基于Openpose框架的人脸关键点heatmaps预测模型设计、训练
众所周知,人脸识别中有一项重要的任务-人脸关键点预测,通过这个环节对齐,才能进行人脸识别,提高人脸识别的准确率。另外,一些活体检测/人脸状态分析也需要利用该方案进行实现。
经典的人脸检测模型MTCNN中具有人脸关键点的预测功能,但其关键预测精度比较差,对于大角度、模糊、遮挡、小尺度等情况的人脸效果下降更加严重。因此我结合openpose的关键点预测模型,自行设计了如下的人脸关键点热图预测模型,经过验证可以很好的实现人脸关键点预测的效果。
训练网络设计
由于经典的openpose框架中heatmaps的热图有6个stage进行预测和中间监督,但我按照原始的框架发现到达后面几个stage后,loss基本和前面的stage一致,但多个stage对模型的速度会有影响,因此设计了3个stage和4个stage的版本,这里主要介绍4个stage的版本。
利用netscope可以将设计的网络可视化如下(如果看不清,可以利用我下面提供的proto内容自行验证):
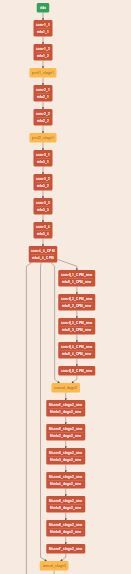

所设计的网络proto文件内容如下:
name: "landmarks-net"
input: "data"
input_shape {
dim: 1
dim: 3
dim: 112
dim: 112
}
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1_stage1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1_stage1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1_stage1"
top: "conv2_1"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2_stage1"
type: "Pooling"
bottom: "conv2_2"
top: "pool2_stage1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2_stage1"
top: "conv3_1"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "conv3_4"
type: "Convolution"
bottom: "conv3_3"
top: "conv3_4"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3_4"
type: "ReLU"
bottom: "conv3_4"
top: "conv3_4"
}
layer {
name: "conv4_4_CPM"
type: "Convolution"
bottom: "conv3_4"
top: "conv4_4_CPM"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu4_4_CPM"
type: "ReLU"
bottom: "conv4_4_CPM"
top: "conv4_4_CPM"
}
layer {
name: "conv5_1_CPM_new"
type: "Convolution"
bottom: "conv4_4_CPM"
top: "conv5_1_CPM_new"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu5_1_CPM_new"
type: "ReLU"
bottom: "conv5_1_CPM_new"
top: "conv5_1_CPM_new"
}
layer {
name: "conv5_2_CPM_new"
type: "Convolution"
bottom: "conv5_1_CPM_new"
top: "conv5_2_CPM_new"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu5_2_CPM_new"
type: "ReLU"
bottom: "conv5_2_CPM_new"
top: "conv5_2_CPM_new"
}
layer {
name: "conv5_3_CPM_new"
type: "Convolution"
bottom: "conv5_2_CPM_new"
top: "conv5_3_CPM_new"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu5_3_CPM_new"
type: "ReLU"
bottom: "conv5_3_CPM_new"
top: "conv5_3_CPM_new"
}
layer {
name: "conv5_4_CPM_new"
type: "Convolution"
bottom: "conv5_3_CPM_new"
top: "conv5_4_CPM_new"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu5_4_CPM_new"
type: "ReLU"
bottom: "conv5_4_CPM_new"
top: "conv5_4_CPM_new"
}
layer {
name: "conv5_5_CPM_new"
type: "Convolution"
bottom: "conv5_4_CPM_new"
top: "conv5_5_CPM_new"
param {
lr_mult: 1.0
decay_mult: 1
}
param {
lr_mult: 2.0
decay_mult: 0
}
convolution_param {
num_output: 5
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "concat_stage2"
type: "Concat"
bottom: "conv5_5_CPM_new"
bottom: "conv4_4_CPM"
top: "concat_stage2"
concat_param {
axis: 1
}
}
layer {
name: "Mconv1_stage2_new"
type: "Convolution"
bottom: "concat_stage2"
top: "Mconv1_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu1_stage2_new"
type: "ReLU"
bottom: "Mconv1_stage2_new"
top: "Mconv1_stage2_new"
}
layer {
name: "Mconv2_stage2_new"
type: "Convolution"
bottom: "Mconv1_stage2_new"
top: "Mconv2_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu2_stage2_new"
type: "ReLU"
bottom: "Mconv2_stage2_new"
top: "Mconv2_stage2_new"
}
layer {
name: "Mconv3_stage2_new"
type: "Convolution"
bottom: "Mconv2_stage2_new"
top: "Mconv3_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu3_stage2_new"
type: "ReLU"
bottom: "Mconv3_stage2_new"
top: "Mconv3_stage2_new"
}
layer {
name: "Mconv4_stage2_new"
type: "Convolution"
bottom: "Mconv3_stage2_new"
top: "Mconv4_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu4_stage2_new"
type: "ReLU"
bottom: "Mconv4_stage2_new"
top: "Mconv4_stage2_new"
}
layer {
name: "Mconv5_stage2_new"
type: "Convolution"
bottom: "Mconv4_stage2_new"
top: "Mconv5_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu5_stage2_new"
type: "ReLU"
bottom: "Mconv5_stage2_new"
top: "Mconv5_stage2_new"
}
layer {
name: "Mconv6_stage2_new"
type: "Convolution"
bottom: "Mconv5_stage2_new"
top: "Mconv6_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu6_stage2_new"
type: "ReLU"
bottom: "Mconv6_stage2_new"
top: "Mconv6_stage2_new"
}
layer {
name: "Mconv7_stage2_new"
type: "Convolution"
bottom: "Mconv6_stage2_new"
top: "Mconv7_stage2_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 5
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "concat_stage3"
type: "Concat"
bottom: "Mconv7_stage2_new"
bottom: "conv4_4_CPM"
top: "concat_stage3"
concat_param {
axis: 1
}
}
layer {
name: "Mconv1_stage3_new"
type: "Convolution"
bottom: "concat_stage3"
top: "Mconv1_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu1_stage3_new"
type: "ReLU"
bottom: "Mconv1_stage3_new"
top: "Mconv1_stage3_new"
}
layer {
name: "Mconv2_stage3_new"
type: "Convolution"
bottom: "Mconv1_stage3_new"
top: "Mconv2_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu2_stage3_new"
type: "ReLU"
bottom: "Mconv2_stage3_new"
top: "Mconv2_stage3_new"
}
layer {
name: "Mconv3_stage3_new"
type: "Convolution"
bottom: "Mconv2_stage3_new"
top: "Mconv3_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu3_stage3_new"
type: "ReLU"
bottom: "Mconv3_stage3_new"
top: "Mconv3_stage3_new"
}
layer {
name: "Mconv4_stage3_new"
type: "Convolution"
bottom: "Mconv3_stage3_new"
top: "Mconv4_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu4_stage3_new"
type: "ReLU"
bottom: "Mconv4_stage3_new"
top: "Mconv4_stage3_new"
}
layer {
name: "Mconv5_stage3_new"
type: "Convolution"
bottom: "Mconv4_stage3_new"
top: "Mconv5_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu5_stage3_new"
type: "ReLU"
bottom: "Mconv5_stage3_new"
top: "Mconv5_stage3_new"
}
layer {
name: "Mconv6_stage3_new"
type: "Convolution"
bottom: "Mconv5_stage3_new"
top: "Mconv6_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu6_stage3_new"
type: "ReLU"
bottom: "Mconv6_stage3_new"
top: "Mconv6_stage3_new"
}
layer {
name: "Mconv7_stage3_new"
type: "Convolution"
bottom: "Mconv6_stage3_new"
top: "Mconv7_stage3_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 5
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "concat_stage4"
type: "Concat"
bottom: "Mconv7_stage3_new"
bottom: "conv4_4_CPM"
top: "concat_stage4"
concat_param {
axis: 1
}
}
layer {
name: "Mconv1_stage4_new"
type: "Convolution"
bottom: "concat_stage4"
top: "Mconv1_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu1_stage4_new"
type: "ReLU"
bottom: "Mconv1_stage4_new"
top: "Mconv1_stage4_new"
}
layer {
name: "Mconv2_stage4_new"
type: "Convolution"
bottom: "Mconv1_stage4_new"
top: "Mconv2_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu2_stage4_new"
type: "ReLU"
bottom: "Mconv2_stage4_new"
top: "Mconv2_stage4_new"
}
layer {
name: "Mconv3_stage4_new"
type: "Convolution"
bottom: "Mconv2_stage4_new"
top: "Mconv3_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu3_stage4_new"
type: "ReLU"
bottom: "Mconv3_stage4_new"
top: "Mconv3_stage4_new"
}
layer {
name: "Mconv4_stage4_new"
type: "Convolution"
bottom: "Mconv3_stage4_new"
top: "Mconv4_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu4_stage4_new"
type: "ReLU"
bottom: "Mconv4_stage4_new"
top: "Mconv4_stage4_new"
}
layer {
name: "Mconv5_stage4_new"
type: "Convolution"
bottom: "Mconv4_stage4_new"
top: "Mconv5_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 3
kernel_size: 7
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu5_stage4_new"
type: "ReLU"
bottom: "Mconv5_stage4_new"
top: "Mconv5_stage4_new"
}
layer {
name: "Mconv6_stage4_new"
type: "Convolution"
bottom: "Mconv5_stage4_new"
top: "Mconv6_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "Mrelu6_stage4_new"
type: "ReLU"
bottom: "Mconv6_stage4_new"
top: "Mconv6_stage4_new"
}
layer {
name: "Mconv7_stage4_new"
type: "Convolution"
bottom: "Mconv6_stage4_new"
top: "Mconv7_stage4_new"
param {
lr_mult: 4.0
decay_mult: 1
}
param {
lr_mult: 8.0
decay_mult: 0
}
convolution_param {
num_output: 5
pad: 0
kernel_size: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
}
}
}
训练数据
我主要使用了数据集CelebA,并且按照1:1的比例,从中抽取了正脸和大角度的人脸作为训练数据。
标签文件:我根据CelebA中人脸的关键点标签,为每个关键点生成了单峰的heatmaps标签文件。标签文件可视化后如下图样子:





需要可以私信我交流。
最终训练结果如下:
I0906 05:13:55.329042 5065 solver.cpp:243] Iteration 41960, loss = 0.5419
I0906 05:13:55.329210 5065 solver.cpp:259] Train net output #0: land_loss_stage = 0.281634 (* 1 = 0.281634 loss)
I0906 05:13:55.329221 5065 solver.cpp:259] Train net output #1: land_loss_stage2 = 0.0835331 (* 1 = 0.0835331 loss)
I0906 05:13:55.329238 5065 solver.cpp:259] Train net output #2: land_loss_stage3 = 0.0827685 (* 1 = 0.0827685 loss)
I0906 05:13:55.329244 5065 solver.cpp:259] Train net output #3: land_loss_stage4 = 0.0939632 (* 1 = 0.0939632 loss)
I0906 05:13:55.329252 5065 sgd_solver.cpp:138] Iteration 41960, lr = 8.1e-07
I0906 05:14:18.058833 5065 solver.cpp:243] Iteration 41980, loss = 0.487881
I0906 05:14:18.058876 5065 solver.cpp:259] Train net output #0: land_loss_stage = 0.261268 (* 1 = 0.261268 loss)
I0906 05:14:18.058885 5065 solver.cpp:259] Train net output #1: land_loss_stage2 = 0.0769336 (* 1 = 0.0769336 loss)
I0906 05:14:18.058892 5065 solver.cpp:259] Train net output #2: land_loss_stage3 = 0.0663182 (* 1 = 0.0663182 loss)
I0906 05:14:18.058897 5065 solver.cpp:259] Train net output #3: land_loss_stage4 = 0.0833601 (* 1 = 0.0833601 loss)
I0906 05:14:18.058903 5065 sgd_solver.cpp:138] Iteration 41980, lr = 8.1e-07
I0906 05:14:39.636696 5065 solver.cpp:596] Snapshotting to binary proto file /home/work/glenn/gitmodel/caffe-face/face_example/landmarks_data/train_map/snapshot_iter_42000.caffemodel
I0906 05:14:40.695569 5065 sgd_solver.cpp:307] Snapshotting solver state to binary proto file /home/work/glenn/gitmodel/caffe-face/face_example/landmarks_data/train_map/snapshot_iter_42000.solverstate
I0906 05:14:41.087797 5065 solver.cpp:332] Iteration 42000, loss = 0.826902
I0906 05:14:41.087839 5065 solver.cpp:337] Optimization Done.
I0906 05:14:41.087843 5065 caffe.cpp:254] Optimization Done.模型测试
经过约4w步迭代,模型的预测结果如下:



可以改进的点
1)每个stage中都有采用7*7的大卷积核,可以考虑拆分为多个3*3的小卷积核,减少参数量并提高速度
2)考虑引入residual unit增加低层信息融合和传递的能力
3)更换头网络,加强提取特征的能力
4)增大模型的输入(目前采用112*112的尺寸输入),主流的关键点模型输入一般为256*256左右,并且考虑更换数据集预测68个关键点。
5)借鉴hourglass的思想,在每个stage unit的内部引入encoder-decoder的结构。