Tair学习
一.简介
Tair是一个高性能、分布式、可扩展、高可靠的Key-Value nosql结构存储系统,专注于高速缓存场景。
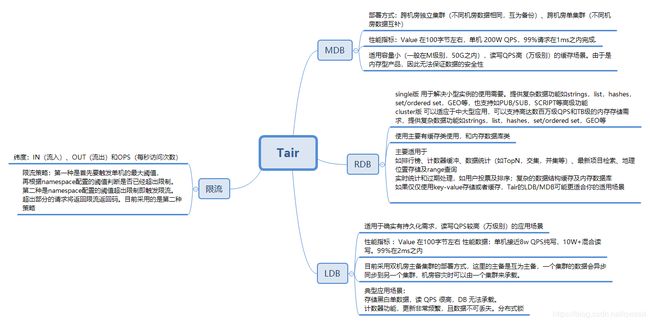
Tair有三种类型mdb,ldb,rdb:
(1) mdb是定位于cache缓存,类似于memcache的一个支持kv 内存缓存框架
(2) rdb是 定位于cache缓存,采用了redis的内存存储结构的一个支持kv、list等复杂数据结构的缓存框架
(3) ldb是一个定位于高性能存储,并可选择内嵌mdb cache加速,这种情况下cache与持久化存储的数据一致性由tair进行维护,支持kv及分级key存储,数据排序的缓存框架
其中,mdb可用于高速缓存或内存存储,rdb可用于高速缓存,ldb可用于持久存储。
二.基本概念
1.configID
唯一标识一个tair集群,每个集群都有一个对应的configID,在当前的大部分应用情况下configID是存放在diamond中的,对应了该集群的configserver地址和groupname。业务在初始化tairclient的时候需要配置此ConfigID。
2.Namespace
又称area,是tair中分配给应用的一个内存或者持久化存储区域,可以认为应用的数据存在自己的namespace中。支持不同的数据使用相同的key而内容不冲突。
3.quota配额
对应了每个namespace储存区的大小限制,超过配额后数据将面临最近最少使用(LRU)的淘汰。
4.配额计算
配额大小直接影响数据的命中率和资源利用效率,业务方需要给出一个合适的值,通常的计算方法是评估在保证一定命中率情况下所需要的记录条数,这样配额大小即为:记录条数*平均单条记录大小。
5.ExpireTime过期时间
expiredTime 是指数据的过期时间,当超过过期时间之后,数据将对应用不可见,这个设置同样影响到应用的命中率和资源利用率。不同的存储引擎有不同的策略清理掉过期的数据。调用接口时,expiredTime单位是秒。可以是相对时间(比如:30s),也可以是绝对时间(时间戳,比如:当天23时,转换成距离1970-1-1 00:00:00的秒数)。
(1) 小于0,不更改之前的过期时间;
(2) 如果不传或者传入0,则表示数据永不过期;
(3) 大于0小于当前时间戳是相对时间过期;
(4) 大于当前时间戳是绝对时间过期;
6.version
Tair中存储的每个数据都有版本号,版本号在每次更新后都会递增,相应的,在Tair put接口中也有此version参数,这个参数是为了解决并发更新同一个数据而设置的,类似于乐观锁。 很多情况下,更新数据是先get,修改get回来的数据,然后put回系统。如果有多个客户端get到同一份数据,都对其修改并保存,那么先保存的修改就会被后到达的修改覆盖,从而导致数据一致性问题,在大部分情况下应用能够接受,但在少量特殊情况下,这个是我们不希望发生的。
三.Tair架构
一个Tair集群主要包括3个必选模块:ConfigServer、DataServer和Client,一个可选模块:InvalidServer。
通常情况下,一个集群中包含2台configserver及多台dataServer。两台configserver互为主备并通过维护和dataserver之间的心跳获知集群中存活可用的dataserver,构建数据在集群中的分布信息(对照表)。dataserver负责数据的存储,并按照configserver的指示完成数据的复制和迁移工作。client在启动的时候,从configserver获取数据分布信息,根据数据分布信息和相应的dataserver交互完成用户的请求。invalidserver主要负责对等集群的删除和隐藏操作,保证对等集群的数据一致。
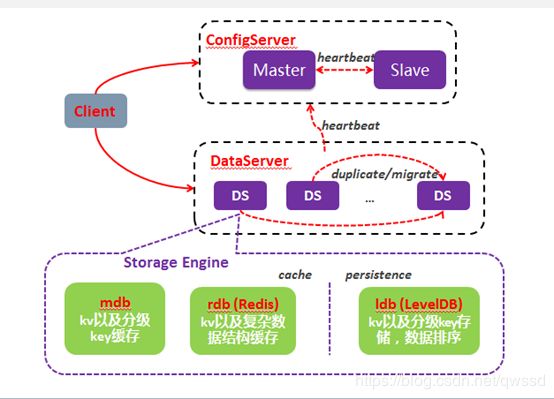
1.ConfigServer功能
(1) 通过维护和DataServer心跳来获知集群中存活节点的信息
(2) 根据存活节点的信息来构建数据在集群中的分布表
(3) 提供数据分布表的查询服务
(4) 调度DataServer之间的数据迁移、复制
2.DataServer功能
(1) 提供存储引擎
(2) 接受Client的put/get/remove等操作
(3) 执行数据迁移,复制等
(4) 插件:在接受请求的时候处理一些自定义功能
(5) 访问统计
3.InvalidServer功能
(1) 接收来自Client的invalid/hide等请求后,对属于同一组的集群(双机房独立集群部署方式)做delete/hide操作,保证同一组集群的一致
(2) 集群断网之后的,脏数据清理
(3) 访问统计
4.Client功能
(1) 在应用端提供访问Tair集群的接口
(2) 更新并缓存数据分布表和InvalidServer地址等
(3) LocalCache,避免过热数据访问影响tair集群服务
(4) 流控
四.技术点
1. 对照表【别名路由表】
(1) 数据划分:key/hash
(2) 建表规则:考虑各个机器的负载均衡,考虑机架、集群
(3) 表重建和同步:重建就意味着会有迁移,有同步、异步迁移模式【主要是依赖于binlog】
(4) Bucket【桶】:数据几批会同时路由到一条机器
(5) Version:每次表重建都会有个版本
(6) 扩展性:有了对照表,可以随意扩展容量
传统的路由方法通常是将key的hash值对机器取模,这样实现简单,但是在服务器数量发生变化时对原有分布冲击很大。Tair中采用对照表的方法改进这个问题:
key的hash值不是对服务器节点数取模,而是和一个固定的数取模,这个数通常远大于机器数,固定数范围内的每个值都与一个节点相对应,一台物理机器可以和多个值对应。这是一致性hash的一种变型。
2. 数据防丢:
(1) binlog
(2) 单备份
(3) 双备份
(4) 双机房双备份
(5) ConfigServer主备结构
3. 热点:
(1) load cache
(2) 客户端本地缓存
(3) 某台server流控
(4) 多实例
4. 数据复制
(1) 对客户端透明:就是说客户端不应该知道这件事,且不应该对客户端产生影响
(2) 客户端只写主DS:底层会进行复制同步
(3) 由主DS负责复制