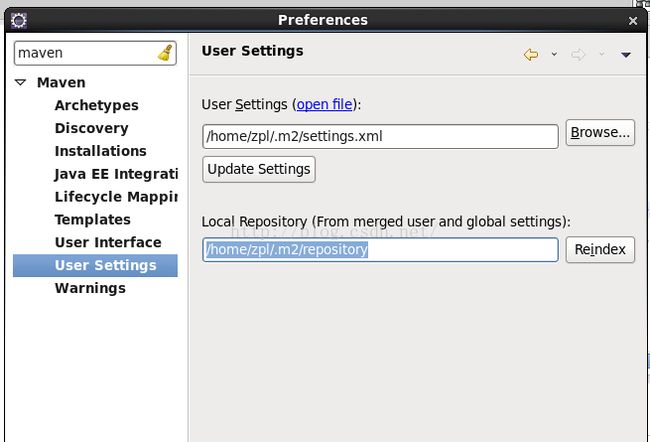
(4) 配置eclipse。解压eclipse到安装目录下,启动。配置maven环境,Window->Preferences->Maven->UserSettings ,分别选择.m2路径下的setting.xml文件和repository,保存退出。
2,新建配置maven工程。
New->Maven project ,选择next直到输入groupId和artifactId页面,输入groupId和artifactId,此时自动生成package为 groupId+artifactId,
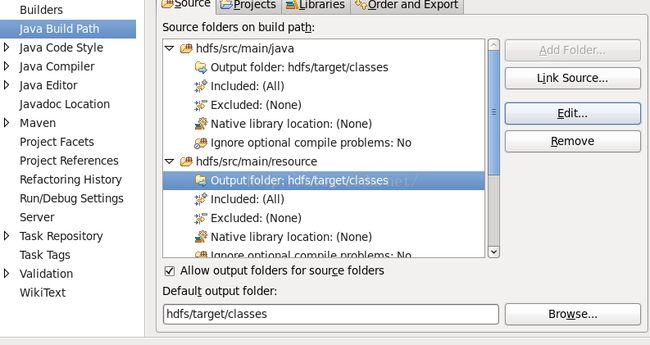
Finish创建成功,新建src/main/resource目录,并将Output folder改为新建的resource目录,这样每次打包文件自动会放在target目录下。
3,代码开发。
(1) 新建Java类WordCount,此类继承Configured类并实现Tool接口,所以要实现接口中的run()方法;
(2) 新建静态内部类wordCountMaper,此类继承Mapper基类:
public static class wordCountMaperextends Mapper
在wordCountMaper类中新建protected void map(LongWritable key, Textvalue, Context context)
throwsIOException, InterruptedException,
map方法有三个参数,LongWritable表示输入的key,一般是字符串在原始文件中的偏移量,Text即为文本内容,map每次读取一行数据。接下来需要将value转为String类型,并根据空格符拆分为数组,String lineValue = value.toString();
String[]values = lineValue.split(" ");循环数组,将每个字符输出到上下文context中,设置个数为1.
完整代码如下:
public static class wordCountMaper extendsMapper{
privatefinal static IntWritable one = new IntWritable(1);
privateText word = new Text();
protectedvoid map(LongWritable key, Text value, Context context)
throwsIOException, InterruptedException {
StringlineValue = value.toString();
String[]values = lineValue.split(" ");
for(Strings:values){
word.set(s);
/**每个单词出现的次数是1**/
context.write(word,one);
}
}
} (3) 新建wordCountReducer类,继承Reducer接口。public static class wordCountReducer extendsReducer
在类中新建protected void reduce(Text key,Iterable
Contextcontext),
从map到reduce的过程中shuffle会自动将数据根据相同的key进行合并,最终形成的结果为{key,value1,value2,value3…..}所以reduce输入value为list类型,接下来汇总List中数据的个数,得到单词的总个数。
int sum = 0;
/**计算每个单词的总数**/
for(IntWritable val:values){
sum+=val.get();
}
result.set(sum);
context.write(key,result);
}(4) 新建Run方法。在run方法中需要设置job相关参数,如输入输出路径,map和reduce类型等,如下:
Configurationconf = super.getConf();
/**获取实例对象**/
Jobjob = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
/**设置Map相关参数,如输出输出类型**/
job.setMapperClass(wordCountMaper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
/**设置Reduce相关参数**/
job.setReducerClass(wordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/**设置输入输出路径,以参数的形式传递**/
Pathinpath = new Path(args[0]);
FileInputFormat.addInputPath(job,inpath);
Pathoutpath = new Path(args[1]);
FileOutputFormat.setOutputPath(job,outpath);
/**提交job**/
booleanresult = job.waitForCompletion(true);
/**如果成功返回1,失败返回0**/
returnresult ? 1 : 0;
(5) 新建main方法,设置要传入的参数。
/**设置HDFS输入输出路径**/
args = new String[]{
"hdfs://zpl-hadoop:8020/wcinput",
"hdfs://zpl-hadoop:8020/output"
};
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WordCount(), args);
System.exit(status);4,打成jar包,在伪分布式环境上运行。
(1) 在工程上右击,选择export—>jar,要确保导出的路径是存在的,如果不存在则新建。

(2)启动namenode,datanode,resourcemanager,nodemanager,在hdfs上新建输入路径wcinput,输出路径output,上传文件到wcinput下
(3)运行命令 bin/yar jar jars/mr-wordcount.jar /wcinput /output