python 基础知识--note

算术运算符
算术运算
+加-减*乘/除%取模(相除后的余数)**取幂(注意^并不执行该运算,你可能在其他语言中见过这种情形)//相除后向下取整到最接近的整数
关于按位运算符的更多信息请参阅此处。Python 也遵守一般的数学运算顺序,你可以访问以下网页以复习这方面的知识:https://en.wikipedia.org/wiki/Operation_(mathematics)。
关于取模运算,更多信息请参考这里。值得注意的是,取模运算和取余运算是一个非常容易混淆的概念。
变量和赋值运算符:
在 Python 中命名变量时,还需要注意以下几个事项:
1. 只能在变量名称中使用常规字母、数字和下划线。不能包含空格,并且需要以字母或下划线开头。
2. 不能使用保留字或内置标识符,它们在 Python 中具有重要含义,你将在整个这门课程中学到这些知识。python 保留字列表请参阅此处。创建对值清晰描述的名称可以帮助你避免使用这些保留字。下面是这些保留字的简要表格。

3. 在 python 中,变量名称的命名方式是全部使用小写字母,并用下划线区分单词。
True:
my_height = 58
my_lat = 40
my_long = 105False:
my height = 58
MYLONG = 40
MyLat = 105虽然最后两个在 python 中可以运行,但是它们并不是在 python 中命名变量的推荐方式。我们命名变量的方式称之为 snake case,因为我们用下划线连接单词。
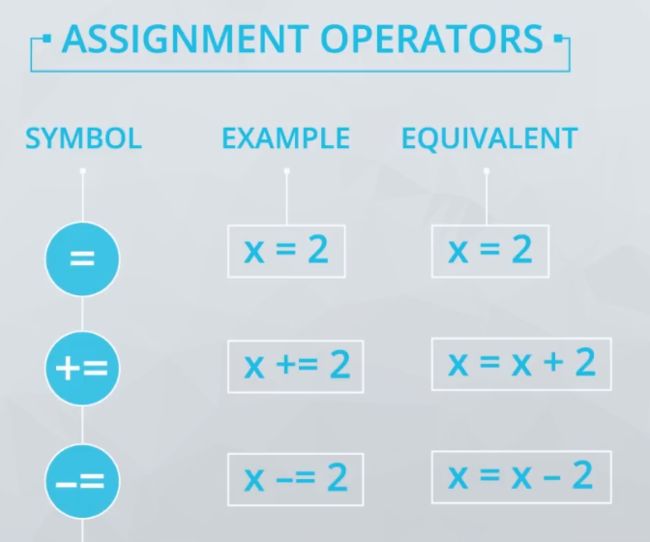
赋值运算符
以下是视频中的赋值运算符。你还可以按照类似的方式使用 *=,但是与下方所示的运算符相比不太常见。你可以在此处找到我们已经介绍的大部分知识的实践内容:
整数和浮点数:
整数和浮点数
数字值可以用到两种 python 数据类型:
- int - 表示整数值
- float - 表示小数或浮点数值
你可以通过以下语法创建具有某个数据类型的值:
x = int(4.7) # x is now an integer 4
y = float(4) # y is now a float of 4.0你可以使用函数 type 检查数据类型:
>>> print(type(x))
int
>>> print(type(y))
float
因为 0.1 的浮点数(或近似值)实际上比 0.1 稍微大些,当我们将好几个这样的值相加时,可以看出在数学上正确的答案与 Python 生成的答案之间有区别。
>>> print(.1 + .1 + .1 == .3)
False你可以在此处了解详情。
Python 最佳做法
要了解所有的最佳做法,请参阅 PEP8 指南。
你可以使用 atom 软件包 linter-python-pep8 在 Atom 文本编辑器中自己的编程环境中使用 pep8
Ture
print(4 + 5)False
print( 4 + 5)
每行代码应该不超过 80 个字符,虽然在某些使用情况下,99 个字符也可以。此规则是由 IBM 制定的。
这些惯例为何很重要?虽然代码格式不会影响到运行效果,但是遵守标准样式指南使代码更容易阅读,并且在团队内的不同开发者之间保持一致。
for example:
print(5/0)Traceback (most recent call last):
File "/tmp/vmuser_tnryxwdmhw/quiz.py", line 1, in
print(5/0)
ZeroDivisionError: division by zero Traceback 表示“程序崩溃时正在干什么”!这部分通常没有错误的最后一行代码有用。虽然可以调查错误的剩余部分,但是直接查看最后一行代码 ZeroDivisionError,消息提醒我们除以了零。Python 也需要遵守数学规则!
通常,我们需要注意两种类型的错误
- 异常
- 语法错误
异常是代码运行时发生的问题,而语法错误是 Python 在运行代码之前检查代码时发现的问题。要了解详情,请参阅关于错误和异常的 Python 教程页面。
布尔型运算符、比较运算符和逻辑运算符
布尔数据类型存储的是值 True 或 False,通常分别表示为 1 或 0。
通常有 6 个比较运算符会获得布尔值:
比较运算符
比较运算符
符号使用情况 布尔型 运算符
5 < 3 False 小于
5 > 3 True 大于
3 <= 3 True 小于或等于
3 >= 5 False 大于或等于
3 == 5 False 等于
3 != 5 True 不等于你需要熟悉三个逻辑运算符:
逻辑使用情况 布尔型 运算符
5 < 3 and 5 == 5 False and - 检查提供的所有语句是否都为 True
5 < 3 or 5 == 5 True or - 检查是否至少有一个语句为 True
not 5 < 3 True not - 翻转布尔值要详细了解 George Bool 如何改变了这个世界,请参阅这篇文章!
字符串
在 python 中,字符串的变量类型显示为 str。你可以使用双引号 " 或单引号 ' 定义字符串。如果你要创建的字符串包含其中一种引号,你需要确保代码不会出错。
>>> my_string = 'this is a string!'
>>> my_string2 = "this is also a string!!!"还可以在字符串中使用 \,以包含其中一种引号:
>>> this_string = 'Simon\'s skateboard is in the garage.'
>>> print(this_string)Simon's skateboard is in the garage.如果不使用 \,注意我们遇到了以下错误:
>>> this_string = 'Simon's skateboard is in the garage.'File "", line 1
this_string = 'Simon's skateboard is in the garage.'
^
SyntaxError: invalid syntax 颜色高亮部分也表示第二种情形中的字符串有什么错误。你还可以对字符串执行其他多种操作。在此视频中,你看到了一些操作:
>>> first_word = 'Hello'
>>> second_word = 'There'
>>> print(first_word + second_word)
HelloThere
>>> print(first_word + ' ' + second_word)
Hello There
>>> print(first_word * 5)
HelloHelloHelloHelloHello
>>> print(len(first_word))
5与你到目前为止见到的其他数据类型不同,你还可以使用字符串索引,稍后我们将详细讲解!暂时先看下面这个小示例。注意,Python 索引以 0 开始
>>> first_word[0]
H
>>> first_word[1]
e类型和类型转换
你到目前为止,已经见过四种数据类型:
整型浮点型布尔型字符串
你在之前的视频中,简单了解了 type(),它可以用来检查你所处理的任何变量的数据类型。
>>> print(type(4))
int
>>> print(type(3.7))
float
>>> print(type('this'))
str
>>> print(type(True))
bool你发现,你可以更改变量类型以执行各种不同的操作。例如
"0" + "5"结果完全与以下代码的不一样0 + 5你认为以下代码的结果是什么?
"0" + 5下面的代码呢:
0 + "5"检查变量类型非常重要,可以确保在编程时你所获的结果是你想要的结果。
字符串方法
在此视频中,我们介绍了方法。方法就像某些你已经见过的函数:
len("this")type(12)print("Hello world")
上述三项都是函数。注意,它们使用了小括号并接受一个参数。
type 和 print 函数可以接收字符串、浮点型、整型和很多其他数据类型的参数,函数 len 也可以接受多种不同数据类型的参数,稍后你将在这节课中详细了解。
python 中的方法和函数相似,但是它针对的是你已经创建的变量。方法与特定变量中的数据类型相关。 方法相当于通过.来调用的一种函数。例如,lower()是一个字符串方法,对于一个叫 "sample string" 的字符串,它可以这样使用:sample_string.lower()。
下图显示了任何字符串都可以使用的方法。

每个方法都接受字符串本身作为该方法的第一个参数。但是,它们还可以接收其他参数。我们来看看几个示例的输出。
>>> my_string.islower()
True
>>> my_string.count('a')
2
>>> my_string.find('a')
3可以看出,count 和 find 方法都接受另一个参数。但是,islower 方法不接受参数。如果我们要在变量中存储浮点数、整数或其他类型的数据,可用的方法可能完全不同!
任何专业人士都无法记住所有方法,因此知道如何通过文档查询答案非常重要。掌握扎实的编程基础使你能够利用这些基础知识查询文档,并且构建的程序比死记硬背所有 python 可用函数的人士构建的程序强大得多。
要详细了解字符串和字符串方法,请参阅字符串方法文档。
列表和成员运算符
lst_of_random_things = [1, 3.4, 'a string', True]
这是一个包含 4 个元素的类别。在 python 中,所有有序容器(例如列表)的起始索引都是 0。因此,要从上述列表中获取第一个值,我们可以编写以下代码:
>>> lst_of_random_things[0]
1
似乎你可以使用以下代码获取最后一个元素,但实际上不可行:
>>> lst_of_random_things[len(lst_of_random_things)]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
----> 1 list[len(list)]
IndexError: list index out of range
但是,你可以通过使索引减一获取最后一个元素。因此,你可以执行以下操作:
>>> lst_of_random_things[len(lst_of_random_things) - 1]
True
此外,你可以使用负数从列表的末尾开始编制索引,其中 -1 表示最后一个元素,-2 表示倒数第二个元素,等等。
>>> lst_of_random_things[-1]
True
>>> lst_of_random_things[-2]
a string
列表切片
你发现,我们可以使用切片功能从列表中提取多个值。在使用切片功能时,务必注意,下限索引包含在内,上限索引排除在外。
因此:
>>> lst_of_random_things = [1, 3.4, 'a string', True]
>>> lst_of_random_things[1:2]
[3.4]
仅返回列表中的 3.4。注意,这与单个元素索引依然不同,因为你通过这种索引获得了一个列表。冒号表示从冒号左侧的起始值开始,到右侧的元素(不含)结束。
如果你要从列表的开头开始,也可以省略起始值。
>>> lst_of_random_things[:2]
[1, 3.4]
或者你要返回到列表结尾的所有值,可以忽略最后一个元素。
>>> lst_of_random_things[1:]
[3.4, 'a string', True]
这种索引和字符串索引完全一样,返回的值将是字符串。
在列表里还是不在列表里?
你发现,我们还可以使用 in 和 not in 返回一个布尔值,表示某个元素是否存在于列表中,或者某个字符串是否为另一个字符串的子字符串.
>>> 'this' in 'this is a string'
True
>>> 'in' in 'this is a string'
True
>>> 'isa' in 'this is a string'
False
>>> 5 not in [1, 2, 3, 4, 6]
True
>>> 5 in [1, 2, 3, 4, 6]
False可变性和顺序
可变性是指对象创建完毕后,我们是否可以更改该对象。如果对象(例如列表)可以更改,则是可变的。但是,如果无法更改对象以创建全新的对象(例如字符串),则该对象是不可变的。
>>> my_lst = [1, 2, 3, 4, 5]
>>> my_lst[0] = 'one'
>>> print(my_lst)
['one', 2, 3, 4, 5]
正如上述代码所显示的,你可以将上述列表中的 1 替换为 'one。这是因为,列表是可变的。
但是,以下代码不可行:
>>> greeting = "Hello there"
>>> greeting[0] = 'M'
这是因为,字符串是不可变的。意味着如果要更改该字符串,你需要创建一个全新的字符串。
对于你要使用的每种数据类型,你都需要注意两个事项:
- 可变吗?
- 有序吗?
字符串和列表都是有序的。但是,你将在后续部分看到某些数据类型是无序的。对于接下来要遇到的每种数据类型,有必要理解如何设定索引,可变吗,有序吗。了解数据结构的这些信息很有用!
此外,你将发现每种数据类型有不同的方法,因此为何使用一种数据类型(而不是另一种)在很大程度上取决于这些特性,以及如何轻松地利用这些特性!
实用的列表函数(第二部分)
join 方法
Join 是一个字符串方法,将字符串列表作为参数,并返回一个由列表元素组成并由分隔符字符串分隔的字符串。
new_str = "\n".join(["fore", "aft", "starboard", "port"])
print(new_str)
输出:
fore
aft
starboard
port
在此示例中,我们使用字符串 "\n" 作为分隔符,以便每个元素之间都有一个换行符。我们还可以在 .join 中使用其他字符串作为分隔符。以下代码使用的是连字符。
name = "-".join(["García", "O'Kelly"])
print(name)
输出:
García-O'Kelly
请务必注意,用英文逗号 (,) 将要连接的列表中的每项分隔开来。忘记分隔的话,不会触发错误,但是会产生意外的结果。
append 方法
实用方法 append 会将元素添加到列表末尾。
letters = ['a', 'b', 'c', 'd']
letters.append('z')
print(letters)
输出:
['a', 'b', 'c', 'd', 'z']
元组
元组是另一个实用容器。它是一种不可变有序元素数据类型。通常用来存储相关的信息。请看看下面这个关于纬度和经度的示例:
location = (13.4125, 103.866667)
print("Latitude:", location[0])
print("Longitude:", location[1])
元组和列表相似,它们都存储一个有序的对象集合,并且可以通过索引访问这些对象。但是与列表不同的是,元组不可变,你无法向元组中添加项目或从中删除项目,或者直接对元组排序。
元组还可以用来以紧凑的方式为多个变量赋值。
dimensions = 52, 40, 100
length, width, height = dimensions
print("The dimensions are {} x {} x {}".format(length, width, height))
在定义元组时,小括号是可选的,如果小括号并没有对解释代码有影响,程序员经常会忽略小括号。
在第二行,我们根据元组 dimensions 的内容为三个变量赋了值。这叫做元组解包。你可以通过元组解包将元组中的信息赋值给多个变量,而不用逐个访问这些信息,并创建多个赋值语句。
如果我们不需要直接使用 dimensions,可以将这两行代码简写为一行,一次性为三个变量赋值!
length, width, height = 52, 40, 100
print("The dimensions are {} x {} x {}".format(length, width, height))在创建元组时,小括号是可选的,如果小括号对解释代码没有影响,程序员经常会忽略它们。
tuple_a = 1, 2
tuple_b = (1, 2)
print(tuple_a == tuple_b)
print(tuple_a[1])
output:True
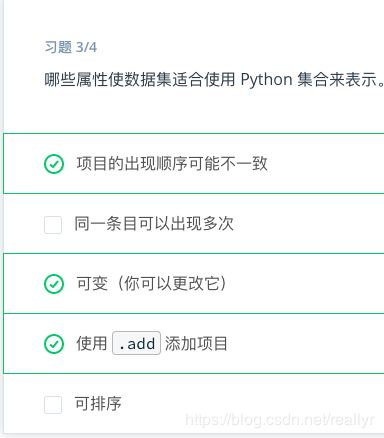
2集合
集合是一个包含唯一元素的可变无序集合数据类型。集合的一个用途是快速删除列表中的重复项。
numbers = [1, 2, 6, 3, 1, 1, 6]
unique_nums = set(numbers)
print(unique_nums)
输出为:
{1, 2, 3, 6}
集合和列表一样支持 in 运算符。和列表相似,你可以使用 add 方法将元素添加到集合中,并使用 pop 方法删除元素。但是,当你从集合中拿出元素时,会随机删除一个元素。注意和列表不同,集合是无序的,因此没有“最后一个元素”。
fruit = {"apple", "banana", "orange", "grapefruit"} # define a set
print("watermelon" in fruit) # check for element
fruit.add("watermelon") # add an element
print(fruit)
print(fruit.pop()) # remove a random element
print(fruit)
输出结果为:
False
{'grapefruit', 'orange', 'watermelon', 'banana', 'apple'}
grapefruit
{'orange', 'watermelon', 'banana', 'apple'}
你可以对集合执行的其他操作包括可以对数学集合执行的操作。可以对集合轻松地执行 union、intersection 和 difference 等方法,并且与其他容器相比,速度快了很多。
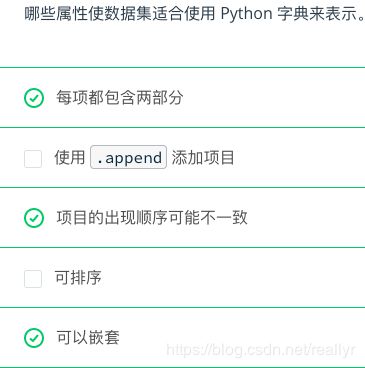
字典和恒等运算符
字典
字典是可变数据类型,其中存储的是唯一键到值的映射。下面是存储元素和相应原子序数的字典。
elements = {"hydrogen": 1, "helium": 2, "carbon": 6}
字典的键可以是任何不可变类型,例如整数或元组,而不仅仅是字符串。甚至每个键都不一定要是相同的类型!我们可以使用方括号并在括号里放入键,查询字典中的值或向字典中插入新值。
print(elements["helium"]) # print the value mapped to "helium"
elements["lithium"] = 3 # insert "lithium" with a value of 3 into the dictionary
我们可以像检查某个值是否在列表或集合中一样,使用关键字 in 检查值是否在字典中。字典有一个也很有用的相关方法,叫做 get。get 会在字典中查询值,但是和方括号不同,如果没有找到键,get 会返回 None(或者你所选的默认值)。
print("carbon" in elements)
print(elements.get("dilithium"))
输出结果为:
True
None
Carbon 位于该字典中,因此输出 True。Dilithium 不在字典中,因此 get 返回 None,然后系统输出 None。如果你预计查询有时候会失败,get 可能比普通的方括号查询更合适,因为错误可能会使程序崩溃。
>>> elements.get('dilithium')
None
>>> elements['dilithium']
KeyError: 'dilithium'
>>> elements.get('kryptonite', 'There\'s no such element!')
"There's no such element!"
在上个示例中,我们指定了一个默认值(字符串 'There\'s no such element!),当键没找到时,get 会返回该值。
恒等运算符
| 关键字 | 运算符 |
|---|---|
is |
检查两边是否恒等 |
is not |
检查两边是否不恒等 |
你可以使用运算符 is 检查某个键是否返回了 None。或者使用 is not 检查是否没有返回 None。
n = elements.get("dilithium")
print(n is None)
print(n is not None)
会输出:
True
False检查是否相等与恒等:== 与 is

定义字典
我们可以如下所示地定义字典:
>>> population = {'Shanghai': 17.8,
'Istanbul': 13.3,
'Karachi': 13.0,
'Mumbai': 12.5}
我选择将每个键值对单独放一行,使这个字典定义更容易读懂,但是是否使用换行符以及在何处使用只是一种样式选择。下面这段代码也可行:
>>> population = {'Shanghai': 17.8, 'Istanbul': 13.3, 'Karachi': 13.0, 'Mumbai': 12.5}复合数据结构
我们可以在其他容器中包含容器,以创建复合数据结构。例如,下面的字典将键映射到也是字典的值!
elements = {"hydrogen": {"number": 1,
"weight": 1.00794,
"symbol": "H"},
"helium": {"number": 2,
"weight": 4.002602,
"symbol": "He"}}
我们可以如下所示地访问这个嵌套字典中的元素。
helium = elements["helium"] # get the helium dictionary
hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight